
Последовательное выполнение задач - не лучшая идея. Если входные данные второй задачи не являются выходными данными первой задачи, вы тратите время и процессор.
Как вы, вероятно, знаете, механизм Python Global Interpreter Lock (GIL) позволяет только одному потоку одновременно выполнять байт-код Python. Это серьезное ограничение, которого можно избежать, изменив интерпретатор Python или реализовав методы параллелизма на основе процессов.
Сегодня вы узнаете, как выполнять задачи параллельно с Python с помощью библиотеки concurrent.futures. Вы поймете эту концепцию на практическом примере - получение данных из нескольких конечных точек API.
Статья построена следующим образом:
Описание проблемы
Тест: последовательное выполнение задач
Тест: параллельное выполнение задач
Заключение
Вы можете скачать исходный код этой статьи здесь.
Описание проблемы
Цель состоит в том, чтобы подключиться к jsonplaceholder.typicode.com - бесплатному поддельному REST API.
Вы подключитесь к нескольким конечным точкам и получите данные в формате JSON. Всего будет шесть конечных точек. Не очень много, и Python, скорее всего, выполнит задачу за секунду или около того. Не слишком хорош для демонстрации возможностей многопроцессорной обработки, поэтому мы немного оживим.
Помимо получения данных API, программа также будет спать на секунду между выполнением запросов. Поскольку существует шесть конечных точек, программа не должна ничего делать в течение шести секунд - но только тогда, когда вызовы выполняются последовательно.
Давайте сначала проверим время выполнения без параллелизма.
Тест: последовательное выполнение задач
Давайте посмотрим на весь сценарий и разберем его:
import time
import requests
URLS = [
'https://jsonplaceholder.typicode.com/posts',
'https://jsonplaceholder.typicode.com/comments',
'https://jsonplaceholder.typicode.com/albums',
'https://jsonplaceholder.typicode.com/photos',
'https://jsonplaceholder.typicode.com/todos',
'https://jsonplaceholder.typicode.com/users'
]
def fetch_single(url: str) -> None:
print(f'Fetching: {url}...')
requests.get(url)
time.sleep(1)
print(f'Fetched {url}!')
if __name__ == '__main__':
time_start = time.time()
for url in URLS:
fetch_single(url)
time_end = time.time()
print(f'\nAll done! Took {round(time_end - time_start, 2)} seconds')
В переменной URLS хранится список конечных точек API. Вы получите данные оттуда. Под ним вы найдете функцию fetch_single (). Он отправляет GET-запрос на конкретный URL-адрес и на секунду засыпает. Он также распечатывается, когда загрузка началась и закончилась.
Сценарий принимает к сведению время начала и окончания и вычитает их, чтобы получить общее время выполнения. Функция fetch_single () вызывается для каждого URL из переменной URLS.
После запуска этого скрипта вы получите следующий вывод в консоли:
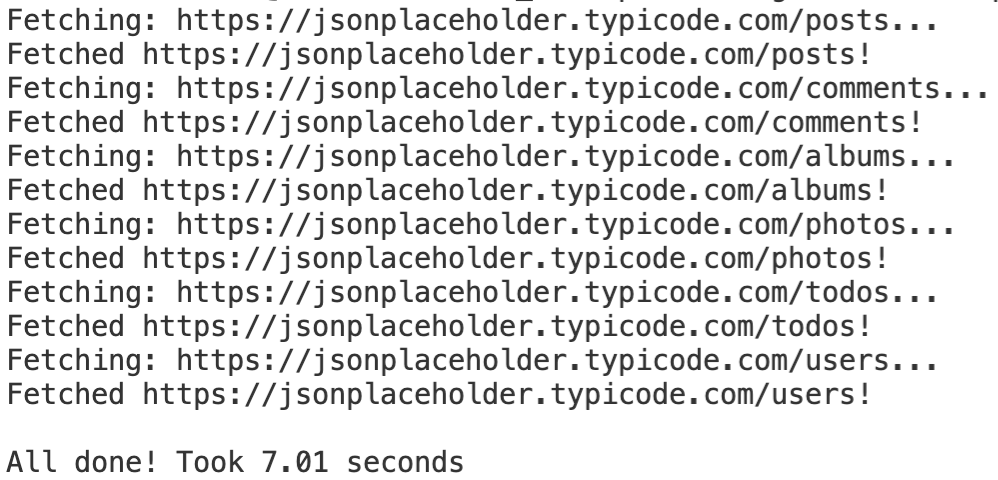
Вкратце, это последовательное выполнение. Скрипт на моей машине завершился примерно за 7 секунд. Скорее всего, вы получите почти одинаковые результаты.
Давайте посмотрим, как сократить время выполнения с помощью параллелизма.
Тест: параллельное выполнение задач
Давайте посмотрим на сценарий, чтобы увидеть, что изменилось:
import time
import requests
import concurrent.futures
URLS = [
'https://jsonplaceholder.typicode.com/posts',
'https://jsonplaceholder.typicode.com/comments',
'https://jsonplaceholder.typicode.com/albums',
'https://jsonplaceholder.typicode.com/photos',
'https://jsonplaceholder.typicode.com/todos',
'https://jsonplaceholder.typicode.com/users'
]
def fetch_single(url: str) -> None:
print(f'Fetching: {url}...')
requests.get(url)
time.sleep(1)
print(f'Fetched {url}!')
if __name__ == '__main__':
time_start = time.time()
with concurrent.futures.ProcessPoolExecutor() as ppe:
for url in URLS:
ppe.submit(fetch_single, url)
time_end = time.time()
print(f'\nAll done! Took {round(time_end - time_start, 2)} seconds')
Библиотека concurrent.futures используется для реализации параллелизма на основе процессов. И URLS, и fetch_single () идентичны, поэтому нет необходимости повторять их снова.
Внизу все становится интересно. Вам нужно будет использовать класс ProcessPoolExecutor. Согласно документации, это класс, который использует пул процессов для асинхронного выполнения вызовов [1].
Оператор with предназначен для того, чтобы все было правильно очищено после завершения задачи.
Вы можете использовать функцию submit () для передачи задач, которые вы хотите выполнять параллельно. Первый аргумент - это имя функции (убедитесь, что вы не вызываете его), а второй - для параметра URL.
После запуска этого скрипта вы получите следующий вывод в консоли:
Время выполнения заняло всего 1,68 секунды, что является значительным улучшением по сравнению с тем, что было у вас раньше. Это конкретное доказательство того, что задачи выполнялись параллельно, потому что последовательное выполнение не могло завершиться менее чем за 6 секунд (вызовы сна).
Заключение
И вот оно, самое базовое руководство по параллелизму на основе процессов с Python. Есть и другие способы ускорить ваши скрипты, основанные на параллелизме, и они будут рассмотрены в следующих статьях.
Пожалуйста, дайте мне знать, если вы хотите увидеть более сложные руководства по параллелизму. Они будут охватывать реальный пример использования в науке о данных и машинном обучении.
Спасибо за прочтение.
Пишите в комментариях, если Вам нужна помощь в решении задач.