
Сотни раз приходилось вводить эти цифры на каком-нибудь сайте и никогда не задумывался что за ними стоит. Как сервис проверяет, что вы ввели правильный код? Он что, каждый раз спрашивает у гугла? Да нет же, быть того не может, так никакого гугла не хватит. Действительно, как? Стыдно признаться, но до недавнего времени не задумывался над этим.
И вот, на работе выпала задача по интеграции второго фактора авторизации в нашем SGX-анклаве, а так это embedded и вообще писать надо на C++, то придется разбираться как это работает.
Стоит упомянуть, что не Google Authenticator-ом единым - существуют альтернативы. Порой даже более удобные альтернативы, которые позволяют делать бэкап в облако (если вы пользуетесь Google Authenticator и потеряете телефон, то уже ничего не восстановите, surprise!). Отдельного упоминания стоят мои коллеги, которые пользуются консольными скриптами для получения этих кодов.
Но ближе к делу. Когда вы устанавливаете двухфакторную авторизацию на каком-то сервисе, то вы договариваетесь о ее параметрах:
- Секретное значение. Это случайная строка, что-то вроде вашего ключа к этому сервису.
- Время жизни одноразового пароля. Обычно это 30 секунд, но может быть любое значение. Да, ровно столько крутятся кружки в приложении.
Как правило, эти параметры зашиваются в какую-нибудь ссылку вида:
otpauth://totp/example.com:user.email@gmail.com?secret=CSKKJDJHKJWEPIOU39G&issuer=example.com
и эта ссылка передается вам в виде QR-кода.
Далее приложение вычисляет значение счетчика:
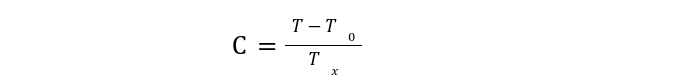
Где T - текущее время в unix timestamp (количество секунд, прошедших с 1 января 1970 года), T0 - начало отсчета, обычно используют 0, и Tx - время жизни одноразового пароля. Округляется все в меньшую сторону. Простыми словами С - это сколько одноразовых паролей прошло бы со времени T0.
Далее вычисляем значение выбранной HMAC-функции (обычно это HMAC_SHA1). Для простоты можно думать о HMAC-функции как о хэше с паролем (секретным значением, которое выдал нам сервис):
Если описать суть происходящего дальше коротко, то мы просто берем для нашего кода значения байт из случайных мест полученного MAC:
Получили смещение, с которого будет наполняться наш код. Оно носит случайный характер, т.к. никто не может предсказать каким будет последний байт хэша. Дальше наполняем сам код:
Таким образом мы получили 4х-байтовое значение кода, которое нужно привести к 6 цифрам, то есть значению до миллиона. Для этого просто берут остаток от деления:
Ровно эти 6 цифр мы и видим в приложениях для двухфакторной аутентификации. Далее сервис на своей стороне вычисляет точно такой же код на основе текущего времени и сравнивает его с тем, что прислал ему пользователь.
Mystery solved, как говорится. Все оказалось крайне просто - любой желающий может реализовать этот алгоритм как он описан здесь (я так и сделал), т.к. википедия описывает его гораздо сложнее.
PS. Главное успеть ввести код за 30 секунд!