Некоторые функции могут вызывать такие проблемы, как переоснащение и давать неоптимальные результаты в обучающих моделях, понимание того, почему это происходит, имеет решающее значение при разработке моделей. Существует несколько методов решения этой проблемы, в том числе уменьшение размерности, для решения проблем, связанных с редкостью функций.

Что же это за функции?
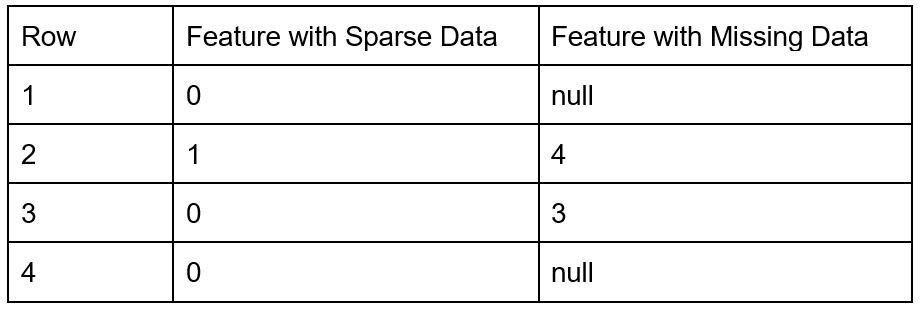
Объекты с разреженными данными - это объекты, которые в основном имеют нулевые значения. Они отличаются от функций с отсутствующими данными. Примеры разреженных функций включают в себя векторы слов или категориальные данные.
В чем разница между разреженными и отсутствующими данными?
Если данные отсутствуют, это означает, что многие точки данных неизвестны. Разреженные, если данные немногочисленны, все точки данных известны, но большинство из них имеют нулевое значение.
Чтобы проиллюстрировать этот момент, есть два типа функций.
Объект с разреженными данными имеет известные значения (= 0), но объект с отсутствующими данными имеет неизвестные значения (= null). Неизвестно, какие значения должны быть в строках с нулевым значением.
Почему машинное обучение плохо работает
с разряженными данными?
Список проблемы :
- Если модель имеет много разреженных элементов, это увеличит пространственную и временную сложность моделей. Модели линейной регрессии будут использовать большое количеству коэффициентов, а древовидные модели будут иметь большую глубину для учета всех функций.
- Алгоритмы модели и диагностические меры могут вести себя неизвестным образом, если функции имеют разреженные данные.
- Если функций слишком много, возникает проблема переобучения. Когда модели переоснащаются, они не могут быть обобщены на новые данные. Это отрицательно сказывается на предсказательной способности моделей.
- Некоторые модели могут не воспринимать важность разреженных элементов и отдавать предпочтение более плотным элементам, хотя разреженные элементы могут иметь предсказательную силу. Древовидные модели печально известны таким поведением. Например, случайные леса переоценивают важность функций категориальных фич.
Методы работы с разреженными объектами
1. Удаление элементов из модели
Разрженные данные могут создавать шум, который улавливает модель,
что увеличивают потребности модели в памяти.Чтобы исправить это, их можно исключить из модели. Например, из моделей интеллектуального анализа текста удаляются редкие слова или удаляются функции с низкой дисперсией.
https://scikitlearn.org/stable/modules/feature_selection.html#removing-features-with-low-variance.
Однако в этом процессе не следует удалять редкие объекты, имеющие важные сигналы.
Регуляризацию LASSO можно использовать для уменьшения количества функций.
2. Сделайте данные более плотными
- Анализ главных компонентов (PCA) - методы PCA могут использоваться для проецирования функций в направлениях основных компонентов и выбора наиболее важных компонентов.
- Хеширование функций - при хешировании функций разреженные данные могут быть объединены в желаемое количество выходных функций с помощью хеш-функции. Необходимо тщательно выбирать большое количество функций вывода, чтобы предотвратить конфликты хешей.
3. Использование моделей от устойчивых до разреженных.
Некоторые версии моделей машинного обучения устойчивы к разреженным данным и могут использоваться вместо изменения размерности данных. Например, энтропийно-взвешенный алгоритм k-средних лучше подходит для этой задачи, чем обычный алгоритм k-средних.
Заключение
Редкие функции распространены в моделях машинного обучения, особенно в форме однократного кодирования. Эти функции могут привести к проблемам в работе моделей машинного обучения, таким как переоснащение, неточная важность функций и высокая дисперсия. Рекомендуется предварительно обрабатывать разреженные функции такими методами, как хеширование функций или удаление функции, чтобы уменьшить негативное влияние на результаты.