Предыдущая часть: Делаем список категорий
Код для этого выпуска лежит на github в ветке join.
В предыдущей части мы добавили к заметкам категории, связав таблицы заметок и категорий через id категории.
При просмотре списка заметок или отдельной заметки вместо категории мы увидим только её id:

Это и неудивительно, ведь в заметке больше ничего не хранится.
Для решения этой проблемы мы можем просто сделать два запроса к базе, когда просматриваем заметку: первый запрос уже написан, он получает собственно заметку, а второй запрос получит категорию, используя category_id из заметки. Передав модель заметки и модель категории в представление просмотра, мы обеспечим все необходимые данные для вывода:
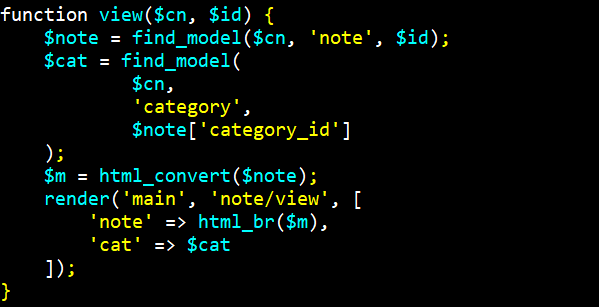
Здесь немного доработана функция find_model(), чтобы можно было искать данные в разных таблицах – мы дополнительно передаём в неё имя таблицы.
Теперь в представлении, где нужно показать категорию, мы просто выводим $cat['title']:
Готово.
Теперь нужно сделать то же самое со списком заметок:
Но здесь мы натыкаемся на проблему. Список состоит из нескольких записей, которые мы выводим в цикле. Следовательно, чтобы получить категорию для каждой записи, нужно также в цикле делать запросы к таблице категорий.
Если у нас, к примеру, 1000 заметок, и мы их все показываем на экране, то значит придётся сделать 1000 запросов к таблице категорий.
И если уж по-честному, то на это наплевать. База выдержит и не такое, и для нашего домашнего проекта это не имеет никакого значения.
Однако в промышленных проектах с высокой нагрузкой таких вещей следует избегать.
Решение 1. Массив-справочник
Перед тем, как выводить заметки, мы получаем список всех категорий и записываем его в массив. У нас даже есть функция для этого:
Но она возвращает не массив, а объект-результат выполнения запроса. Это объект можно только перебирать последовательно, а нам нужен произвольный доступ к любому элементу массива. Поэтому мы преобразуем его в массив, где ключами будут id категорий, а значениями названия (title) категорий:
Передадим этот массив в представление note/index, которое отвечает за вывод списка заметок:
Теперь в представлении будем для вывода использовать не $note['category_id'], а $categories[$note['category_id']]:
И готово:
Решение 2. JOIN
JOIN это инструкция MySQL (и других SQL-языков), которая позволяет объединять данные из нескольких таблиц. "JOIN" значит "присоединить".
Итак, идея проста: если в таблице note лежат данные о заметках, а в таблице category данные о категориях, то почему бы не написать запрос, который берёт данные сразу из двух таблиц? Тогда мы получим и те, и другие данные, и у нас всё будет в комплекте.
Такой запрос можно написать, просто перечислив имена таблиц через запятую:
select * from note, category;
Чтобы выбирать не все поля, а только необходимые, их можно перечислить явно:
select note.id, note.category_id, note.title, category.id, category.title from note, category;
Мы получим такой результат:
Сейчас в таблице note две записи ("My Title" и "My Title 2"), а в таблице category три записи ("Автомобили", "Кошки", "Собаки"). Результат объединения состоит из 6 записей.
То есть: берем строку из note, и объединяем по очереди со всеми строками из category. Получаем три объединённых строки. Затем берём вторую строку из note и опять объединяем по очереди со всеми строками из category. И т.д. Если в первой таблице M строк, а во второй N, то в результате получится M*N строк.
Результаты в таком виде нам не подходят, так как одни и те же записи из note дублируются. Из этого множества нужно выбрать только подходящие записи. Это те, у которых note.category_id совпадает с category.id:
Добавим в запрос условие WHERE, которое отфильтрует нужные записи:
select note.id, note.category_id, note.title, category.id, category.title
from note, category
where note.category_id = category.id;
И теперь получаем только то, что надо:
Тот же самый результат мы можем получить с помощью инструкции JOIN:
select note.id, note.category_id, note.title, category.id, category.title
from note join category on note.category_id = category.id;
По сути, вместо "note, category" пишем "note join category", а вместо "where" пишем "on". Вот и вся разница.
Запросы, составленные и тем и другим способом, идентичны. Но у JOIN есть одна особенность, которую сейчас рассмотрим.
Сделаем одной из заметок такой category_id, который отсутствует в таблице категорий, например 100:
Теперь проверим, что выдаст объединённый запрос:
Результат ожидаем. Так как категория с id=100 отсутствует, совпадений с ней нет, и в результат попала только одна запись.
Теперь напишем то же самое, но вместо JOIN напишем LEFT JOIN:
Теперь мы получили две записи. Это две строки из таблицы note, где к каждой строке приписано соответствующе поле из таблицы category. Так как для первой строки из note нет соответствующей строки из category, значением столбца становится NULL.
Иначе говоря, LEFT JOIN сохраняет в выдаче все строки из ЛЕВОЙ таблицы, даже если совпадений по условию нет.
Тогда, по интуиции, RIGHT JOIN должен сохранять все строки из ПРАВОЙ таблицы? Давайте проверим:
Да, действительно так. Чтобы показать это более наглядно, нарисуем схемы:
Последний вариант, INNER JOIN, это то же самое, что просто JOIN, и совпадает с вариантом, где используется объединение таблиц без JOIN c условием WHERE.
Зачем сохранять все строки слева или справа?
В базах данных очень часты случаи, когда некоторые таблицы остаются "недозаполненными" или между ними просто нарушаются связи. Например, мы удалили категорию "автомобили", и в таблице note все заметки с категорией "автомобили" теперь имеют несуществующий category_id. Простое пересечение двух таблиц (INNER JOIN) приведёт к тому, что из списка исчезнут все заметки с категорией "автомобили", как будто их вообще нет. Но ведь нам надо их видеть в любом случае. Поэтому LEFT JOIN позволяет сохранить в выдаче все строки.
Также с помощью LEFT JOIN мы можем найти все заметки, у которых указана несуществующая категория:
Так как в результатах объединения у "неправильных" заметок поле category.title будет равно NULL, мы добавили дополнительное условие WHERE, которое проверяет это поле.
Напишем, наконец, реализацию для нашего проекта. Но нужно поправить ещё кое-что.
Так как таблица note имеет поле title и таблица category также имеет поле title, в результатах запроса у нас появится два одинаковых поля title, к которым мы не сможем организовать доступ из программы. Поэтому есть механизм переименования полей в результатах запроса:
Как видим, поле title теперь называется note_title (только в этом запросе, а не вообще). Применим это для JOIN:
И теперь мы можем пользоваться результатами запроса, обращась к полям title и cat_title.
Пишем код в контроллере note.php:
И меняем вывод в представлении views/note/index.php, используя поле cat_title:
Готово. Теперь в списке заметок мы видим названия категорий, точно так же как видели их в предыдущем решении, с массивом-справочником. Замечу, что в данном случае оба решения нормальные. Можно использовать и то и другое. Также для просмотра одной заметки можно использовать JOIN, но и там оба решения рабочие. Так что оставляю.
Читайте дальше: Правильное удаление категорий и повторное редактирование заметок



















