Без правильно подобранных алгоритмов процесс машинного обучения будет неэффективным и долгим. Это как учебные программы в разных ВУЗах: чем круче универ, тем больше вероятность, что ты получишь больше качественных знаний. Так и искусственный интеллект: под каждую конкретную задачу важно выбрать подходящий алгоритм. Их, к слову, немало и выбрать, с каким именно лучше всего работать — вопрос непростой. LabelMe попытается дать наиболее точный ответ, рассказав о самых актуальных алгоритмах обучения ИИ в 2021 году.
Мы не будем детально прописывать каждый алгоритм, иначе у нас бы получился трехтомник. Мы постараемся вкратце охарактеризовать каждый способ обучения и выделить его сильные стороны. Начнем с самых базовых и фундаментальных, а закончим самыми новыми. Погнали.

1. Линейная регрессия (Linear Regression)
Пожалуй, это один из самых универсальных и проверенных временем алгоритмов. В отличие от своего ближайшего собрата — полиномиальной регрессии, этот метод строит прямую линию между наилучшими соответствиями переменных.
Она вычисляется путем минимизации квадратов расстояний между точками и линией наилучшего соответствия. Это еще называют минимизацией суммы квадратов остатка. Следовательно, сам остаток равен предсказанному значению минус фактическое значение. Разберем на конкретном примере.
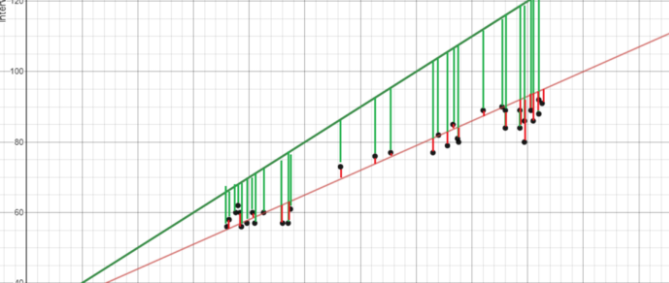
У зеленой линия (наилучшие соответствия) вертикальные линии намного больше, чем у красной. Следовательно алгоритм сам ищет наиболее подходящий маршрут, даже если он отклоняется от точных соответствий. Именно поэтому на линейную регрессию отлично ложатся практически любые задачи, выполняя подсчеты с математической точностью.
2. Логистическая регрессия (Logistic Regression)
Логистическая регрессия по принципу работы похожа на линейную регрессию, но чаще применяется для моделирования вероятности дискретного числа результатов. На первый взгляд, логистическая регрессия кажется намного сложнее, чем линейная, но для ее использования нужно сделать всего одно дополнительное действие.
Сперва нужно рассчитать значение, используя уравнение для построения прямой для линейной регрессии.
Затем ввести результат из сигмовидной функции, чтобы получить вероятность. Ее можно преобразовать в двоичный выходной сигнал: 1 или 0.
Чтобы найти значения исходного уравнения и вычислить их оценку, можно использовать такие методы, как градиентный спуск или максимальное правдоподобие. Таким образом мы сможем прогнозировать вероятность события путем его сравнения с логистической кривой.
3. K-Ближайшие соседи (K-Nearest Neighbors)
Универсальность и популярность этого алгоритма объясняется простотой его концепции. Вы начинаете работу с уже квалифицированными данными (в иллюстрации это синие и красные точки), а затем добавляете новые точки. Их классификация происходит путем сопоставления с другими k-ближайшими точками. Чем больше сходство с одной из них, тем выше вероятность попасть в определенную группу.
В этом случае, если мы устанавливаем значение k = 1, мы увидим, что первая ближайшая точка к серому образцу — это красная точка данных. Следовательно, точка будет классифицирована как красная.
Каким бы простым не казался алгоритм, нужно помнить про некоторые нюансы. Например, слишком низкое значение k может привести к выбросам, а слишком высокое — пропустить классы со схожими приметами.
4. Наивный Байес (Naive Bayes)
Наивный Байес относится к алгоритмам классификации, следовательно он применим, когда выходная переменная дискретна.
Наивный байесовский алгоритм может показаться очень сложным, так как требует предварительных математических знаний в области условной вероятности и теоремы Байеса. Однако, это довольно простой метод, что мы и попытаемся доказать на конкретном примере.
У нас есть входные данные о характеристиках погоды и о том, играл ли человек в гольф в данную погоду. По сути, Наивный Байес сравнивает соотношение между каждой входной переменной и категориями в выходной переменной. Это можно увидеть в таблице ниже.
Упростим пример. В столбце температура и строке жарко, указано конкретное значение — 2/9. То есть в 2 дня из 9 человек играл в гольф. В математическом языке это можно выразить, как вероятность того, что будет жарко, при условии, что человек играет в гольф. Математическое обозначение — P (горячо | да). Это известно как условная вероятность, получив которую мы сможем предсказать, будет ли игра в гольф при любой комбинации погодных условий.
Далее смоделируем новый день со следующими переменными:
- погода: солнечно
- температура: умеренная
- влажность: нормальная
- ветреность: false
Сперва мы вычислим вероятность того, что человек будет играть в гольф при X, P (да | X), а затем вероятность того, что не будет играть в гольф при X, P (no | X).
Теперь мы можем просто ввести эту информацию в следующую формулу:
Получив ответ, повторяем ту же последовательность действий для P (no | X).
Поскольку P (yes | X)> P (no | X), то мы можете предсказать, что этот человек будет играть в гольф при солнечной погоде, умеренной температуре, нормальной влажности и отсутствии ветра.
5. Машины опорных векторов (Support Vector Machines)
Метод опорных векторов — это контролируемый алгоритм классификации, который может показаться достаточно сложным, но при этом очень интуитивным для опытных специалистов. Как минимум поэтому он и попал в эту статью.
Предположим, что есть два класса данных. Support Vector Machines найдет гиперплоскость (границу между двумя этими классами), которая максимизирует границу между ними. То есть может быть много плоскостей, которые могут разделять два класса, но только одна плоскость может максимизировать запас или расстояние между классами.
Алгоритм работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора.
6. Метод случайного леса (Random Forest)
Прежде чем мы начнем углубляться в этот метод, необходимо упомянуть несколько важных терминов по теме:
- Ансамблевое обучение (Ensemble learning) — это метод, в котором несколько алгоритмов обучения используются вместе. Это позволяет достичь более высокой точности прогнозов, чем если бы вы использовали каждый алгоритм отдельно.
- Выборка начальной загрузки (Bootstrap sampling ) — это метод повторной выборки, в котором используется случайный сбор данных с заменой.
- Бэггинг (Bagging ) — когда вы используете совокупность загруженных наборов данных для принятия решения.
Теперь к “случайным лесам”. Это метод ансамблевого обучения, основанный на деревьях решений. Он включает в себя создание нескольких деревьев решений с использованием самонастраиваемых наборов исходных данных и случайным выбором подмножества переменных на каждом шаге дерева решений.
Затем модель выбирает режим всех прогнозов каждого дерева решений. Опираясь на модель “большинство побеждает”, метод снижает риск ошибок в каждом отдельном дереве.
Например, мы создадим четыре дерева решений. Лишь одно предскажет 0, а все остальные — 1, тогда и общее предсказанное значение будет равно 1.
7. AdaBoost (Adaptive Boost)
Однако есть три основных отличия AdaBoost, которые делают его уникальным:
- В основе его работы лежат не деревья решений, а пни (иллюстрация выше). Пень в данном случае — это дерево, состоящее из одного узла и двух событий (листьев).
- Не все пни одинаково влияют на принятие окончательного решения. Чем чаще ошибается пень на ранних итерациях, тем меньше он влияет на финальный прогноз.
- Важна последовательность пней, так как каждая новая итерация направлена на устранений ошибок предыдущих пней.
Таким образом AdaBoost постоянно развивается итеративным способом, исключая допущенные ранее ошибки.
8. Градиентное усиление (Gradient Boost)
Этот алгоритм также является ансамблевым и использует методы повышения для разработки улучшенного предиктора. Во многих отношениях Gradient Boost похож на AdaBoost, но есть несколько ключевых отличий:
- В отличие от AdaBoost, который строит пни, Gradient Boost строит деревья обычно с 8–32 листьями.
- Gradient Boost рассматривает проблему повышения через оптимизацию: он использует функцию потерь и пытается минимизировать количество ошибок.
- Деревья используются для прогнозирования остатков выборок (предсказанных минус фактических)
Gradient Boost начинается с построения одного дерева, чтобы попытаться соответствовать данным, а последующие деревья, построенные после, нацелены на уменьшение остатков (ошибки). Он делает это, концентрируясь на тех областях, в которых существующие учащиеся показывают плохие результаты, как и в AdaBoost.
9. XGBoost ( EXtreme Gradient Boosting)
XGBoost — один из самых популярных и актуальных алгоритмов обучения на данный момент. Секрет кроется в его мощности и скорости. По принципу работы он похож на Gradient Boost и поддерживает все возможности таких библиотек как scikit-learn, но имеет несколько дополнительных особенностей. Среди них:
- Пропорциональное сжатие листовых узлов — используется для улучшения обобщения модели.
- Дополнительные параметры рандомизации — уменьшают корреляцию между деревьями, в конечном итоге улучшая силу ансамбля.
- Newton Boosting — метод Ньютона обеспечивает прямой путь к минимумам. Благодаря этому он намного быстрее, чем градиентный.
Подробнее о работе алгоритма XGBoost можно узнать в видео StatQuest .
10. LightGBM (Light Gradient Boosted Machine)
Несмотря на выдающиеся показатели XGBoost, есть еще более впечатляющие альтернативы. LightGBM — отличный пример.
Этот алгоритм использует метод односторонней выборки на основе градиента (Gradient-based One-Side Sampling — GOSS) и объединения разрежённых взаимоисключающих признаков (Exclusive Feature Bundling — EFB). С их помощью он фильтрует данные и находит раздельные значения.
Проще говоря, он расширяет градиентный бустинг, используя автоматический выбор объектов, и фокусируется на примерах бустинга с большими градиентами.
Этим алгоритм отличается от приведенного выше XGBoost, который использует предварительно отсортированные и основанные на гистограммах алгоритмы для поиска наилучшего разделения.
Заключение
Это топ-10 самых актуальных в текущем году алгоритмов машинного обучения. Несмотря на крутость методов обработки, важно не забывать про качество изначальных данных. Чем точнее они размечены, тем быстрее и эффективнее будет протекать обучение.
Чтобы избежать ошибок конечного продакшена и уменьшить количество итераций, направленных на исправление ошибок, важно правильно подбирать источники датасетов. Бесплатные стоки, равно как и биржи по разметке, могут быть подготовлены со значительными упущениями. Чтобы избежать дополнительных издержек и получить достойный результат, лучше обращаться к опытным поставщикам размеченных данных.
В частности LabelMe осуществляет подготовку датасетов под самые разные задачи. Достаточно просто поставить задачу (в процессе мы даже сами корректируем ТЗ, чтобы добиться лучшего результата) и все остальное сделают наши обученные разметчики. А чтобы заказчик не сомневался в качестве исполнения, LabelMe дает бесплатный тестовый датасет уже через 3 часа после уточнения деталей заказа. Сперва пробуете, потом подписываете договор.