Анализ данных - один из важнейших этапов машинного обучения. Перед тем, как использовать датасет, важно понять применим ли он для конкретного алгоритма обучения. Например, математические операции не применены к категориальным данным или в данных могут быть прощены некоторые значения, что негативно скажется на всех последующих этапах работы.
Именно поэтому мы хотим рассмотреть один из самых свежих и эффективных инструментов: новую библиотеку с открытым исходным кодом на Python - Sweetviz 2.0. С ее помощью вы сможете определять типы данных, обнаруживать недостающую информацию, распределять значения, выявлять корреляции и еще много чего другого.
По традиции LabelMe подробно изучил вопрос и представляет вашему вниманию всё, что нужно знать о Sweetviz 2.0.

Основная информация о Sweetviz 2.0
Sweetviz 2.0 - это библиотека на основе Pandas с открытым исходным кодом для выполнения основных задач EDA без особых хлопот с помощью всего двух строк кода. Она помогает с созданием сводных отчетов с отличной визуализацией. Sweetviz 2.0 берет фреймы данных и создает автономный HTML-отчет, который можно просматривать напрямую в браузере или интегрировать в удобные для вас программы.
К основным преимуществам библиотеки можно отнести:
- Целевой анализ: показывает, как целевое значение (например, «Выживший» в наборе данных «Титаник») соотносится с другими функциями.
- Сравнение наборов данных: между наборами данных (например, «обучение/тестирования») и внутри набора (например, «мужчины/женщины»).
- Корреляция / ассоциации: полная интеграция числовых и категориальных корреляций и ассоциаций данных, все в одном графике и таблице.
Что всё это нам даёт? Разведочный анализ данных (EDA) перестает быть утомительной, рутинной и долгой процедурой. Вам не придется вручную перебирать, сравнивать и использовать несколько разных пакетов для обработки. Воспринимать Sweetviz 2.0 как скатерть самобранку тоже не стоит: она упрощает процесс, но ни в коем случае не выполнит его полностью. Впрочем, давайте лучше подробнее рассмотрим все этапы работы.
Установка Sweetviz 2.0 и предварительный анализ
Основная команда для установки пакета с помощью pip:
pip install sweetviz
Для Notebook / Colab используем команду:
! pip install sweetviz
Для примера возьмем готовый исходный код. Здесь используется датасет Student Performance, в котором есть как числовые, так и категориальные данные:
- пол: категориальный
- раса / этническая принадлежность: категориальный
- уровень образования родителей: категориальный
- обед: категориальный
- курс подготовки к экзаменам: категориальный
- оценка по математике: числовой
- оценка по чтению: числовой
- оценка письма: числовой
Датасет содержит записи о 1000 студентах, поэтому для упрощения работы будем использовать Pandas для чтения файла csv:
Здесь нам пригодится мощная функция Sweetviz 2.0 - analyze(), которая помогает анализировать данные с первого взгляда.
Бац и наш предварительный анализ готов.
Формирование подробного отчета и визуализация
Получив отчет, мы можем использовать функцию show_html () для его визуализации:
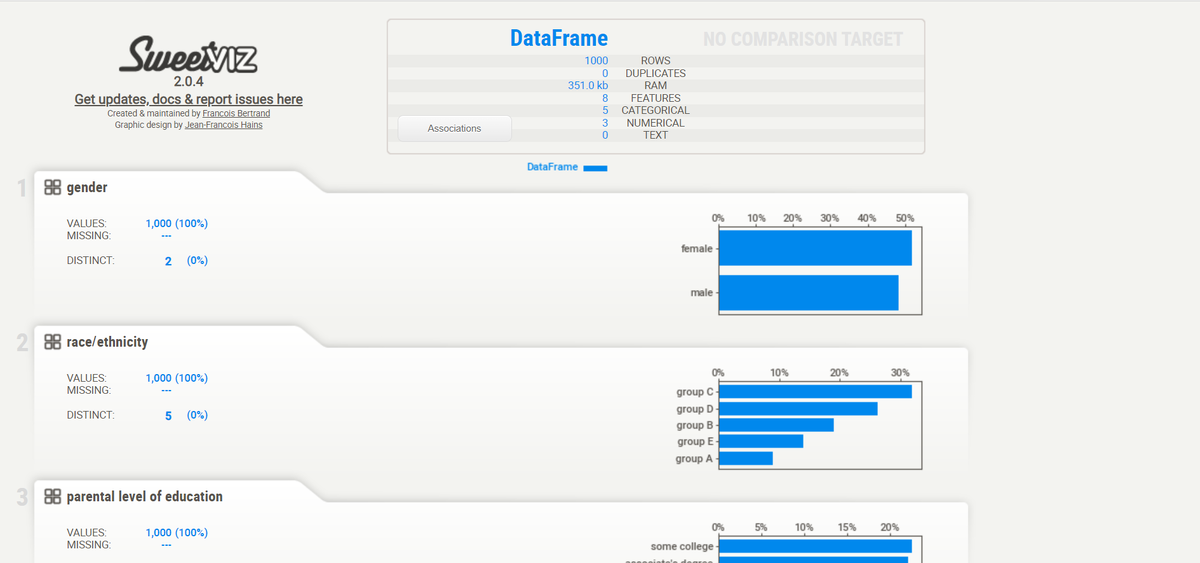
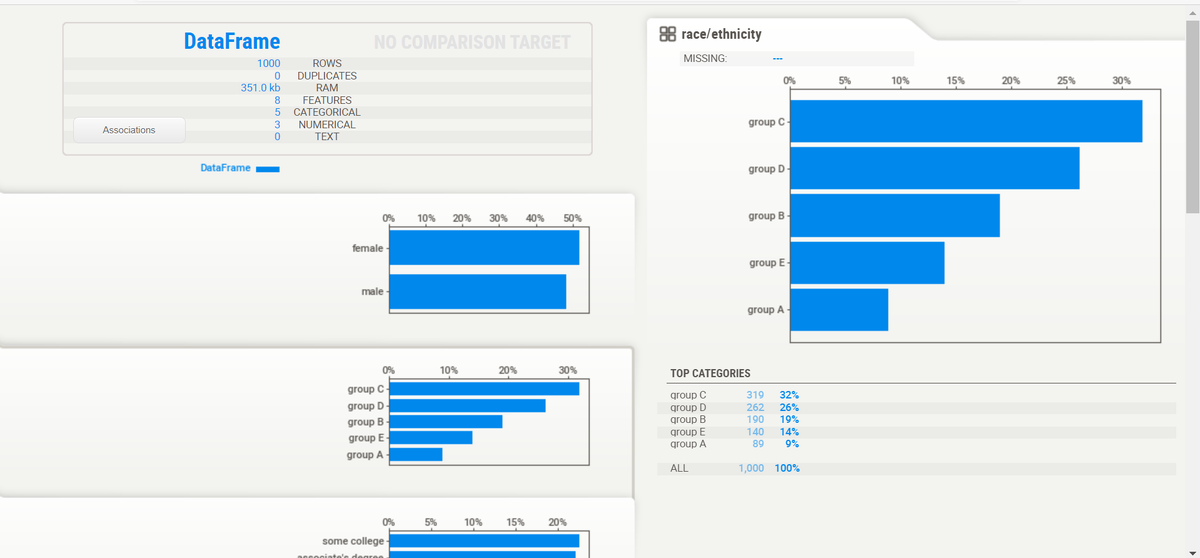
Если в функции show_html () не заданы какие-либо параметр, то по умолчанию она создает файл с именем «SWEETVIZ_REPORT.html».
Также мы можем сравнить два набора данных, для чего их нужно разделить на две половины:
Далее:
На выходе получаем это:
Если вы не задавали параметры для функции compare (), то советуем обратиться к двум наборам данных: Dataframe и Compared соответственно.
В Sweetviz 2.0 нам доступен и целевой анализ. Правда, пока что он не поддерживает только категориальные цели, а только числовые и двоичные. В нашем примере это можно использовать для сравнения оценок по математике среди студентов:
Ассоциации и корреляции в Sweetviz 2.0
Прежде чем перейти к ассоциациям и корреляциям, предлагаем еще раз пробежаться по всем этапам. Это позволит избежать путаницы.
На этот раз берем очищенную версию набора данных клиентов кредитных карт. Полная версия - здесь, а отчищенная - здесь. Разница заключается в удалении двух последних столбцов, как указано в описании, а переменная Attrition_Flag была преобразована в логическое значение, как и предполагалось.
Шаг 1: загружаем фреймы данных Pandas:
Шаг 2: создаем отчет
- analyze() для одного набора данных
- compare() для сравнения двух наборов данных
- compare_intra() для сравнения двух подгрупп в одном наборе данных
В нашем случае выбираем первый вариант, так у нас один набор данных. Плюс делаем акцент на переменную Attrition_Flag:
Шаг 3: генерируем вывод
Запускаем функцию report.show_html () и выбираем подходящий способ вывода:
- Макет (горизонтальный или вертикальный)
- Масштабирование
- Размер окна (для ноутбуков)
Вверху отчета - простой обзор набора данных (вместе со сравнением при сравнении).
Для каждой функции Sweetviz наилучшим образом определит тип данных каждого столбца между:
- числовой
- категориальный / логический
- текст (по умолчанию / резерв)
Теперь мы плавно подобрались к ассоциациям и корреляциям. Нажимая на соответствующую кнопку, вы запустите алгоритм глубокого анализа. Полученный график представляет собой смесь визуальных элементов из книги Дражен Зарич "Лучшие тепловые карты и графики корреляционной матрицы на Python" и концепций из книги Шакед Зихлински "Поиск категориальной корреляции" .
По сути, помимо отображения традиционных числовых корреляций, он объединяет в одном графике числовую корреляцию, коэффициент неопределенности (для категориально-категориальных) и коэффициент корреляции (для категориально-числовых).
Те же данные также можно найти на панели "подробностей" каждой переменной:
Целевой анализ и анализ общих характеристик
Целевой анализ особенно необходим, если в данных присутствуют целевые переменные. Если мы укажем целевую переменную (как мы уже сказали выше, в настоящее время поддерживаются только логические и числовые), она будет заметно отображаться как первая переменная и будет окрашена в черный цвет.
Что наиболее важно, его значение накладывается поверх всех остальных графиков, быстро давая представление о распределении цели по всем остальным переменным.
С первого взгляда вы можете сразу определить, как на целевое значение влияют другие переменные. Как и ожидалось, это обычно соответствует тому, что находится в графике «Associations», но дает вам особенности для каждой переменной. Вот пример:
ВАЖНО: помните, что вы можете использовать Target Analysis для анализа любой функции по отношению ко всем остальным. Это может оказаться большим подспорьем для понимания того, как функции соотносятся друг с другом, даже если в анализируемых вами данных нет «фактической» целевой переменной.
Переходим к анализу общих характеристик. Основная часть отчета - это сводная и подробная информация по каждой функции:
Обратите внимание, что для числовых данных вы можете изменить количество «ячеек» на графике. Это позволяет проще и точнее измерять распределение и корреляцию целевой функции.
Например, если на приведенном выше снимке экрана мы изменим количество ячеек на 30, то получим более четкое представление о том, как изменяется цель с помощью этой функции:
Сравнение наборов данных и подгрупп
Sweetviz может сравнивать два разных набора данных, что может быть чрезвычайно полезно (например, данные Train vs Test). Но, даже если вы просматриваете только один набор данных, вы можете изучить характеристики различных подгрупп внутри него.
Давайте смоделируем пример, используя вышеуказанную функцию. Кажется, что когда значение «Total_Ct_Chng_Q4_Q1» ниже примерно 0,6, Attrition_Flag значительно выше.
Мы можем изолировать эту популяцию, используя функцию compare_intra (), и задать это условие для разделения:
В результате получаем следующий отчет, который позволит узнать много нового о наших данных. Просто взглянув на первые две переменные, мы сразу увидим, что Customer_Age и Gender ведут себя по-разному при разделении популяций с помощью этой функции «Total_Ct_Chng_Q4_Q1» по сравнению с их общим распределением:
Еще больше подобных примеров можно посмотреть по ссылке.
Заключение
Загибаем пальцы:
- Целевой анализ
- Сравнение наборов данных и групп внутри него
- Полный анализ функций
- Выявление ассоциаций и корреляций
- Подробная и быстрая визуализация
А теперь представим, что всё это в двух строках кода и получаем Sweetviz 2.0. Мы получаем беспрецедентный функционал, который позволяет упростить работу с подготовкой и анализом данных. Но даже на этом EDA Sweetviz продолжает приносить пользу:
- Разработка функций: визуализируйте, как спроектированные функции работают / коррелируют относительно других функций и целевой переменной;
- Тестирование: подтвердите состав и баланс наборов для тестирования / валидации;
- Интерпретация / коммуникация: сгенерированные графики могут предоставить информацию, которая легко интерпретируется (например, скриншоты выше) и может быть быстро передана команде или клиентам без дополнительной работы.
Экспертное заключение от LabelMe: "Вау! Это нам подходит!"
Другие наши статьи: