Разнообразие способов итерации по объекту DataFrame в Pandas таит в себе много нюансов, пренебрежение которыми может стать источником ошибок и написания медленного кода.
Так, неприятные сюрпризы можно ожидать от часто упоминаемого способа - метода iterrows объекта DataFrame.
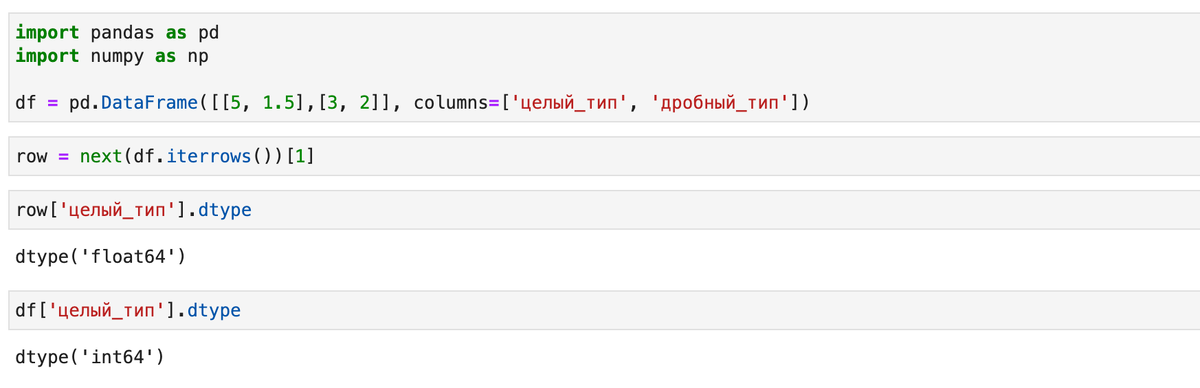
В частности, он не гарантирует сохранение типов объектов. Создадим таблицу с целочисленной и дробной колонками, вернем первую строку и выведем тип первого элемента:
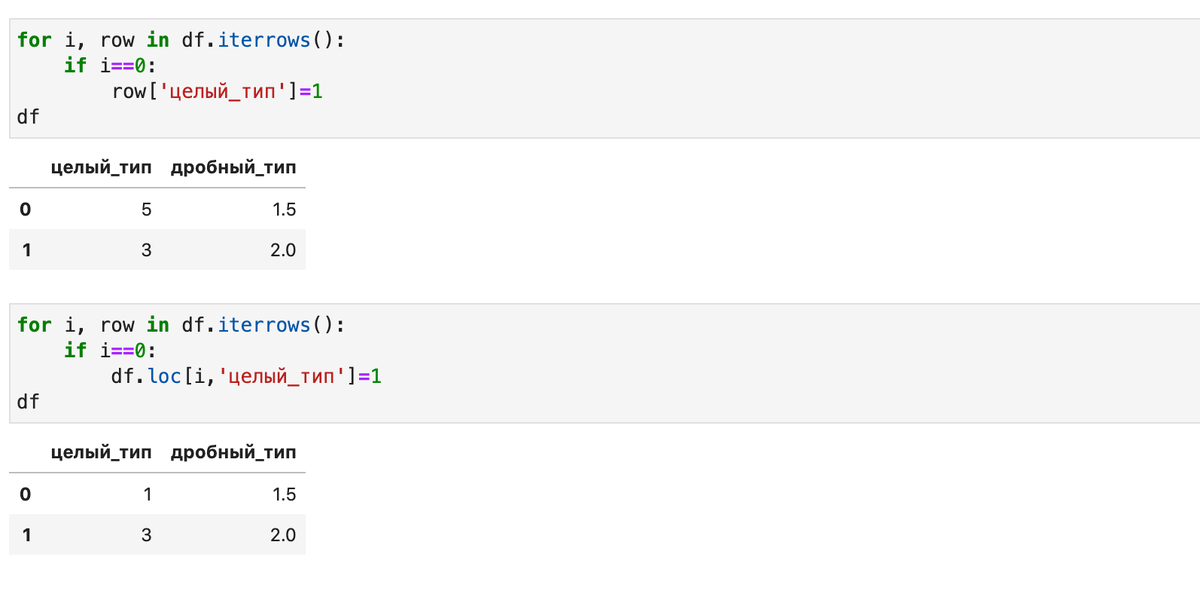
Кроме того, iterrows возвращает копии строк, поэтому их изменение не влечет модификацию строк датафрейма. Лишь обращение непосредственно к самому объекту позволяет добиться цели:
Дополнительным недостатком метода iterrows является длительность работы. Например, создадим большой датафрейм и изменим первые пять строк с выводом затраченного времени:
Взамен разработчики советуют использовать метод itertuples, который быстрее и гарантирует сохранение типов данных. Он возвращает строку не в виде серии, а именного кортежа, к значениям которого можно обратиться, используя точечную нотацию:
Аналогичный перебор строк будет реализован следующим образом:
Как можно заметить, время выполнения снизилось более чем в 60 раз. Также на замену iterrows следует использовать apply, там где данным методом можно обойтись.