Мы запускаем серию статей о тонкостях и тайнах алгоритмов обработки естественных языков #ipavlov_nlp. Не пропустите!

Chapter 1.
NLP расшифровывается как Natural Language Processing (обработка естественного языка) - общее направление технологий Искусственного Интеллекта и компьютерной лингвистики. NLP изучает проблемы компьютерного анализа и синтеза текстов на естественных языках для реализации более удобной формы человеко-компьютерного взаимодействия.
Язык - уникальное свойство высокоуровневых систем, которое фактически является “протоколом” для коммуникации между людьми. Мысли преобразуются в текст с помощью данного инструмента, который передается посредством речи или символов таким образом, чтобы смысл был понятен другому человеку. Мы разговариваем на том или ином языке не задумываясь, для нас это что-то естественное. А как с этим справляется компьютер, процессор которого - это не живой организм, а подложка из неорганических соединений: кремния и его оксида?
Работу искусственного интеллекта по анализу естественной речи можно сравнить с написанием диктанта по русскому языку в школьные годы :) Устную речь переводим в письменную (технология преобразования речи в текст, Speech-to-Text), проверяем орфографию и пунктуацию (spell-checking, autocorrect - автоисправление слов), выделяем основы и корни, подчеркиваем главные члены предложения и определяем основную мысль и цель текста. Все перечисленное можно структурировать на последовательность уровней, на которых решаются задачи NLP:
- Вход (input): считывание текста (буквы по порядку), распознавание речи (приём и обработка звуковой волны), Optical Character Recognition (оптическое распознавание символов) - начальный этап. Нужно перевести информацию в формат, удобный для NLP (символы, слова).
- Морфология (Morphology): понимание структуры слова из символов. Проверка текста, (spell checker), поиск по словам (выключение окончаний, падежи привести), stemming (выделение основы).
- Синтаксис (Syntax): проверка текста с пунктуацией: подлежащее и сказуемое. Разделение текста на основную часть и второстепенную - следующий уровень над словами. Парсинг и crawling - хотим вычленить ключевые слова.
- Семантика (Semantics): машинный перевод (с одного языка на другой) на основе одного предложения, Question Answering (QA). Важен смысл фразы.
- Контекст (Context). Чат-боты, AI-ассистенты должны еще запоминать информацию, которую ты говорил раньше. Анализ тональности текста.
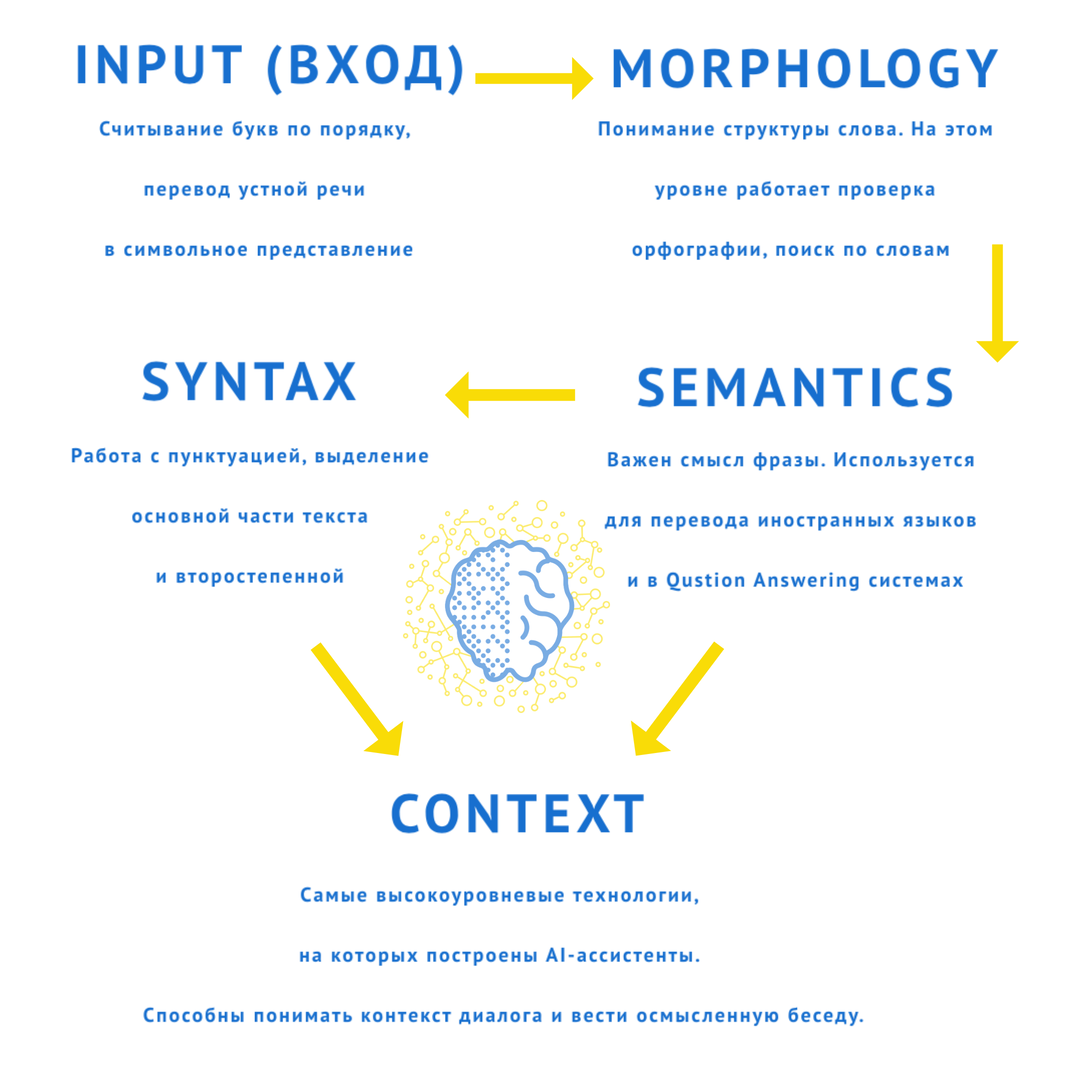
На IV и V ступенях работают Чат-боты и Цифровые ассистенты, самые высокоуровневые технологии NLP.
Воспроизвести каждый из этапов процесса NLP с помощью программного кода - одна из самых больших и интересных задач для наших разработчиков!
Чтобы познакомить Вас с этими алгоритмами, мы запускаем серию постов от наших разработчиков #ipavlov_nlp . В следующий раз мы расскажем, как предсказывать в Python наиболее вероятное ближайшее окружение слова.
Stay tuned!
iPavlov NLP:
Часть 1.
iPavlov NLP: о тайнах в мире Искусственного Интеллекта и Цифровизации!
Часть 2.
iPavlov NLP: Word embedding: word2vec или one-hot encoding?
Часть 3.
iPavlov NLP: Recurrent Neural Networks (RNNs)
Часть 4.
iPavlov NLP: RNNs - генерация текста
https://zen.yandex.ru/profile/editor/id/5fb59c3be146c2727a6f5f68/610d1817e54ec275aceba141/edit



















