С каждым годом функция распознавания лиц находит новые применения. Разблокировка телефона, верификация платежей, всевозможные аналоги deepfake и, конечно, маски в Instagram. Чем точнее и лучше настроены алгоритмы, тем более качественным будет и конечный результат.
Одним из важнейших компонентов такой модели является функция выравнивания. Она определяет ключевые точки на лице человека и маркирует их. Они становятся своего рода опорными точками при считывание, когда человек поворачивает голову или меняется перспектива съемки.
Перспективное решение в этой области смогли предложить сотрудники Центра машинного зрения и анализа сигналов Университета Оулу. Их исследование было опубликовано в Journal of Real Time Image Processing (Springer), и мы предлагаем ознакомиться, с описанными в ней методами.

General Training eXtensions (GTX)
Именно так называется совокупность описанных в статье правил и рекомендация для построения оптимальной стратегии обучения. С их помощью исследователи смогли добиться значительного прироста производительности и оптимизации многих используемых моделей.
Результаты экспериментов показывают, что модели, созданные с использованием предлагаемых нами методов, быстрее, меньше по размеру, точнее, надежнее в конкретных сложных условиях и более плавные в системах отслеживания...
Ниже мы оставим официальное видео, с помощью которого вы сможете оценить метод в действии.
Альтернативные способы выравнивания лиц
Чтобы оценить практическую пользу и точность, мы сравним метод с другими известными способами выравнивания лиц, которые считаются самыми передовыми:
- LBF (Local Binary Features) в OpenCV ,
- ERT (Ensemble of Regression Trees) в Dlib
- DAN (Deep Alignment Network)
Методы LBF и ERT известные как методы быстрого выравнивания лиц, основаны на каскадах регрессоров, а алгоритм DAN основан на подходе глубокого обучения. Мы используем 68 ориентиров, определенных схемой Multi-PIE Landmarks.
Метрики оценки и контрольные показатели
Стандартные показатели для выравнивания лиц обычно включают в себя те, которые связаны с качеством прогнозов по сравнению с аннотациями основной истины. Следовательно, мы должны обращать внимание на точность, погрешность, а в некоторых случаях - частоту отказов и вычислительную эффективность. Последнее измеряется в миллисекундах на лицо, и количество обрабатываемых кадров в секунду (fps).
Проблема в том, что эти показатели не измеряют несколько явлений, наблюдаемых в большинстве моделей выравнивания лиц. А именно
- Дрожание: межкадровый шум и небольшие тряска. Этот эффект может быть вызван отсутствием обучающих выборок, неточными аннотациями с высокой дисперсией, некачественными наборами данных или недетерминированными методами вывода, которые используют какую-то (псевдо) случайную информацию, например, на этапе инициализации.
- Face Alignment Sensitivity: большинство алгоритмов выравнивания лица полагаются на ограничивающую рамку обнаружения лица для инициализации формы. Детекторы лиц не всегда совпадают в последовательных кадрах. Кроме того, большинство моделей выравнивания лиц обучаются с помощью прямоугольного выделения одного детектора лиц.
Основываясь на этих явлениях, мы определяем три новых показателя и используем их для оценки производительности модели при отслеживании:
- Landmarks Mean Squared Displacement - метрика среднеквадратичного смещения ориентиров (laMSD), вычисляет, как ориентиры перемещаются по видео со статическим лицом.
- Normalized Jitter Sensitivity Mean Square Error -Нормализованная среднеквадратическая ошибка чувствительности к тряске (NJS-MSE_σ ² ) - это показатель, вычисляемый путем определения ориентиров лица на наборе эталонных изображений с использованием случайных вариаций прямоугольника лица на основе небольших смещений центра по горизонтальной и вертикальной оси. Результатом измерения ошибки является метрика оценки для сравнения устойчивости к дрожанию модели выравнивания лиц.
- Normalized Face Detection Sensitivity Mean Square Error - нормализованная среднеквадратическая ошибка чувствительности обнаружения лица (NFDS-MSE_σ ² ). Для этого показателя случайные вариации основаны на смещении центра прямоугольника лица по горизонтальной и вертикальной оси. Также учитываются случайные изменения размера (ширины и высоты) ограничивающего прямоугольника выделения лица. Эта метрика позволит оценить надежность нашей модели выравнивания при работе с различными детекторами.
Тестирование разных методов
Чтобы оценить все модели, мы тестируем их в сочетании хорошо зарекомендовавших себя стандартных испытаний и уникальными авторскими тестами. Большинство из них связаны с эффективностью и точностью. Это позволит сделать более объективные выводы и изучить поведения методов в приложениях, использующих определение лиц в реальном времени.
1. Common In-the-Wild benchmarks, чтобы проверить общую точность и погрешность в качестве эталона для сравнения с другими моделями.
2. Jittering benchmarks, чтобы определить изменения точности при колебаниях лиц в момент определения.
3. Jittering benchmarks. Тесты моделей в определенных условиях.
Нюансы обучения
Чтобы добиться максимального качества определения лиц, исследователи предлагают учитывать несколько важных правил в процессе обучения:
- Увеличение данных на основе манипуляций с изображениями: геометрических и цветовых преобразований.
- Увеличение данных на основе статистических манипуляций: нормализация изображений, добавление шумом, разные варианты инициализации, удаление выбросов.
- Добавление данных для конкретной области: изображения аннотируются с использованием медленной и точной модели и
архитектуры учителя и ученика.
Параллелизация
В статье был описан набор методов, начиная с последовательной оптимизации и заканчивая стратегиями параллелизации. Решения анализируются с точки зрения производительности и возможных компромиссов в отношении точности.
Чтобы протестировать описанные способы оптимизации, была создана собственная версия метода LBF на языке C++. Следовательно, мы можем сравнить его с готовым решением OpenCV и предпринять другие меры по оптимизации в версиях реализации OpenCV и Dlib.
В обучении, в основном, мы ускоряем циклы, где топология алгоритма позволяет это сделать, используя OpenMP. Точнее, мы ускоряем изучение функций отображения локальных объектов в алгоритме LBF, поскольку каждый ориентир независим от остальных.
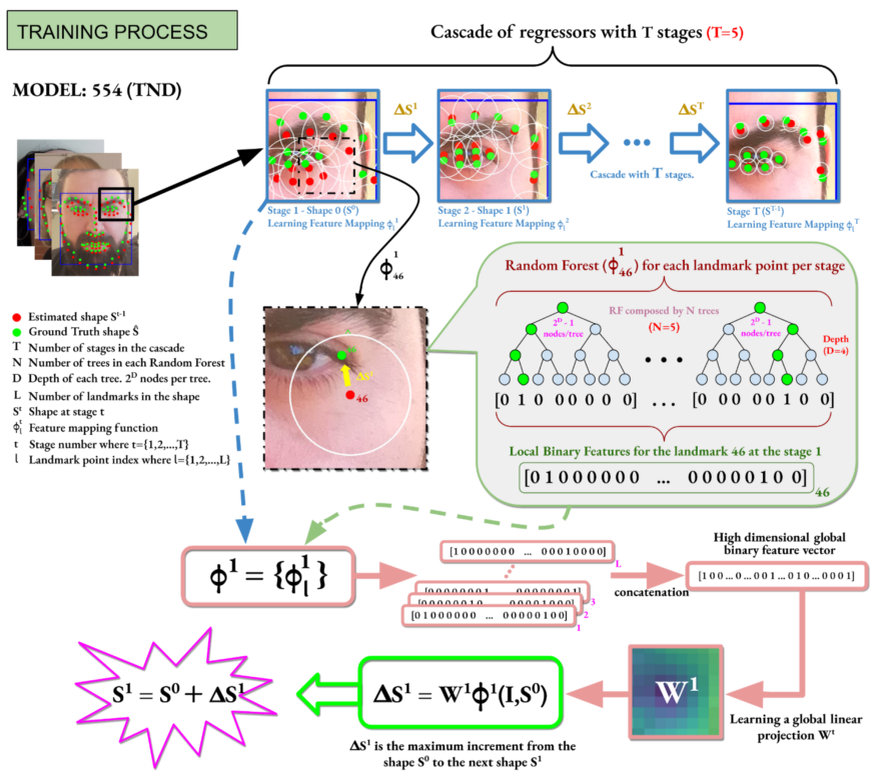
После обучения наших моделей выравнивания лица мы ускоряем вывод, применяя в основном три стратегии:
- Распараллеливание вычислений для каждого ориентира (функции отображения локальных признаков).
- Ускорение умножения высокоразмерных признаков, извлеченных в вышеупомянутом процессе, и глобальной линейной регрессии или матрицы переноса W. Мы применяем три различных метода оптимизации, как показано на рисунке 2.
- Квантование сгенерированных моделей. Мы преобразуем данные наших моделей из плавающих в короткие целые числа. Это увеличивает скорость вывода, особенно на устройствах с ограничениями кэша и мобильных устройствах.
Сравнительная оценка
Мы эмпирически оцениваем и анализируем влияние стратегий обучения и методов оптимизации реализации в конечных моделях с точки зрения ошибок, размера модели, времени вычислений и производительности в режиме отслеживания и сложных сценариях. В результате стратегий обучения GTX мы получили набор усиленных моделей, обозначенных как модели LBF_gtx, которые будут сравниваться с моделями LBF_base и другими дополнительными моделями.
Сравнение точности, размера и скорости:
Средняя ошибка (%) и неудачные изображения (%) в полнофункциональном тесте 300W. В центральном столбце - размер каждой модели указан в мегабайтах (МБ). В последнем столбце указано среднее время вычислений в этом тесте в миллисекундах на каждое лицо.
В оцененных моделях LBF «q» означает квантованные модели, а «float» - необработанные модели, все они уже интегрированы в наш конвейер C ++.
Модель DAN - это исходная модель, представленная в оригинальном документе. А модель ERT используется через библиотеку Dlib, сравнивая модель, предоставленную библиотекой, и нашу собственную обучающую модель ERT.
Модели OpenCV LBF используются через библиотеку OpenCV. Индексы 1,2,3 и 4 указывают на то, что модель OpenCV по умолчанию используется с различными детекторами лиц, включая встроенный детектор лиц HaarCascade и детектор лиц DNN.
Оценка тряски в Jitter benchmark:
Total jitter and jitter per frame - в собственном тесте Jittering, упорядоченная по возрастанию laMSD на кадр. Вывод был сделан с использованием портативного компьютера с процессором Intel Core ™ i7 с тактовой частотой 2,6 ГГц. Исследовательские модели LBF являются плавающей версией для честного сравнения с моделью OpenCV.
Domain-specific benchmark
Средняя ошибка (%) и неудачные изображения (%) на подмножествах 300W-полного набора и предметно-ориентированного тестирования после обучения базовых моделей с использованием немаркированных данных для предметной области и схемы учитель-ученик .
Влияние квантования модели:
Сравнение качества конечных результатов
Чтобы увидеть влияние предложенных стратегий обучения и оптимизации реализации, достаточно посмотреть на их визуализацию в этих видео.
Результаты этого исследования показывают влияние набора стратегий оптимизации и обучения в контексте системы выравнивания лиц. Предпринятые меры упрощают последующую интеграцию модели для задач по определению лиц в режиме реального времени на настольных компьютерах и мобильных устройствах.
Загрузите код, модели, наборы данных тестов и примеры видео из репозитория GitLab. Модели, созданные в статье, теперь являются стандартными в репозитории моделей библиотеки Dlib. Задействованные компоненты:
- Модели LBF_gtx и ERT_gtx: Здесь
- Исходная и стандартная модель Dlib ERT: Модель Dlib ERT



















