В этой статье мы рассмотрим регрессию Softmax, которая используется для задач классификации нескольких классов, и реализуем ее в наборе данных рукописного распознавания цифр MNIST.
Сначала мы будем опираться на логистическую регрессию, чтобы понять функцию Softmax, затем мы рассмотрим Cross-entropy loss, one-hot encoding (однократное кодирование) и закодируем их вместе. Наконец, мы закодируем обучающую функцию (fit), увидим нашу точность и построим наши прогнозы.
В работе нам потребуются NumPy и Matplotlib. Мы увидим, как с помощью Softmax добиться точности в 91% для данных обучения и тестовой выборки.
Кратко про логистическую регрессию
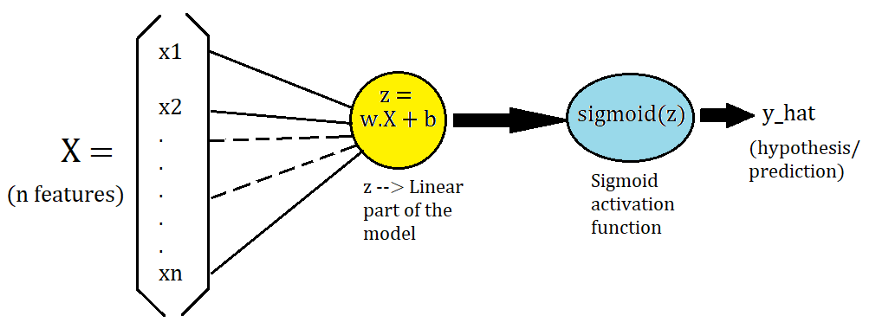
В модели логистической регрессии мы берем вектор x (который представляет только один пример из m) размера n(функций), берем скалярное произведение с весами и добавляем смещение. Мы назовем это z(линейная часть), которая есть w.X + b. После этого мы применяем функцию активации, которая является сигмоидной для расчета логистической регрессии y_hat.
y_hat = sigmoid(z) = sigmoid(w.X + b)
Каждое ребро, идущее от X к линейной части, представляет собой вес, а каждая окружность линейной части имеет точку .
Логистическая регрессия используется для двоичной классификации. Это означает, что существует 2 класса ( 0 или 1 ), и из-за сигмоидной функции мы получаем результат (y_hat) между 0 и 1. Мы интерпретируем этот результат ( y_hat) логистической модели как вероятность того, что y = 1. Тогда вероятность того, что y = 0, становится (1-y_hat).
Softmax Regression
Softmax Regression - это форма логистической регрессии, которая нормализует входное значение в вектор значений, который следует распределению вероятности, общая сумма которого равна 1.
Выходные значения находятся в диапазоне [0,1], что хорошо, потому что мы можем чтобы избежать двоичной классификации и учесть как можно больше классов или измерений в нашей модели нейронной сети. Вот почему softmax иногда называют полиномиальной логистической регрессией.
Кроме того, другое название для Softmax Regression - Классификатор максимальной энтропии (MaxEnt).
Давайте для наглядности поставим конкретную цель. Например, научить модель определять цифру на изображении.
Возьмем для этого рукописный набор данных MNIST и используем его в Softmax Regression. Набор имеет 10 классов, каждый из которых представляет собой цифру от 0 до 9 . Давайте сначала посмотрим на датасет.
Загружаем набор данных MNIST из keras.datasets, построим график и разделим обучающие и тестовые данные. Он содержит 60 000 примеров в обучающем наборе и 10 000 примеров в тестовом наборе.
Loading:
Plotting:

Наши данные содержат изображения цифр и метки, обозначающие, какая это цифра. Все они имеют оттенки серого в месте контура и размер 28x28 пикселей.
Первый вопрос, на который нам нужно ответить: - как использовать изображения в качестве входных данных?
Каждую картинку можно представить в виде трехмерной матрицы. Если у нас есть цветное изображение размером 28x28, то у нас есть и числа (28 x 28 x 3) для представления этого изображения (3 для канала RGB). Однако у нас остаются серые пиксели, а значит каждое изображение имеет только 1 канал.
Чтобы ввести изображение в модель, мы сведем его 28x28 в вектор длиной 784 (28 * 28). Эти числа представляют n функции для каждого примера (изображения) в наборе данных.
X_train - это матрица с 60 000 строками и 784 столбцами.
m = 60,000; n = 784
One-hot Encoding
Теперь наш вектор y выглядит так:
train_y
>> array ([5, 0, 4, ..., 5, 6, 8], dtype = uint8)
Это массив NumPy с метками. Мы не можем использовать его для нашей модели, пока не преобразуем его в нули и единицы. Это и есть one-hot encoding или горячее кодирование. Оно позволяет нам преобразовать категориальные данные в числовые. Мы хотим, чтобы наш y выглядел как матрица размером 60 000 x 10. Вот так:
Строки представляют пример, а столбцы сообщает нам метку. Например, в первом примере есть 1 в пятом столбце, а всё остальное - 0. Итак, метка для первого примера - 5, и аналогично для других. Для каждого примера будет только один столбец с 1.0, а остальные будут нули.
Давайте закодируем функцию для горячего кодирования наших меток -
c = Количество классов
Reference — Multi-dimensional indexing in NumPy
Функция Softmax
При выполнении мультиклассовой классификации с использованием Softmax Regression у нас есть ограничение: наша модель предсказывает только один класс среди "с" классов. Для наших данных это означает, что модель предсказывает, что на изображении будет только одна из цифр (от 0 до 9).
Мы интерпретировали результат логистической модели как вероятность. Точно так же мы хотим интерпретировать выходные данные модели многоклассовой классификации как распределение вероятностей. Итак, мы хотим, чтобы наша модель выводила вектор размера "c" с каждым значением в векторе, представляющим вероятность каждого класса.
Другими словами, "с" значение в векторе представляет вероятность того, что наше предсказание будет "с" классом. Поскольку все они являются вероятностями, их сумма будет равна 1.
Softmax для "с" класса определяется как - 1
где, z - линейная часть. Например, z1 = w1.X + b1 и аналогично для других.
y_hat = softmax (wX + b)
c (количество классов) = 10 для наших данных.
Давайте попробуем разобраться в функции Softmax и Softmax Regression с помощью приведенной ниже диаграммы модели.
- Мы свернули наше изображение 28x28 в вектор длиной 784 ( x на изображении выше).
- Мы вычисляем линейную часть для каждого класса → zc = wc.X + bc, где, zc - линейная часть "с" класса, wc - набор весов "с" класса, а bc - смещение для "с" класса.
- Мы рассчитываем softmax zc для каждого класса, используя приведенную выше формулу. Объединив все классы, мы получим вектор размера "c" и их сумма равна 1. Какой класс имеет наибольшее значение (вероятность), тот и будет нашим предсказанием.
Обратите внимание, что у каждого класса разный набор весов и разное смещение. К тому же в приведенной выше диаграмме "x" показан только в качестве одного примера.
Каждый zc является матрицей (1,1). Но поскольку у нас есть m примеры, мы будем представлять zc как вектор размера m. Теперь, чтобы объединить все "z" классы , мы сложим их и получим матрицу размера (m, c).
Точно так же для каждого класса набор весов представляет собой вектор размера n. Итак, чтобы объединить все классы, мы сложим их, что даст нам матрицу размера ( n, c). Кроме того, у нас есть одно смещение для каждого класса. Объединенные смещения будут вектором размера "c".
Объединение всех классов для softmax дает вектор размера "c", а объединение всех "m" примеров дает матрицу размера ( m, c).
Shapes —
- X →(m,n)
- y →(m,c) [one hot encoded]
- w →(n,c)
- b →vector of size c
Напишем код для функции softmax:
Cross-Entropy Loss
Для каждого алгоритма параметрического машинного обучения нам нужна функция потерь, которую нужно минимизировать (найти глобальный минимум), чтобы определить оптимальные параметры ( "w" и "b"), которые помогут нам делать наилучшие прогнозы.
Для регрессии softmax мы используем потерю кросс-энтропии (Cross-Entropy) -
В коде Loss выглядит так:
Обратите внимание, что функция потерь не закодирована в One-hot Encoding
Обучение
- Инициализируйте параметры - w и b.
- Найдите оптимальныеx w и b с помощью градиентного спуска.
- Используйте, softmax (w.X + b), чтобы предсказывать.
Обучение на датасете MNIST
Мы видим, что потери уменьшаются после каждой итерации. Значит мы всё делаем правильно.
Прогнозирование
Measuring Accuracy
def accuracy(y, y_hat):
return np.sum(y==y_hat)/len(y)
Давайте посчитаем точность нашей модели на обучающем и тестовом наборе.
Точность нашей модели на обучающем наборе - 91,8%, а на тестовом - 91,7% . Результат вполне удовлетворительный.
Построение прогнозов
На приведенном выше рисунке показаны прогнозы модели для 40 примеров в обучающей выборке. Мы видим, что некоторые из них ошибочно предсказаны. Например, обведенный красным в нижнем ряду.
В целом же нам удалось применить регрессию Softmax для задач мультиклассовой классификации. Мы надеемся, что статья была полезна для вас и вы сможете применить полученные знания в своих работах.
Другие наши статьи: