Если до сих пор мы с тобой рассматривали нейронки, где информация проходит слой за слоем прежде чем оказаться у потребителя, то теперь я предлагаю рассмотреть еще один, не менее интересный вид - это рекуррентные сети. Не пугайся названия, сейчас все объясню.
Смотри, прошлые сети хорошо подходили для объектов, размер которых нам заранее известен, например картинка 10х10 пикселей. Принимаем на вход 100 пикселей и анализируем их и распознаем картинку. А если нам заранее не известен объем данных или нам важен порядок, в котором мы получаем информацию? Под такие условия попадает, например, анализ текста и наши с тобой любимые переводчики. Кстати, дарю ссылку на клевый переводчик, переводящий круче гугл транслейта: https://deepl.com. Название от слова Deep Learning, как раз про машинное обучение.
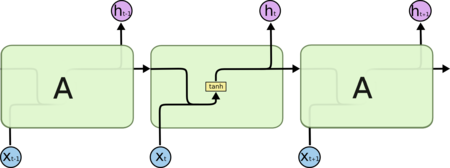
Как же они работают? Традиционно, не буду углубляться в детали, расскажу только общий принцип. В отличии от предыдущих типов нейросетей, в рекуррентных на вход помимо одного значения с предыдущего слоя, идет еще и информация о прошлом состоянии сети. То есть нейроны в таких сетях выполняют гораздо более сложную функцию, чем сетях с прямым распространением, так как учитывают и так называемую “память” сети, позволяющую анализировать не один кусочек данных, а в контексте последовательности. Так что передавай Алисе, Марусе, Сири или Гугл ассистенту, ты теперь догадываешься, как они работают.
Пока что перестану взрывать тебе мозг и прикрою тему машинного обучения. Хочу верить, что было полезно! Так что подписывайся и зови друзей, пусть им тоже станет полезно!