
MLCommons, отраслевая группа, специализирующаяся на оценке производительности искусственного интеллекта и аппаратного обеспечения машинного обучения, добавила результаты новейших ускорителей искусственного интеллекта и ML в свою базу данных и опубликовала первые цифры производительности вычислительных GPU H100 от Nvidia и BR104 от Biren, полученные с помощью стандартного для отрасли набора тестов. Результаты сравнивались с результатами, полученными на Sapphire Rapids от Intel, AI 100 от Qualcomm и X220 от Sapeon.
MLPerf от MLCommons - это набор эталонов обучения и вывода, признанных десятками компаний, которые поддерживают организацию и предоставляют результаты тестирования своего оборудования в базу данных MLPerf. Набор эталонных тестов MLPerf Inference версии 2.1 включает сценарии использования в центрах обработки данных и на периферии, а также такие рабочие нагрузки, как классификация изображений (ResNet 50 v1.5), процессор естественного языка (BERT Large), распознавание речи (RNN-T), медицинская визуализация (3D U-Net), обнаружение объектов (RetinaNet) и рекомендации (DLRM).
Машины, участвующие в этих тестах, оцениваются в двух режимах: в режиме сервера запросы поступают очередями, в то время как в автономном режиме все данные поступают сразу, поэтому очевидно, что в автономном режиме они работают лучше. Кроме того, производители могут представить результаты, полученные в двух условиях: в закрытой категории все должны запустить математически эквивалентные нейронные сети, в то время как в открытой категории они могут модифицировать их в попытке оптимизировать для своего оборудования, сообщает IEEE Spectrum.
Результаты, полученные в MLPerf, описывают не только чистую производительность ускорителей (например, один H100, один A100, один Biren BR104 и т.д.), но и их масштабируемость, а также производительность на ватт, чтобы составить более подробную картину. Все результаты можно посмотреть в базе данных, но Nvidia собрала результаты производительности каждого ускорителя на основе данных, предоставленных самой компанией и сторонними производителями.
Конкуренты Nvidia еще не представили все свои результаты, поэтому в графике, опубликованном Nvidia, некоторые результаты отсутствуют. Тем не менее, мы можем сделать несколько довольно интересных выводов из таблицы, опубликованной Nvidia (однако не забывайте, что Nvidia является заинтересованной стороной, поэтому все следует воспринимать с долей соли).
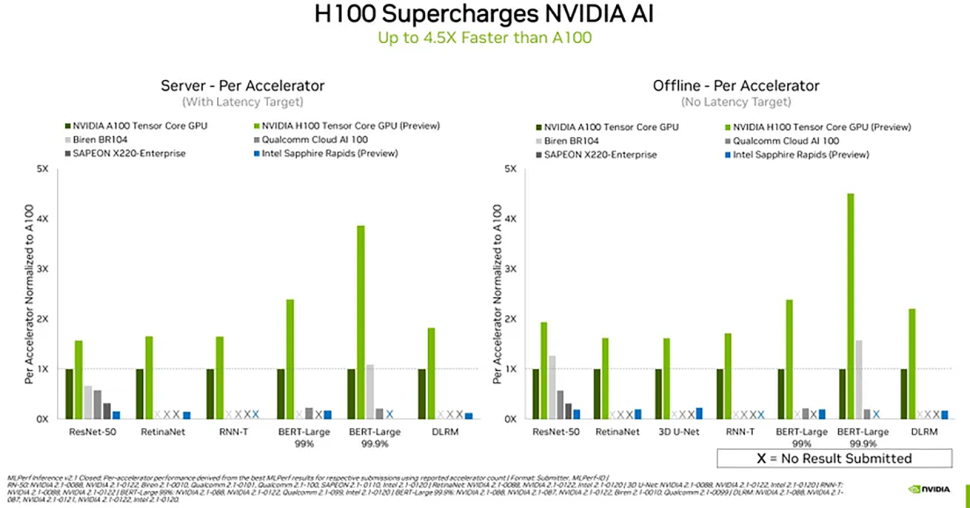
Поскольку H100 от Nvidia является самым сложным и самым передовым ускорителем AI/ML, опирающимся на очень сложное программное обеспечение, оптимизированное для архитектуры CUDA от Nvidia, не особенно удивительно, что на сегодняшний день это самый быстрый вычислительный GPU, который в 4,5 раза быстрее, чем A100 от Nvidia.
Тем не менее, BR104 от Biren Technology, который предлагает примерно половину производительности флагманского BR100, показывает неплохие результаты в классификации изображений (ResNet-50) и обработке естественного языка (BERT-Large). Фактически, если BR100 будет в два раза быстрее BR104, то он обеспечит более высокую производительность, чем H100 от Nvidia в нагрузках классификации изображений, по крайней мере, в том, что касается производительности на ускоритель.
X220-Enterprise от Sapeon, а также Cloud AI 100 от Qualcomm не могут даже прикоснуться к A100 от Nvidia, который был выпущен около двух лет назад. Процессор Intel 4-го поколения Xeon Scalable 'Sapphire Rapids' может выполнять рабочие нагрузки AI/ML, хотя не похоже, что код был достаточно оптимизирован для этого процессора, поэтому его результаты довольно низкие.
Nvidia полностью рассчитывает, что со временем процессор H100 будет предлагать еще более высокую производительность в AI/ML-нагрузках и увеличит свой разрыв с A100, поскольку инженеры научатся использовать преимущества новой архитектуры.
Остается только догадываться, насколько существенно со временем повысится производительность таких ускорителей вычислений, как BR100/BR104 от Biren, X220-Enterprise от Sapeon, а также Cloud AI 100 от Qualcomm. Более того, реальным конкурентом H100 от Nvidia станет вычислительный GPU Intel с кодовым названием Ponte Vecchio, который позиционируется как для суперкомпьютеров, так и для приложений AI/ML. Также будет интересно увидеть результаты Instinct MI250 от AMD - который, возможно, оптимизирован в первую очередь для суперкомпьютеров - в MLPerf, и отсутствие которого в текущих тестах несколько странно. Тем не менее, по крайней мере, на данный момент, Nvidia удерживает корону производительности AI/ML.



















