Рассмотрим простой способ поиска закономерностей между двумя последовательностями. Его применение значительно упростит качественную обработку данных и позволит не потерять время на неэффективные промежуточные решения.
Для наглядности будем работать с игрушечными данными о заработке людей из разных городов (идентифицируются по индексу) и суммы помощи им из местного бюджета следующего вида (код для генерации приведен в конце статьи):
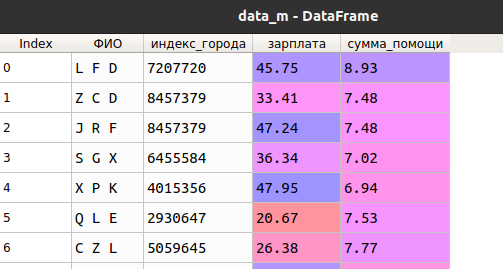
Допустим, при обработке значений мы опираемся на гипотезу об однозначном определении человека по ФИО. Для проверки этого можно воспользоваться методом duplicated:
data_m[data_m.duplicated(subset=['ФИО'])]
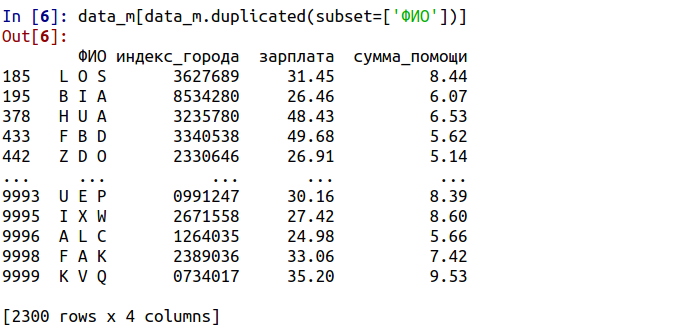
В результате, получены 2300 строк, которые являются повторными для уже имеющихся, при это соответствующие им пары не включены. Для вывода всех значений можно задать параметр keep=False (по умолчанию первое значение из цепочки повторов как дубликат не помечается):
Вот в такой ситуации нас может интересовать, каким городам соответствует один и тот же человек. То есть устанавливаем соотношение один ко многим. Это можно осуществить очевидным способом, выбирая дублирующие строки для одного значения и устанавливая соответствие с этими номерами строк в другой последовательности, где значения не являются повторными. Однако еще проще осуществить группировку с помощью следующей функции:
Она получает датафрейм, столбец для группировки, имя которое ему присваивается и имя столбца с множеством значений. Внутри нее реализована функция, отбирающая строки, в которых встречается больше одного значения второй последовательности, соответствующего конкретному значению первой. Вызовем функцию для нашего примера:
fio_town = general_modules.df_check_info.get_diffs_one_many( data_m, data_m['ФИО'],'ФИО', 'индекс_города')
Можно эту же функцию использовать и для определения обратного соотношения - "город - люди".
Дополнительную пользу функция get_diffs_one_many может принести при проверке качества разметки некого поля. Например, вы сформировали критерий разметки, разметили, а затем выводите список различных значений поля соответствующих одному и тому же имени.
Код для генерации использованного выше набора приведен ниже: