Как убедиться в правильности работы AI модели, интерпретация которой является делом крайне сложным, а зачастую невыполнимым. Самым простым способом является сравнение предсказаний с прошлыми результатами и определение точек с аномальными прогнозами.
Для такого сопоставления удобно в матрицу признаков добавлять прошлые результаты в ходе первичной обработки, даже если они вам на понадобятся при тренировке или прогнозе модели. В целом на первом шаге целесообразно сформировать большую матрицу, напичканную интересной информацией, а потом исходя из целей дальнейших этапов удалять из нее ненужные столбцы. В результате, имея большой оригинал с причесанными данными, вам вряд ли придется проводить отдельную обработку для поиска внезапно понадобившейся информации.
Для сопоставления результатов со столбцом-ориентиром я пользуюсь простенькой функцией, которая возвращает сомнительные данные:

Данная функция получает на вход датафрейм, имена столбцов для проверки и порог процентного изменения данных, превышение которого расценивается как аномалия.
Для примера сформируем простенькую матрицу с предсказаниями в столбце с именем pred и 5 столбцами с историческими данными target-a:
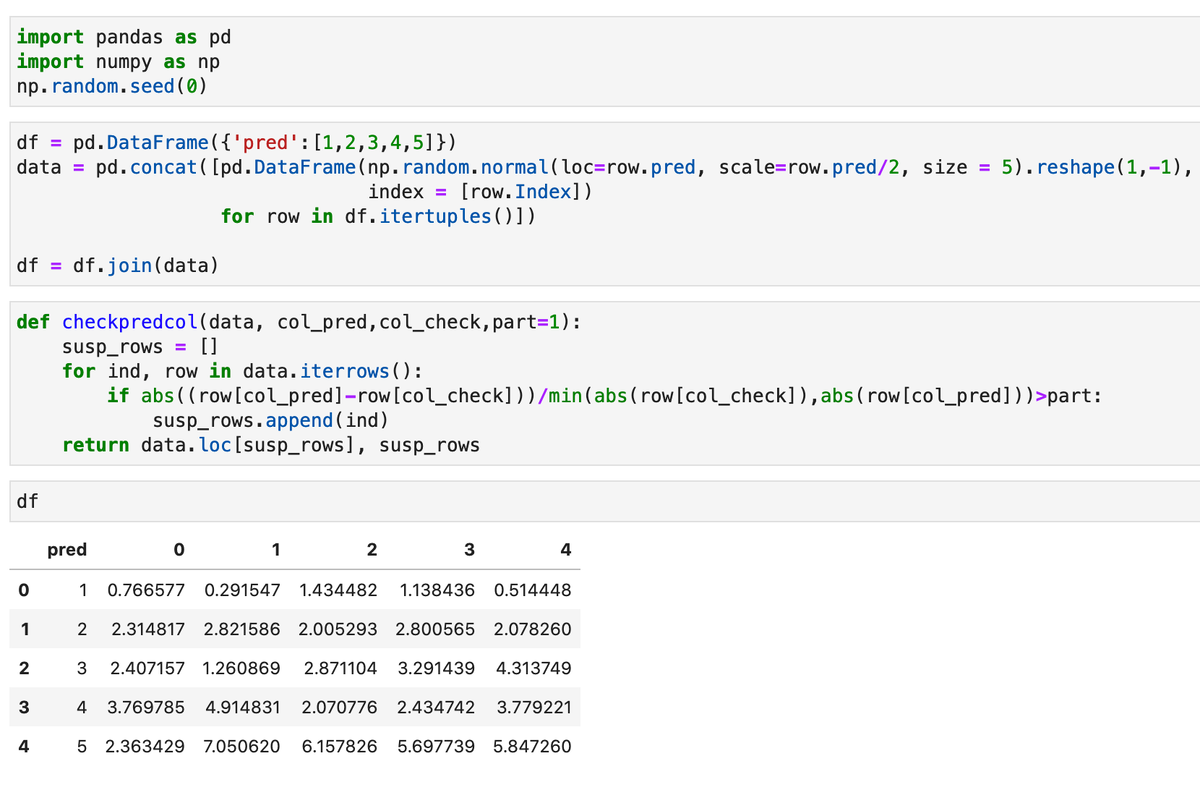
Сравним результаты прогноза со столбцом 0:
Аномальное значение появилось лишь в последней строке.
Следует отметить, что иногда прошлые значения target-а могут быть пропущены или равны нулю (например, в случае предсказаний объемов поставок сразу на квартал), тогда для применения функции, возможно, понадобится сформировать дополнительный столбец среднего и сравнения результатов с ним.
Сгенерируем новый пример и покажем как сформировать такой целевой столбец: