В машинном обучении, статистике, анализе данных и глубоком обучении есть множество сложных задач и уравнений, требующих специальных алгоритмов. Например, оценка максимального правдоподобия (подумайте о логистической регрессии или алгоритме ЭМ) или градиентные методы (подумайте о стохастической или роевой оптимизации). Но есть еще более сложные задачи, для решения которых нельзя использовать какой-то определенный набор параметров. Для них нужны сложные функции.
Контекст - это дискретные, хаотические динамические системы для прогнозирования погоды, моделей роста населения, роста цен на фондовых рынках, шифрованию изображений, моделированию химических реакций и так далее. Всё это - сложные системы. Для работы с ними требуются численные методы, так как в большинстве случаев не может быть 100% точного ответа.
Тип решаемого уравнения называется функциональным уравнением или стохастическим интегралом. LabelMe рассмотрел несколько случаев, когда нам известно точное решение: это поможет оценить эффективность, точность и скорость сходимости численных методов, обсуждаемых в этой статье. Эти методы основаны на алгоритме с фиксированной точкой, применяемом к бесконечномерным задачам.
1. Общая проблема
Мы имеем дело с дискретной динамической системой, определяемой формулой х n +1 = T ( Хn ), где T - вещественная функция, а Х о - начальное условие. Для удобства мы ограничимся случаем, когда x n находится в диапазоне [0, 1]. Здесь описываются обобщения, например, когда xn является вектором. Наиболее известным примером является логистическая карта с T(x) = λx(1-x), проявляющая хаотическое поведение или нет, в зависимости от значения параметра λ.
В нашем случае функция T ( x ) принимает следующий вид:
T ( x ) = p ( x ) - INT ( p ( x ))
Где:
- INT обозначает целочисленную часть функции,
- p(x) положительна, монотонна, непрерывна и убывает (следовательно, биективна) при p(1) = 1 и p(0) бесконечна.
Например, p ( x ) = 1 / x соответствует карте Гаусса, связанной с непрерывными дробями. Это самый фундаментальный и базовый пример. Другой пример - карта Гурвица-Римана, описанная здесь.
1.1. Инвариантное распределение и эргодичность
Инвариантным распределением системы считается та, за которой следуют последовательные Хn. Другими словами это предел эмпирического распределения, связанного с xn, при заданном начальном условии х0. Много интересных свойств можно получить, если инвариантная плотность f(x) (производная инвариантного распределения) известна (если она существует).
Это работает только с эргодическими системами, как все приведенные в примерах. Инвариантное распределение применимо почти ко всем начальным условиям x0. Хотя есть и исключения. Это типичная особенность всех этих систем. Для некоторых из них (например, карта Бернулли) x0, которые не являются исключениями, считаются нормальными числами.
Под эргодичностью мы подразумеваем, что почти для любого начального условия x0 последовательность ( xn ) в конечном итоге посещает все части [0, 1] в равномерном и случайном смысле. Это означает, что среднее поведение системы может быть выведено из траектории «типичной» последовательности ( xn ), привязанной к начальному условию x0. Эквивалентно достаточно большой набор случайных экземпляров процесса (также называемых орбитами) может представлять среднестатистические свойства всего процесса.
В теории вероятности инвариантные распределения называются равновесными или аттракторными распределениями.
1.2. Решаемое функциональное уравнение
Предположим, что инвариантное распределение F ( x ) можно записать как F ( x ) = r ( x + 1) - r (1) для некоторой функции r.
Тогда область поддержки для F ( x ) - [0, 1] будет выглядеть так:
F (0) = 0, F (1) = 1, F ( x ) = 0, если x <0, и F ( x ) = 1, если x > 1.
Определим R ( x ) = r ( x + 1) - r ( x ). Тогда мы можем получить p ( x ) (при некоторых условиях) по формуле:
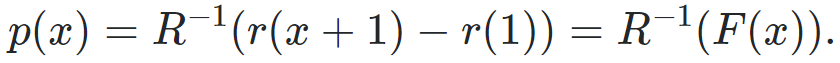
Таким образом, r(x) должно увеличиваться на [1,2] и r(2) = 1 + r(1). Ни каждая функция может быть инвариантным распределением.
На практике мы знаем p ( x ) и пытаемся найти инвариантное распределение F ( x ). Таким образом, приведенная выше формула бесполезна, за исключением того, что она помогает вам создать таблицу динамических систем, определяемых их функцией p ( x ) с известным инвариантным распределением.
Такая таблица доступна здесь обратите внимание на пример 5 с дзета-системой Римана. Если известно точное решение, полезно протестировать алгоритм с фиксированной точкой, описанный в разделе 2.
Если нам известно только p ( x ), то для получения F ( x ) или его производной f ( x ), то нужно решить следующее функциональное уравнение, неизвестным для которого является функция f:
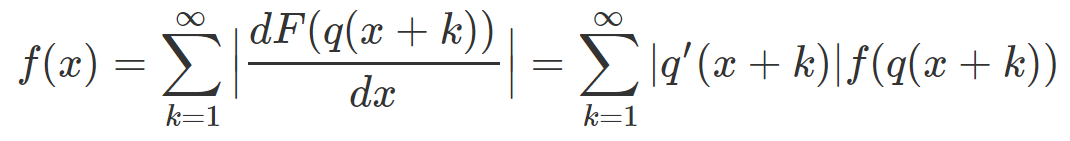
q - функция, обратная функции p. Заметим, что
R ( x ) = F ( q ( x )) или, альтернативный вид, R ( p ( x )) = F ( x ), где p ( q ( x )) = q ( p ( x )) = x. Кроме того, здесь x находится в пределах [0, 1]. На практике вы получите хорошее приближение, если используете сумму первых 1000 членов. Обычно инвариантная плотность f ограничена, а | q '( x + k ) | относительно быстро распадаются по мере увеличения k.
Инвариантная плотность - это собственная функция передаточного оператора, соответствующая собственному значению 1. Кроме того, если x заменяется вектором (например, при работе с двумерными динамическими системами), указанная выше формула может быть обобщена, включая две переменные x и y , а производная от (совместного) распределения заменяется якобианом.
2. Численное решение с помощью алгоритма с фиксированной точкой
Последняя формула в предыдущем подпункте предлагает простой итерационный алгоритм для решения этого типа уравнений. Вам нужно начать с функции f 0 , и в этом случае равномерное распределение в области [0, 1] обычно является хорошей отправной точкой. То есть
f 0 ( x ) = 1, если x находится в [0, 1], и 0 в другом месте. Итерационный шаг выглядит следующим образом:
Каждая итерация n генерирует совершенно новую функцию fn на [0, 1], и есть надежда, что алгоритм сходится, поскольку n стремится к бесконечности. В случае сходимости предельной функцией должна быть инвариантная плотность системы. Это пример алгоритма с фиксированной точкой в бесконечном измерении.
На практике вы вычисляете f(x) только для (условно) 10 000 значений x, равномерно расположенных между 0 и 1.
Если, например, fn+1(0.5) требует вычисления fn(0.879237...) и ближайшим значением в вашем массиве является fn(0.8792). Вы заменяете fn(0.879237...) на fn(0.8792) или используете методы интерполяции.
Это более эффективно, чем использование функции, определенной рекурсивно в языке программирования. Удивительно, но сходимость очень быстрая, и в проверенных примерах ошибка между истинным решением и полученным после 3 итераций очень мала. Просто взгляните на график.
На иллюстрации p(x) = q(x) = 1 / x, а инвариантное распределение известно:
f(x) = 1 / ((1+x)(log 2))
Оно изображено красным цветом и связано с распределением Гаусса-Кузьмина. Обратите внимание, что мы начали с равномерного распределения f0, изображенного черным цветом (плоская линия). Первая итерация f1 выполнена зеленым цветом, вторая f2 - серым, а третья f3 - желтым и она почти неотличима от точного решения (красный).
Исходный код для этих вычислений доступен здесь. В исходном коде есть два дополнительных параметра α и λ. Когда α = λ = 1, это соответствует классическому случаю p ( x ) = 1 / x.
3. Приложения
Одна интересная концепция, связанная с этими динамическими системами, - это заряд. n заряд dn определяется как INT(p(xn)), где INT-функция целочисленной части.
Если вы знаете заряды, прикрепленные к начальному условию x 0, вы можете получить x 0 с помощью простого алгоритма. Начните с n = N и x n + 1 = 0 . Так вы получило заряд точности для х 0 и вычислите итеративно xn от n = N to n = 0, используя рекурсию xn = q(xn+1 + dn) - INT(q(xn+1 + dn)). Эти заряды могут быть использованы в системах шифрования.
Для начала давайте посмотрим на заряды x 0 = π - 3 в двух разных динамических системах:
- Непрерывные дроби: Здесь p ( x ) = 1 / x. Первые 20 цифр: 7, 15, 1, 292, 1, 1, 1, 2, 1, 3, 1, 14, 3, 3, 23, 1, 1, 7, 4, 35.
- Менее хаотичная динамическая система: Здесь p ( x ) = (-1 + SQRT (5 + 4 / x )) / 2. Первые 20 цифр: 2, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 1 , 1, 26, 1, 3, 1, 10, 1, 1. У нас также есть F (x) = 2 x / ( x + 1).
Распределение цифр известно в обоих случаях. Для цепных дробей это распределение Гаусса-Кузьмина. Для второй системы вероятность того, что заряд равен k вычисляется так: 4 / ( k ( k +1)( k +2)).
В общем, рассматриваемая вероятность равна F ( q ( k )) - F ( q ( k +1)) для k = 1, 2 и т. д. Очевидно, что распределение этих зарядов можно использовать для количественной оценки уровня хаотичности системы. Для непрерывных дробей ожидаемое значение произвольной цифры бесконечно, в то время как для второй системы - конечно. Тем не менее, каждая система при наличии достаточного времени будет выдавать произвольно большие цифры.
Другой способ количественной оценки хаоса в динамической системе - это оценка автокорреляционной структуры последовательности (xn). Автокорреляции, близкие к нулю и затухающие очень быстро, связаны с сильно хаотическими системами.
В случае непрерывной дроби автокорреляция lag-1, определяемая как предел эмпирической автокорреляции в последовательности и начинающаяся с, например, x 0 = π - 3, является
Здесь γ - постоянная Эйлера – Маскерони.
Ниже приведено изображение, показывающее последовательные значения p ( x n ) для более гладкой динамической системы, упомянутой выше. Эти значения близки к цифрам d n. начальное условие - x 0 = π - 3.
Первые 5500 значений p ( x n ) для n = 0, 1, 2 и далее показы на изображении. Только подумайте, такими временными рядами можно смоделировать природные, производственные или бизнес-процессы . Возможности безграничны.
Например, он может представлять модель падения метеоритов в течение большого временного промежутка, где несколько больших значений представляют собой массивные столкновения. Очевидно, что он может быть использован при моделировании выбросов, экстремальных событий и рисков.
Другие наши статьи: