Важным фактором, лежащим в основе любой нейронной сети, является оптимизатор, который используется для обучения модели. Самый известный оптимизатор, на котором построен почти каждый алгоритм машинного обучения, - это градиентный спуск (Gradient Descent).
Однако, когда дело доходит до построения моделей глубокого обучения, градиентный спуск сталкивается с некоторыми серьезными проблемами. Прежде чем разобраться в них, нам нужно разобраться в нюансах создания и работы самих нейронных сетей.
Если же вы хорошо владеете теоретической базой, то может пропустить первые два раздела.
Что такое нейронная сеть и как она работает
Искусственные нейронные сети (ИНС) вдохновлены биологическими или естественными нейронными сетями. Цель, стоящая перед специалистами по машинному обучению, - заставить эти сети функционировать так, функционирует наш мозг. Благодаря такому образцу, строение ИНС имеет практически такие компоненты, что и биологическая нейронная сеть.

Нейронная сеть представляет собой набор или систему взаимосвязанных единиц. Это и есть нейроны. Каждый из них имеет определенное значение (вес).
Нейрон является нервной клеткой, которая несет электрические импульсы. Это основная рабочая единица мозга, отвечающая за передачу информации каждой клетке тела. ИНС функционируют аналогичным образом, используя нейроны (или узлы).
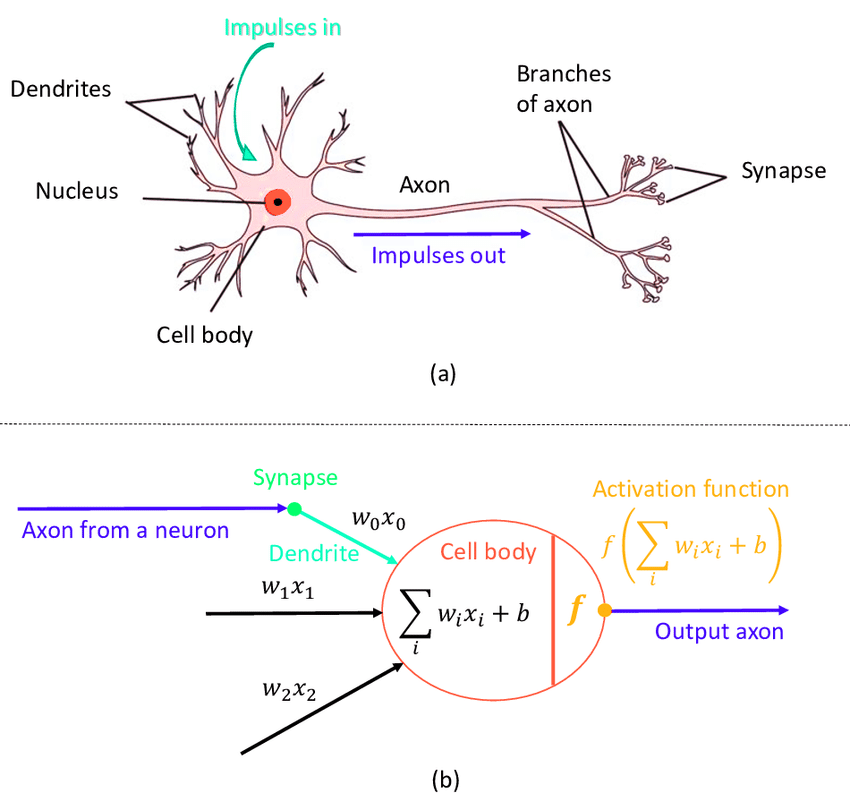
Разница лишь в том, как каждая из система получает и обрабатывает информацию информацию. Человеческий мозг получает информацию через пять органов чувств, обрабатывает ее и на основании этого принимает решение/действие.
Для нас это происходит на автопилоте, в то время как модели нужно сопоставлять разные числовые значения и выбирать наиболее оптимальный вариант. ИНС будет давать более высокую оценку и склоняться к тем вариантам, которые будут ближе к заложенным в нее условиям.
В случае классификации веб-страниц это проблема классификации, поэтому на выходе будет несколько классов. Функция является регрессором или классификатором (двоичным или многоклассовым) в зависимости от того, является ли выходная переменная непрерывной или категориальной.
Следовательно, архитектура нейронной сети будет иметь как минимум два уровня: входной и выходной. То, что находится между этими двумя слоями, называется скрытым слоем.
Скрытый слой состоит из нейронов, ново входном слое их нет. У входного слоя есть только входы, крестики. Каждый из этих уровней является результатом предыдущего уровня, и взаимосвязь между каждым из уровней показана ниже:
В каждом скрытом слое может быть любое количество скрытых слоев и любое количество нейронов. Архитектура сети определяется пользователем, поэтому количество скрытых слоев и количество нейронов остается на усмотрение пользователя.
Примерно на этом месте любопытные гуманитарии могут закрывать статью. Ведь дальше наступает время математики. Любая ИНС - это алгоритм, поэтому мы не можем построить какую-либо модель без математических уравнений.
Уравнение представляет собой линейную комбинацию входов и их соответствующих весов и коэффициентов смещения. Итак, уравнение нейронной сети:
Каждый из нейронов в скрытом слое будет иметь уравнение, подобное приведенному выше, которое будет связывать слои и соответствующие веса и коэффициент смещения. Так нейроны оцениваются, а затем переходят на следующий уровень.
Скрытые слои, а также выходной слой передаются через функцию, называемую функцией активации. Это важная часть, поскольку она добавляет нелинейности функции. Это необходимо, потому что, как правило, не все бизнес-задачи можно решить линейно. Поэтому, чтобы учесть нелинейность, мы применяем математическое преобразование к уравнению до того, как будет сгенерирован результат.
Существует несколько функций активации, и то, какую функцию использовать, зависит от их функциональности. Все, что нам нужно знать, это то, что выход нейрона - это выход функции активации.
Мы знаем, что для задачи бинарной классификации сигмоид необходим для преобразования линейного уравнения в нелинейное. Следовательно, функцией активации для двоичной классификации является сигмоид и выглядит так:
После применения активации, выход становится равен N1. Если преобразованное уравнение пересекает пороговое значение для нейрона, то выход равен классу 1, иначе выход равен классу 0.
Итак, у нас есть четкое представление о том, что такое нейронная сеть и как она работает, и этого более чем достаточно, чтобы понять роль оптимизаторов в нейронной сети.
Зачем нужны оптимизаторы для нейронной сети?
Целью любого оптимизатора является минимизация функции потерь или коэффициента ошибки. Функция потерь дает расстояние между наблюдаемым значением и прогнозируемым значением. Для этого она должна обладать двумя качествами: быть непрерывной и дифференцируемой в каждой точке.
Чтобы свести к минимуму потери, возникающие при использовании любой модели, нам нужны две вещи:
- Величина, на которую следует уменьшить или увеличить
- Направление движения
Gradient Descent неплохо справляется с этими двумя потребностями.
Скорость обучения и dL / dw помогают нам выполнить два требования для минимизации функции потерь:
- Скорость обучения: отвечает на размерную часть. Он управляет обновлением весов, сообщая, на какую величину увеличить или уменьшить.
- dL / dw: указывает, насколько параметр должен увеличиваться или уменьшаться. Он указывает направление своим знаком.
Это итеративный процесс поиска параметров (или весов), которые сходятся с оптимальным решением. Оптимальное решение - минимизация функции потерь.
Теперь, как мы знаем, в нейронной сети может быть множество скрытых слоев и нейронов. Мы не рассматриваем один конкретный вес для одного уравнения. Но веса, прикрепленные к каждому нейрону в каждом слое, а также от выходного слоя обратно к исходному входному слою. В таком случае веса, которые обновляются с помощью градиентного спуска, не хватает в двух важных местах:
- Градиентный спуск застревает на локальных минимумах
- Скорость обучения не меняется в градиентном спуске
Далее разберем самые распространенные проблемы с градиентным спуском.
Проблема 1: Градиентный спуск застревает на локальных минимумах
Проблема
Первая проблема с градиентным спуском заключается в том, что он застревает на локальных минимумах. Давайте разберемся в этом, увидев приведенную ниже функцию стоимости.
Указатель с синей стрелкой - это глобальный минимум, то есть точка, в которой функция стоимости является самой низкой во всей функции стоимости.
Точка, в которую помещен зеленый шар, имеет минимальное значение функции стоимости среди своих соседей и, следовательно, является локальным минимумом. Обычно на этом этапе градиентный спуск застревает. Однако локальные минимумы не там, где функция стоимости самая низкая.
Причина
На изображении выше, помимо зеленого шара, есть еще три пунктирных круга. В каждой из этих точек мы вычисляем градиент или наклон и, используя приведенную ниже формулу, обновляем веса и уменьшаем функцию стоимости.
Теперь, после нескольких итераций, мы достигли точки, в которую помещен зеленый шар. На этом этапе мы снова вычисляем, и здесь градиент или наклон равен нулю, а затем уравнение сводится к:
Решение
На графике приведенном выше, когда шар опускается из положения U, он будет иметь некоторую скорость, и назовем эту скорость как U. При снижении шар достигает положения V, где скорость обозначается буквой V в зависимости от его положения.
Теперь скорость V определенно будет больше, чем скорость U, поскольку шар движется в нисходящем направлении.
Теперь, когда он достиг локальных минимумов, он может получить толчок, чтобы в конечном итоге выйти из локальных минимумов. Короче говоря, чтобы вывести мяч из локальных минимумов, нам нужно накопить импульс или скорость.
Как это представить математически?
В терминах нейронной сети накопленная скорость эквивалентна взвешенной сумме прошлых градиентов:
На этот раз новые веса не равны прошлым, потому что Mt-1, который является ранее накопленным градиентом, имеет некоторое прошлое значение. Следовательно, текущая взвешенная Mt будет иметь значение, достаточное для толчка для выхода из локальных минимумов.
Проблема 2: Скорость обучения не меняется в градиентном спуске
Проблема
Вторая проблема с градиентным спуском заключается в том, что скорость обучения остается неизменной на протяжении всего процесса обучения по всем параметрам. Напомним, скорость обучения - это размер шага, который указывает алгоритму, сколько он должен сделать, чтобы достичь оптимального решения минимизированного члена ошибки.
Причина
В общем, некоторые переменные могут привести к более быстрой сходимости, чем другие. Используя постоянную скорость обучения на протяжении всего процесса обучения, мы можем заставить эти переменные оставаться синхронизированными, что приведет к более медленной сходимости к оптимальному решению.
Итак, мы хотим, чтобы скорость обучения обновлялась в соответствии с функцией затрат по мере продвижения обучения. Как мы можем это сделать?
Решение
В процессе тренировки наклон или градиент dL / dw меняется. Это скорость изменения функции потерь относительно веса параметра, и, применяя ее, мы можем обновить скорость обучения.
Мы можем взять сумму квадратов прошлых градиентов, то есть квадрат суммы частных производных dL / dw, как показано ниже:
Так как некоторые градиенты могут быть положительными, а другие отрицательными, мы и берем квадраты этих градиентов. Это, как правило, сводит на нет результат. Следовательно, мы берем квадрат градиентов и добавляем его к предыдущим квадратным склонам, которые представлены η.
Использование η может обновить скорость обучения в следующем уравнении, то есть. используется для вычисления новых весов:
Мы используем η в уравнении взвешенной суммы градиентов, которое мы использовали для решения первой задачи градиентного спуска по выходу из локальных минимумов:
Как мы только что видели, мы будем использовать квадрат наклонов, поэтому подставив его в это уравнение, мы получим:
Теперь, используя взвешенную сумму квадратов прошлых градиентов, уравнение для обновления новых весов принимает следующий вид:
ε - погрешность. Она добавляется к Vt, чтобы знаменатель не становился равным нулю. Этот коэффициент ошибки, как правило, имеет очень маленькое значение. Давайте разберемся, как это окончательное уравнение помогает обновлять скорость обучения в процессе обучения:
На иллюстрации слева значение потерь на функции находится в первой самой верхней точке. На этом этапе мы рассчитаем градиент. Здесь величина уклона велика, что также увеличивает площадь уклона. Это снизит скорость обучения, и мы должны предпринять небольшие шаги, чтобы минимизировать потери. Маленькие шаги проиллюстрированы нисходящими шагами на функции потерь.
В то время как график с правой стороны, где самая низкая точка функции потерь, имеет низкую величину градиента. Следовательно, и квадрат этого градиента будет меньше. Это увеличит скорость обучения и позволит сделать большие шаги к оптимальному решению.
Таким образом RMSProp масштабирует скорость обучения в зависимости от квадрата градиентов, что в конечном итоге приводит к более быстрой сходимости к оптимальному решению.
Бонус: Какой оптимизатор лучше подходит для нейронных сетей
Теперь, когда мы разобрались, как решить проблемы застревания на локальных минимумах и изменить скорость обучения, важно определиться, какой оптимизатор лучше использовать.
Придется ли нам выбирать между ними или есть способ объединить оба этих оптимизатора?
Мы хотим поговорить о еще одном оптимизаторе с символическим названием - Adam.
Adaptive Moment Estimation (или Adam) - то смесь стохастического градиентного спуска с моментумом и RMSProp. Это самый популярный и самый эффективный из оптимизаторов. Он в буквальном смысле вобрал в себя лучшее от своих конкурентов.
Уравнение обновления веса для Adam выглядит следующим образом:
Заключение
Итак, у нас было две проблемы:
- Градиентный спуск застревает на локальных минимумах. Решением для этого является использование стохастического градиента с импульсом, который использует взвешенную сумму градиентов, чтобы помочь выйти из локальных минимумов.
- Скорость обучения при градиентном спуске постоянна на протяжении всего процесса обучения по всем параметрам. Это может замедлить сближение. В качестве средства для этого мы меняем оптимизатор с градиентного спуска на RMSProp.
Избежать их и добиться наибольшей стабильности и производительность поможет Adaptive Moment Estimation.
Мы надеемся, что эта статья была вам полезна. Если так, то ждем царский лайк и подписку на канал. А также расскажите в комментариях, каким оптимизатором пользуетесь вы.
Другие наши статьи: