Описание системы
Cassandra — это отказоустойчивая распределенная NoSQL СУБД. Она разрабатывалась инженерами Facebook и основной фокус был на создании системы без единых точек отказа, способной легко масштабироваться и обслуживать базы с петабайтами данных. Помимо этого, система должна была выдерживать высокий рейт на запись без деградации времени чтений.
Иными словами, Cassandra задумана как eventually consistent система, а в терминах CAP-теоремы её можно выразить как AP систему.
Особенности архитектуры
Каждая таблица в базе данных представляет из себя набор словарей, индексируемых при помощи строкового ключа. Элементы внутри этого словаря (или column family) именуются колонками. Каждая колонка состоит из трех частей: имени, значения и таймстемпа, последние нужны для разрешения write-конфликтов. Чем таймстемп больше, тем новее считается запись в таблицу.
В отличие от многих распределенных систем с Master/slave архитектурой, все узлы в кластере Cassandra равноценны. Преимуществом такого решения является отсутствие боттлнека при масштабировании: новые узлы можно легко вводить в кластер.
Данные между узлами распределены равномерно при помощи consistent hashing, что позволяет легко масштабировать кластер. Суть этого механизма заключается в том, что значения хеш-функции представляют из себя замкнутое кольцо: каждый узел кластера случайным образом выбирает себе точку на этом кольце и хранит в себе все данные в диапазоне, заканчивающемся в этой точке и начинающемся предыдущей точкой другого узла на этом же кольце. Благодаря этому, при добавлении или удалении узлов кластера удаётся перепартицировать лишь данные этого узла, не затрагивая соседние.
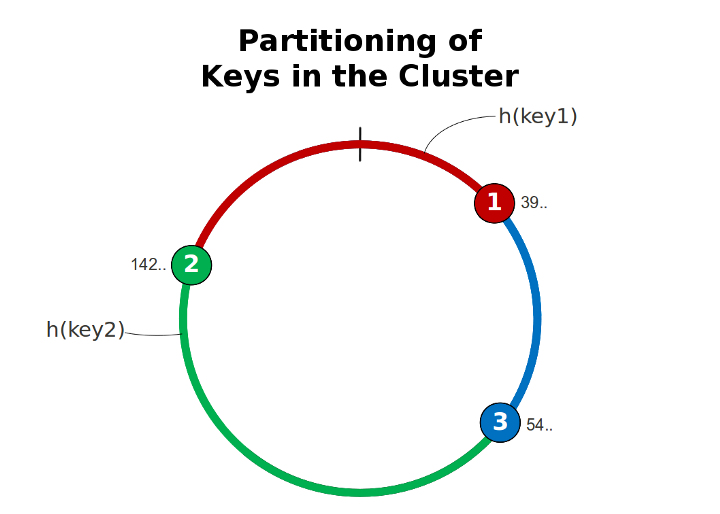
К примеру, на Рисунке 1 добавление нового узла приведёт к разделению самого длинного интервала на 2 равные части. Тем самым, узел 4 возьмёт на себя ответственность за часть данных узла 2. Все остальные данные при этом не будут затронуты.
Репликация
В Cassandra разработана довольно гибкая система репликации.
Во-первых, для каждой таблицы есть возможность задавать replication factor (RF) — количество узлов, на которые данные будут реплицированы. Координатор запроса — узел, на который пришёл запрос пользователя, - отвечает за репликацию запроса на другие кластера. Он определяет, к какому диапазону относится данный запрос и перенаправляет данные пользователя к узлу, ответственному за этот диапазон, а также выбирает другие RF - 1 узел, на которые нужно отправить данные.
Во-вторых, Cassandra также позволяет задавать политики репликации с учётом топологии кластера. При включенной политике данные будут реплицированы на разные серверные стойки/датацентры. Координатор учитывает это при подборе узлов для репликации. Отметим, что здесь используется Zookeeper для хранения информации об узлах и диапазонах, за которые эти узлы ответственны. Для этого в Cassandra есть лидер, которых хранит всю информацию и следит за тем, чтобы на каждом узле находилось не более RF - 1 диапазона.
Также в Cassandra можно задавать уровень консистентности при репликации — он характеризует количество синхронных реплик при репликации. Понятно, что оборудование имеет привычку ломаться и из-за этого дождаться ответа от всех реплик часто представляется невозможным. Поэтому данные обычно синхронно реплицируются на Кворум из реплик (1 + replicas count // 2) и асинхронно на оставшиеся узлы. При этом, для недоступных узлов координатор записывает локально Hinted Handoff — подсказку для отсутствующих узлов о недошедшем до них запросе. Когда ноды подсоединятся к кластеру, координатор отправит им эту подсказку.
Помимо Кворума, в Cassandra можно также задавать уровень консистентности Any/One/Two/Local Quorum и другие.
О консистентности
Поговорим про особенности работы системы Cassandra при конкурентных модификациях одного ключа в таблице.
В статье от DataStaх был рассмотрен алгоритм, построенный на векторных часах. Этот механизм использовался в системе Dynamo и его суть состоит в том, что каждый узел хранит свою собственную версию часов. Далее, во время запроса на чтение координатор зачитывает состояние из реплик. В случае конфликтов координатор возвращает пользователю несколько версий одной записи и разрешение конфликтов ложится на пользователя. Этот подход становится слишком тяжелым в случае сложных конфликтов и поэтому в Cassandra эта проблема решена иначе.
Как уже было сказано выше, консистентность регулируется задаваемым уровнем консистентности при записи, а также важную роль играют таймстемпы. При обновлении колонки в базу записывается новое значение вместе со свежим таймстемпом. Cами таймстемпы могут генерироваться либо изнутри Cassandra, либо предоставляться пользователями извне. Также как и с записями, в чтениях тоже есть возможность задания уровня консистентности. Помимо этого, при чтении используется подход last-write-wins: координатор запроса опрашивает несколько реплик и возвращает пользователю значения с самым свежим таймстемпом. В случае равенства таймстемпов, выбирается лексикографически большее значение.
Данный механизм борьбы с конфликтами не всегда является консистентным. В анализе от jepsen io было продемонстрировано наличие dirty write аномалии в системе Cassandra. Эта аномалия была вызвана коллизией двух таймстемпов, имеющих микросекундную точность. Дело в том, что использование физического времени накладывает определенные ограничения, одним из которых является точность: если в качестве таймстемпов используются микросекунды, то существует вероятность коллизии двух таймстемпов, что и было продемонстрировано в эксперименте jepsen. Поэтому, для гарантий изоляции, генератор таймстемпов обязан возвращать уникальные таймстемпы - в некотором роде логические часы.
В упомянутой выше статье DataStax написан неплохой разбор двух методов разрешения конфликтов и описана мотивация, стоящая за выбором метода в Cassandra, но при этом в аргументах не указаны факты о проблемах консистентности подхода. Для полноты анализа в статье стоило указать о таких аномалиях и объяснить читателю, как их избежать.
Заключение
Анализ СУБД Cassandra показывает, что у этой системы есть свои преимущества и недостатки и, к сожалению, она не везде применима.
Cassandra заточена под write-intensive нагрузки с высокой доступностью, но достигается это за счёт потери консистентности. Поэтому использование Cassandra в областях, где важна строгая консистентность, не представляется возможным. Как показало исследование jepsen io, в Cassandra были баги даже в аннонсированных lightweight транзакциях, которые должны были частично закрыть отсутствие ACID транзакций.
Помимо этого, архитектура системы не предназначена для аналитических запросов. По сути, Cassandra — это мощная Key-Value СУБД, где значения схематизированы. Она хороша для лукапов и селектов, но более сложные запросы на ней не удастся оптимально написать из коробки.
В остальных случаях Cassandra представляет из себя мощную высокодоступную систему с удобными механизмами кросскластерной репликации. Это может быть очень полезно при построении геораспределенных кластеров.
Источники:
1. https://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf
2. https://aphyr.com/posts/294-jepsen-cassandra
3. https://youtu.be/qQLOofy8SYI
4. https://medium.com/@brunocrt/the-distributed-architecture-behind-cassandra-database-fba8b5cc4785
5. https://www.bigdataschool.ru/wiki/cassandra
6. https://www.datastax.com/blog/why-cassandra-doesnt-need-vector-clocks