Что делать, если данные не хотят объединяться. Рассмотрим типичные действия.
Пусть есть две таблицы, представляющие заработок людей из разных городов (идентифицируются по индексу) и и суммы помощи людям из местного бюджета (для каждого города фиксированная сумма) следующего вида:
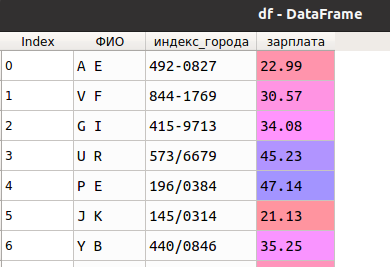
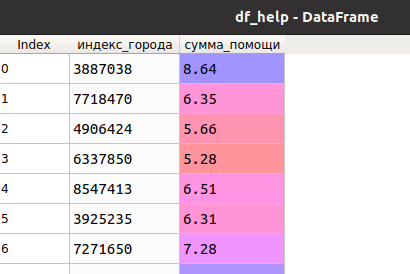
Перед нами стоит задача их объединения, которое, очевидно, производится по индексу города (как я упоминал ранее осуществляется средствами библиотеки Pandas - функцией merge ). В результате получается таблица, в которую попали не все записи из первоначальной:
Выводим, что не попало в объединение
В этой ситуации напрашивается необходимость исследования "проблемных" строк. Для этого следует в обеих таблицах проверить записи, которые не попали в объединение. Это осуществляется с помощью метода isin следующим образом:
Для удобства изучения может потребоваться сохранить записи в файл:
Исследуем значения "проблемного" столбца
После ознакомления с данными, у нас возникают предположения о природе несоответствий. Для вывода таких подозрительных значений воспользуемся векторизованными операциями со строками и проверим наличие в полях символа "-":
Преобразовываем значения "проблемного" столбца
Из последнего рисунка можно предположить, что некоторые индексы городов не участвуют в объединении из-за наличия служебных символов, например, "-". Для преобразования полей можно использовать мощь регулярных выражений:
Получаем нужные подстроки из данных
На данном этапе мы считаем, что все обработали, сделали вывод о том, что индекс города состоит из семи цифр и пытаемся их извлечь из всех полей методом extract :
Как можно заметить, некоторые значения не распознаны, определим какие:
То есть необходимо удалить еще один служебный символ - "/". Это надо было сделать еще на этапе удаления "-":
Пробуем опять объединить данные:
Теперь все получается!