Как быстро сконструировать исторические признаки для модели и не допустить ошибку. Рассмотрим два способа.
На самом деле об одном из них я уже рассказывал ранее. Он заключается в объединении таблицы с ее же копией, сдвинутой на заданное количество периодов. Данная логика реализована в функции get_shift_data. Также написан ее более продвинутый аналог get_shift_data_tilln, возвращающий все признаки раньше заданного (читай здесь).
Другим способом является использование метода shift библиотеки Pandas. Рассмотрим игрушечный набор о заработках людей по месяцам (код для генерации представлен в конце статьи):
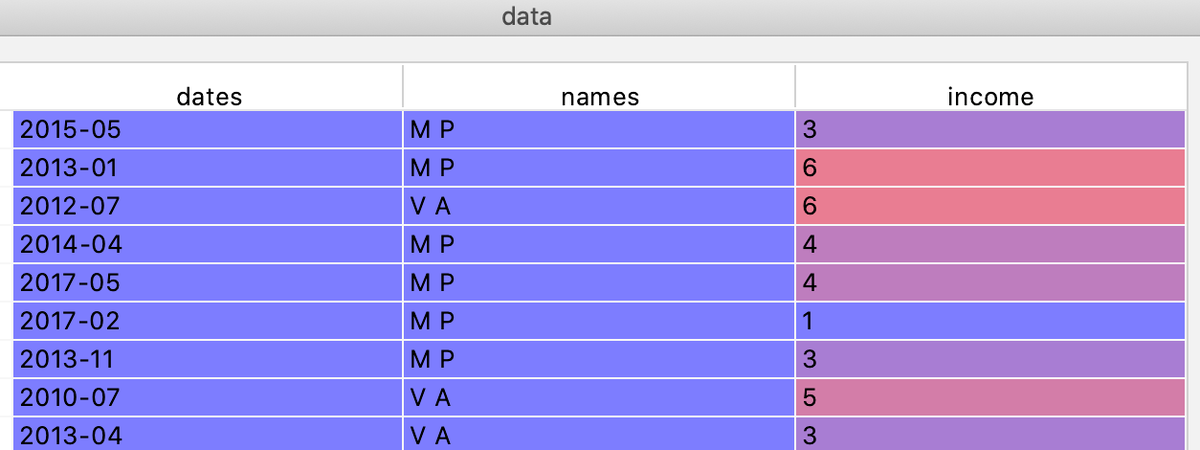
Рассмотренным ранее способом для получения матрицы с текущим и за три прошлых месяцев доходами можно было получить с помощью следующего кода:

Отобразим результаты для человека с инициалами "V A":
DataFrame va_ch содержит первоначальные данные, из которых часть в результирующую таблицу не попала, так как не содержит сведения обо всех прошлых периодах:
Для устранения потери данных в df_hist следует дополнить исходную таблицу data пропущенных периодов, как указывалось в статье.
Для получения аналогичных результатов с применением shift следует отсортировать данные, так как функция не проверяет упорядоченность по времени данных, а просто сдвигает заданный столбец (на место отсутствующих полей либо ставит nan, либо заданное значение). При этом есть возможность сдвигать по группам, так как нас интересуют доходы разных людей:
Данные разнятся по сравнению с прошлыми результатами, так как в первом случае проверялась непрерывность значений, а во втором - нет (например, для записи с датой 2011-04 в качестве прошлых месяцев фигурируют месяцы из 2010 года).
Поэтому дополнительно потребуется заполнить пропущенные значения времени (подробнее в статье):
Если теперь опять вызвать код из позапрошлого блока, получим:
Теперь две таблицы дают одинаковый результат. Ниже представлен код для генерации использованного в статье набора данных:



















