Можем ли мы визуализировать контекст, используемый для поиска?

Использование трансформаторных моделей для поиска текстовых документов-это потрясающе; в настоящее время это легко реализовать с помощью библиотеки huggingface, и результаты часто очень впечатляют. Недавно мне захотелось понять, почему данный результат был возвращен— мои первоначальные мысли обратились к различным статьям и постам в блогах, связанным с копанием механизмов внимания внутри трансформаторов, что кажется немного запутанным. В этом посте я тестирую очень простой подход, чтобы получить представление о сходстве контекста, обнаруживаемом этими моделями при выполнении контекстного поиска с помощью простой векторной математики. Давайте попробуем.
Для этойцели я буду использовать модель из sentence-transformersбиблиотеки, которая была специально оптимизирована для выполнения поиска семантического текстового сходства. Модель по существу создает 1024-мерное вложение для каждого переданного ей предложения, и сходство между двумя такими предложениями может быть вычислено по косинусному сходству между соответствующими двумя векторами. Скажем , у нас есть два вопроса A и B, которые встраиваются в 1024-мерные векторы A и Bсоответственно, тогда косинусное сходство между предложениями вычисляется следующим образом:
то есть косинусное сходство 1 означает, что вопросы идентичны (угол равен 0), а косинусное сходство -1 означает, что вопросы очень разные. В целях демонстрации я внедрил набор из 1700 вопросов из набора данных классификации вопросов ARC. Полный блокнот можно найти в google colab здесь. Существенную часть выполнения вложений предложений можно увидеть в следующем фрагменте:
from transformers import AutoTokenizer, AutoModel def mean_pooling(model_output, attention_mask): """ Mean pooling to get sentence embeddings. See: https://huggingface.co/sentence-transformers/paraphrase-distilroberta-base-v1 """ token_embeddings = model_output[0] input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float() sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1) # Sum columns sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9) return sum_embeddings / sum_mask # Fetch the model & tokenizer from transformers librarymodel_name = 'sentence-transformers/stsb-roberta-large'model = AutoModel.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name) # Tokenize inputencoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=512, return_tensors="pt") # Create word embeddingsmodel_output = model(**encoded_input) # Pool to get sentence embeddings; i.e. generate one 1024 vector for the entire sentencesentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask']).detach().numpy()
С помощью этого мы можем легко выполнять поиск в нашей базе данных вопросов; скажем, у нас есть база данных из 1700 вопросов, которую мы встроили в матрицу 1700×1024, используя приведенный выше фрагмент. Первым шагом было бы нормализовать L2 каждую строку — это, по сути, означает, что мы нормализуем каждый вектор вопроса так, чтобы он имел длину 1, что упрощает наше предыдущее уравнение таким образом, что косинусное сходство между A и B это просто точечное произведение двух векторов. После вложений, созданных в предыдущем фрагменте, мы можем сделать вид, что первый вопрос в нашем наборе данных является нашим запросом, и попытаться найти наиболее близкую совпадающую запись из остальных вопросов:
import numpy as npfrom sklearn.preprocessing import normalize # Use the first question as the queryQUERY_ID = 0 # Noralize the datanorm_data = normalize(sentence_embeddings, norm='l2') # Calculate scores as dot product between all embedding & queryscores = np.dot(norm_data, norm_data[QUERY_ID].T) # The best match is the entry with the second highest score (the highest is the query itself)MATCH_ID = np.argsort(scores)[-2]
В моем образце набора данных первым вопросом (запросом) был “Какой фактор, скорее всего, вызовет у человека лихорадку?” и выявленный самый похожий вопрос был “Что лучше всего объясняет, почему у человека, зараженного бактериями, может быть лихорадка?”. Это довольно хорошее совпадение " — оба предложения относятся к человеку, у которого развивается лихорадка. Однако откуда мы знаем, что причина, по которой алгоритм выбрал именно это совпадение, заключалась не только в том, что они оба начинаются со слова “Который”?
Следует помнить, что по своей конструкции трансформаторные модели фактически выводят 1024-мерный вектор для каждого токена в наших предложениях — эти вложения токенов объединяются в среднее значение для генерации наших вложений предложений. Таким образом, чтобы получить больше информации о контексте, используемом для поиска совпадения в нашем поисковом запросе, мы могли бы вычислить косинусное расстояние между каждым токеном в нашем запросе и нашим поисковым совпадением и построить результирующую 2D-матрицу:
# For each sentence, store a list of token embeddings; i.e. a 1024-dimensional vector for each tokenfor i, sentence in enumerate(valid_sentences): tokens = tokenizer.convert_ids_to_tokens(encoded_input['input_ids'][i]) embeddings = model_output[0][i] token_embeddings.append( [{"token": token, "embedding": embedding.detach().numpy()} for token, embedding in zip(tokens, embeddings)] ) def get_token_embeddings(embeddings_word): """Returns a list of tokens and list of embeddings""" tokens, embeddings = [], [] for word in embeddings_word: if word['token'] not in ['<s>', '<pad>', '</pad>', '</s>']: tokens.append(word['token'].replace('Ġ', ")) embeddings.append(word['embedding']) norm_embeddings = normalize(embeddings, norm='l2') return tokens, norm_embeddings # Get tokens & token embeddings for both query & search matchquery_tokens, query_token_embeddings = get_word_scores(token_embeddings[QUERY_ID])match_tokens, match_token_embeddings = get_word_scores(token_embeddings[MATCH_ID] # Calculate cosine between all token embeddingsattention = (query_word_embeddings @ match_word_embeddings.T) # Plot the attention matrix with the tokens on x and y axesplot_attention(match_tokens, query_tokens, attention)
Что приводит к следующему сюжету:
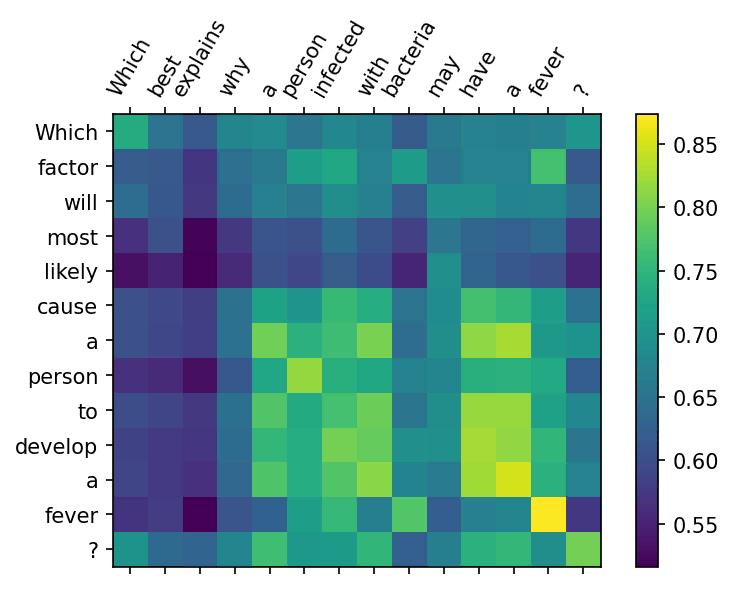
Теперь мы можем видеть косинусное сходство между каждым токеном в запросе и каждым токеном в лучшем результате поиска. Ясно, что действительно ключевое слово “лихорадка” подобрано и является основной частью “семантического контекста”, который привел к результату поиска, — однако также ясно, что есть дополнительные компоненты, входящие в семантический контекст, например “развивать” и “иметь” сочетаются с высокой оценкой косинусного сходства, и ключевое слово “человек” также подобрано, в то время как начальное слово “который”, присутствующее в обоих предложениях, менее важно.
Этот простой метод вычисления косинусного сходства между всеми вложениями токенов дает представление о вкладе каждого токена в итоговую оценку сходства и, таким образом, является быстрым способом объяснить, что делает модель, когда она возвращает данный результат поиска. Следует отметить, что при выполнении фактического поиска мы берем среднее значение всех вложений токенов до вычисления косинусного сходства между различными вложениями предложений, которое отличается от того, что мы делаем здесь — даже если это так, то, видя, как каждое вложение токенов из запроса выравнивается по вложениям токенов в лучшем совпадении, дает представление о том, что составляет эти вложения предложений, используемые для семантического поиска.