Случайными кажутся события, причины которых мы не знаем (Демокрит).
При кросс-валидационной проверке качества модели установка ее случайного инициализатора в целочисленное значение может понизить вариацию в данных. В этом случае на всех сплитах тестируется качество только одной случайной настройки алгоритма. Если же передать объект класса np.random.RandomState, то на каждом fit-е алгоритм будет подбирать разные случайные параметры.
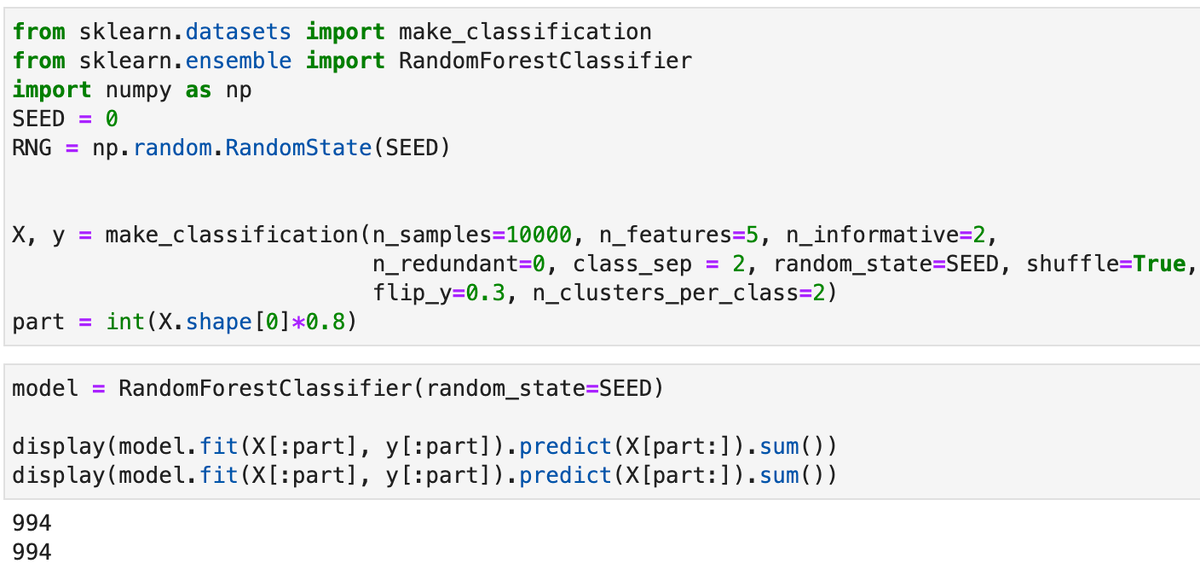
Целочисленный сид создает одинаковые модели и получает равные результаты. Для демонстрационных целей выше выведена сумма предсказаний.
А ниже то же с использованием RNG:

Такое поведение обусловлено тем, что после первого вызова fit RNG изменяется. Соответственно, так как при кросс-валидационной оценке на каждом fit-е получается немного иная вариация нашего оценщика, итоговое качество будет статистически устойчивее и меньше зависимо от случайных величин.
С учетом этого, результаты кросс-валидации при задании random_state=RNG и целым - random_state=SEED будут отличаться:
Таким образом, чтобы повысить статистическую достоверность кросс-валидации, используйте вместо целочисленного сида объект np.random.RandomState.