
В предыдущей главе был показан пробный вариант автоматического парсинга сайта с последующим импортом данных в базу движка Opencart. Задача этой главы - реализовать в полном объёме взаимодействие Мультипарсера с функциями массового создания и модификации товаров. В качестве наглядного примера будет показана работа с сайтом, имеющим более сложную структуру.
Итак, посмотрим на, сайт berg-air.ru. Первое что бросается в глаза - это обилие товаров с одинаковыми названиями и изображениями. Открыв карточку товара, мы сразу находим этому объяснение.
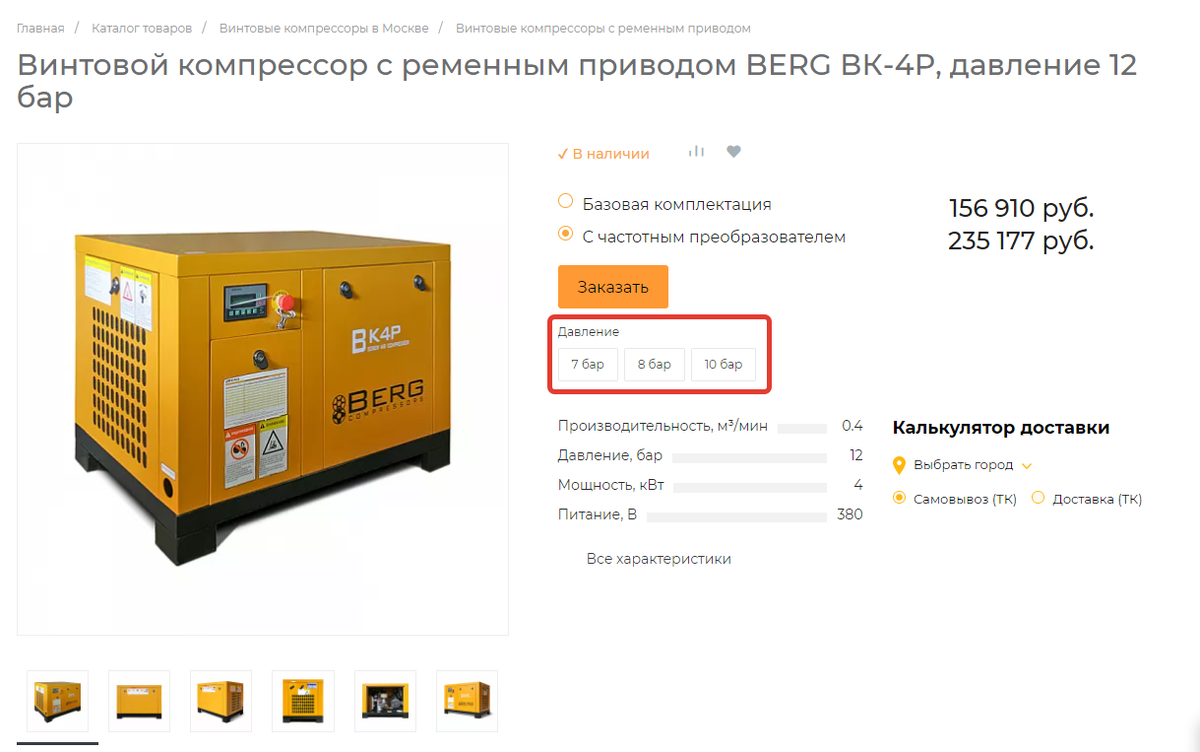
Это действительно данные одного и того же товара, в которых есть отличие только по одному параметру - давлению. В Опенкарте это реализуется с помощью опций. Возможно, что на сайте-доноре это тоже сделано с помощью подобного механизма, а потом номенклатуру и опции объединили в запросе.
Кроме того, мы видим, что у товаров на этом сайте много изображений, что может увеличить время обработки файла импорта при отправке на сервер. Реальный заказчик может ставить конкретную задачу, например, не больше двух-трёх картинок для каждой товарной позиции. Но мне хочется испытать свою программу при больших нагрузках, так что пристегните ремни. Поехали!
Фронт работ
Ещё раз посмотрим на структуру файла импорта-экспорта товаров. Он содержит целых 10 вкладок, включающих информацию не только, о самих товарах, но и о скидках, акциях и спецпредложениях для тех или иных групп покупателей. Удалим не нужные в данный момент вкладки и оставим всего шесть.
- Products - основная информация о товарах
- AdditionalImages - дополнительные фото товара
- ProductOptions - описание опции товара
- ProductOptionValues - значения опций товара
- ProductSEOKeywords - урлы для страниц товаров
Необходимо реализовать механизм, который будет распознавать, является ли текущая позиция новым товаром или это опция уже занесённого в базу товара. В случае, если это новый товар, будут заполняться данные всех перечисленных выше вкладок, а если это опция - только вкладка ProductOptionValues.
Вспомним так же, что в программе была пара "костылей": идентификаторы товаров всегда начинались с тысячи, и начало названия выходного файла прописывалось жёстко в кавычках в одной из функций. Так же были заполнены не все поля на странице основной информации о товаре: не прописывались единицы измерения для массы и габаритов (мелочь, но всё-таки) и, кажется, не указывалась модель товара.
Убираем "костыли"
Пока я просто экспериментировал с распознаванием тэгов на одном-единственном сайте, на проблему нумерации можно было с лёгкостью закрывать глаза. Но всё меняется, когда в нашем поле зрения оказывается множество сайтов, с каждого из которых необходимо запарсить сотни и тысячи строк. Если целочисленные идентификаторы товаров в разных файлах будут совпадать, то всякий раз при импорте предыдущие результаты будут просто затираться, чего ни как нельзя допустить.
Я решил эту проблему с помощью файла конфигурации. Там есть секция дополнительных переменных, в которой я сделал следующую запись.
<add key="identValue" value="1000"/>
Теперь, когда цикл обработки заканчивается, в переменную identValue записывается новое значение с помощью нехитрого кода.
Вот и всё! Теперь только надо помнить, что при каждой компиляции такой счётчик будет возвращаться к первоначальному значению, так что если во время работы над программой у Вас возникла необходимость обработать несколько файлов, не прерывайте процесс тестирования доработкой кода.
Чтобы название файла могло формироваться автоматически, я просто написал функцию, которая ищет в адресе страницы сайта самый правый слеш и берёт всё что написано после.
Если, например, мы парсим сайт с самой примитивной структурой, где список всех товаров располагается на главной странице, то префикс для названия файла будет совпадать с адресом сайта.
Реализация правок центральных модулей
В этой программе информация о товаре при прочтении с сайта-источника помещается в объект класса HtmlTovar. Название товара попадает в этот объект как одна строка, но вообще-то названия техническим средствам, чаще всего, даются по определённым правилам. Так что из названия товара можно получить модель и, например, подгруппу товара. Функция ProcessTovar, которая заполняет объект информацией о товаре, была доработана таким образом, чтобы извлекать информацию о подгруппе, модели и главной опции товара. По умолчанию, функция для получения названия главной опции товара возвращает нулевое значение, так что если для какого-то сайта работа с опциями не предполагается, достаточно просто оставить её без переопределения.
Теперь вернёмся к уже знакомой по предыдущей главе функции DoParsingOfIncomingHtml, которая значительно разрослась. На скриншоте ниже показан лишь самый важный её фрагмент.
Здесь осуществляются вызовы функций, каждая из которых формирует свою часть выходного файла. Класс HtmlParserBase является абстрактным, и конкретные действия должны быть описаны в производном классе. В данном случае был задействован класс OpencartHtmlParserBase, он тоже является абстрактным, но все действия, которые касаются вывода в файл, реализованы именно в нём.
Все эти функции работают с уже известной нам структурой. Эта структура, повторим (если не боитесь), ассоциативный массив списков ассоциативных массивов. И каждая из этих маленьких функций добавляет свой список в большой массив, содержащий товар и все подчинённые ему сущности, для последующего вывода этой информации в файл.
В этом классе так же определены реализации функций весовых и размерных единиц измерения, это сделано, чтобы не приходилось их "тащить" в каждый производный класс. Возвращают они "кг" и "мм", соответственно, однако, как Вы уже поняли, в производных классах их можно переопределять.
Класс BergOpencartHtmlParser
Вот сейчас, при реализации класса для работы с сайтом berg-air.ru, у нас как раз и появится возможность убедится, на сколько гибкой получилась данная система. Несмотря на то, что мы имеем дело с товарами одного и того же типа (компрессорами), и вся информация на сайтах почти одинаковая, кое-какие нестыковки всё же возникают.
В нашей базе производительность указывается в литрах в минуту, а на сайте berg-air.ru производительность указана в кубометрах. Далее, в перечне характеристик нет отдельно длинны, ширины и высоты, есть габариты - три целых числа в одной строке, разделённые крестиками. Наконец, отсутствует параметр "Вид компрессора", и хотя человеку, который зашёл на сайт, это могло бы быть понятно из названия, по идее, всё-таки надо добавить такой атрибут, если, например, мы хотим предоставить возможность фильтровать товары по этому признаку.
Все эти задачи можно решить, перезагрузив функцию GatherAttributesFromTovarObject, на следующем скриншоте показан полный листинг класса BergOpencartHtmlParser.
Здесь вызывается функция GatherAttributesFromTovarObject базового класса, а затем производится дополнительная работа над полученными данными. Во-первых, берём значение первого в списке атрибута (мы знаем, что это Производительность) и умножаем его на тысячу. Во-вторых, берём габариты, получаем из строки список из трёх целых чисел и записываем в данные основного листа в ячейки для размерных параметров. В-третьих, пытаемся найти в названии товара определённую подстроку, и, в случае положительного результата, добавляем к списку атрибутов вид компрессора.
Ещё одна интересная функция, GetVolumeSize, позволяет переопределить максимальное количество товарных позиций в выходном файле. Эта функция определена как виртуальная в базовом классе ParserBase. Её реализация по умолчанию возвращает нуль, то есть объект, создающий файлы отчёта, сам решает, какой размер тома установить. И устанавливает он размер тома 500 товарных позиций. Но поскольку, как уже было сказано, у товаров на этом сайте очень много "тяжёлых" данных, класс парсера для этого сайта устанавливает всего 20 позиций.
Тестирование
Перед импортом, непосредственно, товаров, необходимо создать опцию "Давление", сделать это можно вручную, или тоже импортом файла соответствующей структуры.
Всего с сайта удалось вытащить 144 товарных позиции - это самостоятельных товаров, а ещё у каждого есть несколько модификаций. Это количество было распилено на 8 томов (в каждом до 20 позиций). Все их импортировать я не буду, просто выложу здесь несколько скриншотов, в знак того, что испытания прошли удачно.
В дальнейших статьях планирую рассказать не только о парсинге других сайтов, но и довести до ума свой. Наверное, уже пора натянуть какой-нибудь шаблончик, чтобы с фильтрами, корзиной и всеми делами.
Глава 04 - Карта канала - Глава 06