Скорый кризис транзисторных процессоров в начале 1990-х казался неизбежным. И пока в одних лабораториях альтернативу искали, проектируя квантовые алгоритмы и экспериментируя с кубитами, в других — двигали компьютеры на биомолекулах. В 1994 году практически одновременно ученые собрали первый квантовый вентиль и решили первую задачу с помощью ДНК. Но к тому, чтобы двигаться дальше, одни «альтернативные айтишники» были готовы лучше, чем другие. Проектировать квантовые компьютеры начали задолго до появления кубита. Еще в 60-х теоретики занялись квантовой информатикой, а к 80-м уже думали о квантовых алгоритмах, возможном устройстве логических вентилей на кубитах, а экспериментаторы собирали разнообразные прототипы кубитов. А над теорией ДНК-вычислений никто специально не работал. Там сразу начали решать конкретные вычислительные задачи.
К концу XX века биохимики научились проводить с молекулами ДНК уже довольно много процедур. Считывать с них информацию, расплетать двойную цепочку, сплетать обратно, добавлять к последовательности новые нуклеотиды, заменять один нуклеотид на другой, резать цепочку в нужном месте и сшивать. На транзисторы классических компьютеров, равно как на кубиты квантовых и их логику, вся эта биохимия непохожа. Но не видеть вычислительного потенциала в таком «натуральном» способе работы с информацией ученые не могли.
Леонард Адлеман и задача коммивояжера
В последовательности химических реакций можно разглядеть логическую схему. На входе одно вещество, на выходе — другое. Или несколько, но в определенном соотношении. Поэтому если правильно подобрать реакции, то строение и количество получившихся молекул может кодировать решение какой-то задачи.
Первым, кто понял, что имеющихся у биологов инструментов уже хватает для вычислений, стал математик Леонард Адлеман, один из создателей системы шифрования RSA (Rivest — Shamir — Adleman). Познакомившись в начале 1990-х с миром ДНК, ученый, по его собственным словам, «отчетливо увидел» аналогию между нуклеиновой логикой и транзисторной логикой компьютерных процессоров — и уже в 1994 году опубликовал статью об эксперименте, в котором нуклеиновые кислоты решили задачу о гамильтоновом цикле на графе.
Это частный случай NP-полной задачи коммивояжера (о полиномиальных и неполиномиальных задачах мы говорили в материале «Удаленное доказательство»). В задаче коммивояжера определенное количество точек на карте надо соединить самой короткой траекторией, ни одну из них при этом не пропустив. В задаче поиска гамильтонова пути надо просто доказать, что траектория, которая соединяет все точки и проходит через каждую ровно один раз, существует. Вычислитель Адлемана искал решение для графа с семью узлами.
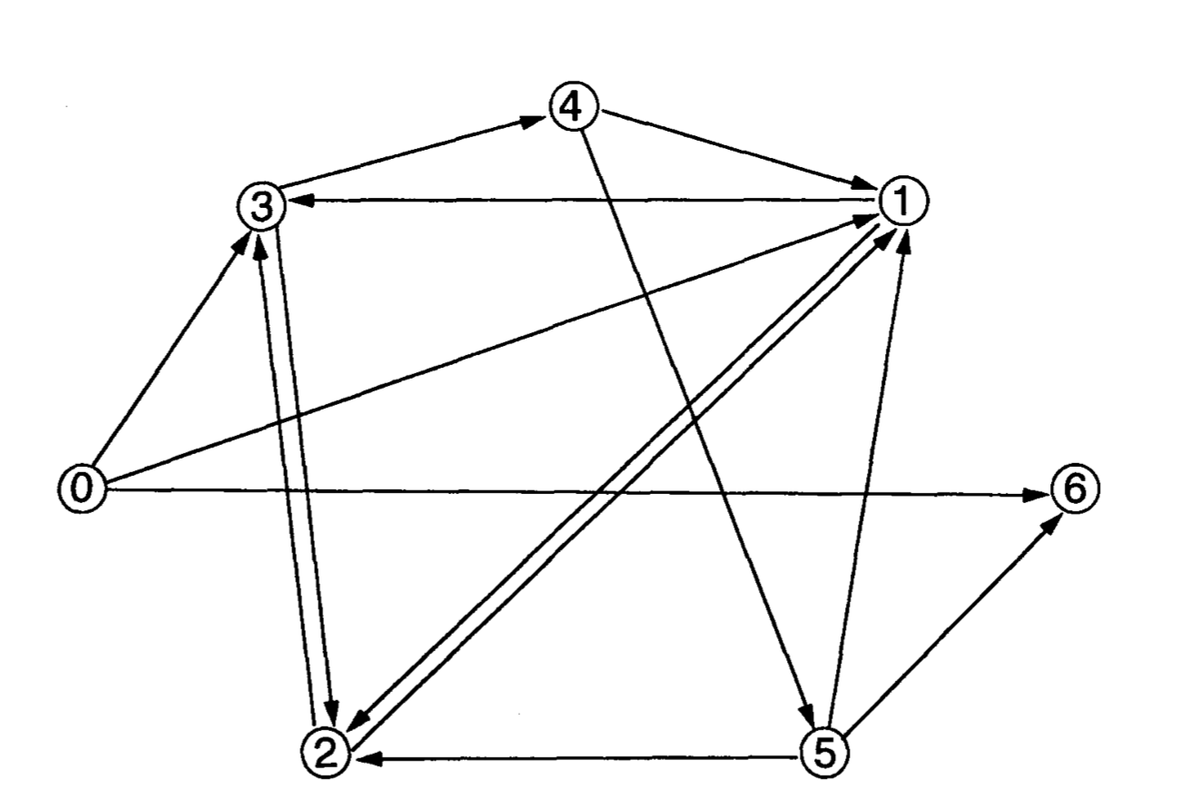
В этом ДНК-вычислителе каждому из узлов графа соответствовала случайная молекула из 20 нуклеотидов. Соответственно, ребра графа, то есть соединения узлов, складывались из двух половинок: первые десять звеньев — 3′-хвост молекулы одного узла, а вторые десять — 5′-хвост второй. Ребра таким образом становились векторами: i→j-последовательность нуклеотидов отличалась от j→i-последовательности. Это и нужно для того, чтобы синтезировать непрерывные траектории, последовательно идущие через узлы графа.
Биопроцессор Адлемана использовал ДНК в качестве носителя информации, а для операций над ней — полимеразу и лигазу, которые, соответственно, синтезировали новые цепочки нуклеиновых кислот и сшивали их друг за другом.
Как работает алгоритм Адлемана ↓
ДНК-алгоритм включает пять этапов, моделирует возможные перемещение по графу и отбирает из этих траекторий нужные:
Этап 1. Сначала в форме ДНК кодируют все возможные переходы между узлами графа. Чтобы закодировать переход из точки i в точку j, смешивают растворы двух олигонуклеотидов: один должен быть комплементарен всем 20 нуклеотида узла i, а второй кодирует ребро i→j (то есть вторая десятка нуклеотидов i и первая десятка нуклеотидов j). Первый олигонуклеотид прилипает к 10 нуклеотидам i в составе второго, и получается пара «узел-ребро». И так — для всех возможных комбинаций узлов и выходящих из них ребер.
Все эти скрепленные цепочки смешивают, они слипаются друг с другом случайным образом, а с помощью лигазы эти конфигурации фиксируются. В результате получают множество молекул разной длины конфигурации «...-узел-ребро-узел-ребро-...» разной длины, которые соответствуют возможным траекториями между узлами графа.
Этап 2. Смесь молекулярных траектрий многократно копируют с помощью ПЦР — с использованием двух праймеров: одного — для нулевого узла, второго — комплементарного к шестому. Таким образом из всего набора траекторий выбирают только те, которые приводят из нулевого узла в шестой.
Этап 3. Затем из цепочек, отобранных на втором этапе, с помощью электрофореза на агарозном геле, выбирают молекулы нужной длины — только те, в которых ровно 140 нуклеотидов, то есть которые побывали ровно в семи узлах.
Этап 4. Дальше с помощью коротких одноцепочечных нуклеотидов, пришитых к магнитным частицам, последовательно отбирают те траектории, которые проходят через первый, второй, третий и остальные узлы. То есть те, которые удовлетворяют основному условию задачи и проходят через каждый узел.
Этап 5. Отобранных цепочек получается мало, и невооруженным глазом их не увидеть. Чтобы убедиться в том, что они остались в растворе, там снова запускают ПЦР и многократно эти цепочки копируют — после этого их уже можно рассмотреть на электрофорезном геле.

Расчеты, которые сам Адлеман в уме производил за минуту, у его компьютера заняли неделю. Это был успех — наивный эксперимент продемонстрировал принципы ДНК-вычислений. Работа стала основополагающей для всего направления «дезоксирибонуклеинового IT» и следующие несколько лет вдохновленные примером Адлемана ученые строили аналогичные ДНК-схемы для решения похожих комбинаторных задач.
Оценки показывали, что если правильно спроектировать эксперимент и минимизировать потери времени на лабораторные процедуры, то для решения NP-полных задач компьютер на ДНК может оказаться эффективнее классической машины. Компьютер Адлемана проводил больше тысячи операций с производительностью 100 терафлопс — классические компьютеры достигли таких показателей только к 2005 году.
Квантовые машины в те времена ничего решать не умели, так что даже компьютерами называться не могли. И ДНК-вычислители, несмотря на отсутствие теоретической базы (которая у квантовых как раз была), оказались на несколько шагов впереди. Их архитектура позволяла проводить огромное число параллельных вычислений в виде одновременных реакций молекул друг с другом. Оставалось найти под такие возможности подходящие задачи.
Логические вентили
Эстафету у Адлемана принял информатик-теоретик Ричард Липтон. В 1995 году он приспособил еще одну NP-полную задачу для вычисления в пробирке. В его эксперименте перед нуклеиновыми кислотами ставился вопрос о выполнимости булевых формул — нужно было доказать, что формулу, в которой есть только булевые переменные (то есть которые могут принимать значение 0 или 1), скобки и операторы И, ИЛИ и НЕ, можно выполнить. То есть найти набор значений, при которых формула оказывается верной.
Эта задача отличается от задачи с графом, которую решал вычислитель Адлемана. Но Липтон не придумал ничего нового в архитектуре ДНК-процессора. Вместо инженерной задачи он решил чисто математическую — как свести задачу выполнимости к задаче на графе. Так что никаких принципиальных модификаций в оригинальный ДНК-вычислитель вносить не пришлось.
Классическая машина решает задачу о выполнимости булевой формулы с n переменными, просто перебирая по очереди 2n ее вариантов на истинность. Алгоритм Липтона делает ровно то же самое, никакого процедурного ускорения в нем нет: ДНК-процессор справляется быстрее просто потому, что распараллеливает этот перебор.
Как работает логика в алгоритме Липтона ↓
Липтон предложил схему проверки для формулы, в которой всего две переменные, две пары скобок и пять операторов. То есть его экспериментальная установка проверяла выполнимость сравнительно простой функции для четырех вариантов входных данных. Все логические операторы собирались вручную — под формулу составлялся граф, проходя по узлам которого ее можно проверить на истинность. Но Липтон показал, как этот подход можно легко расширить и на более общий случай.
В основе алгоритма Липтона, как и у Адлемана, — гибридизация, то есть самопроизвольное соединение комплементарных цепочек. Липтон составил граф, движение по которому моделирует последовательный перебор значений переменных, отобрал нужные траектории и сел смотреть, что получается на выходе. Если там есть хотя бы одна молекула нужной длины, значит формула выполняется — и задача, соответственно, решена.
В такой гибридизационной ДНК-логике ферменты задействованы только как вспомогательные элементы — логика строилась без их активного включения. Без селективности ферментов базовые функции, на которых можно было построить алгоритм, фактически ограничивались набором из «соединять», «разделять», «определять наличие». Это «родные» операции ДНК со своим протоколом действий и смыслом, привычную нам бинарную логику с операторами типа И и ИЛИ можно надстроить поверх нее, и прямой связи с происходящим уровнем ниже в ней не будет.
Основное достоинство этой логики — в параллельных вычислениях. Универсальных вентилей, которые без потери их функционального смысла можно было бы перенести в любой другой ДНК-вычислитель, в процессоре Липтона не было. Схема выглядела перспективной: в отличие от последовательных классических вычислителей, ДНК-алгоритм сокращал объем информации на каждой стадии, превращая перебор в фильтрацию. Сначала параллельно создается огромный массив данных для всех значений переменных, который затем делится на «хорошую» половину и «плохую». Хорошие нуклеиновые кислоты продолжают размножаться и сохраняются в системе, а от плохих алгоритм избавляется, таким образом отделяя решения от нерешений. Классические вычислители так не могут.
В 1996 году нуклеотидный процессор научили складывать двоичные числа. В 1997 — он решил задачу поиска в графе максимальной клики — то есть такого набора вершин графа, в котором все со всеми попарно соединены. В 2001 году Эхуд Шапиро, еще один классик теории программирования, запатентовал полноценную машину Тьюринга, основанную на ДНК-вычислениях с помощью ферментов. Построена она на тех же принципах, которые развивали Адлеман, Липтон и другие энтузиасты.
Перспектива проводить параллельные ДНК-вычисления сразу на триллионах или даже квадриллионах молекул вселила в ученых надежду на решение NP-полных задач, слишком тяжеловесных для последовательных вычислений на классическом компьютере.
Все задачи, которые к тому моменту решили нуклеиновые кислоты, брались из классической информатики. Поэтому и ставились перед нуклеотидами на языке двоичной логики — и решались, соответственно, на нем же. Хотя, как и для квантовых вычислений, двоичная система для ДНК-платформы не очень естественна: в молекулах ДНК четыре разных нуклеотида, а не два.
Но полноценно возможности четверичной нуклеотидной логики в этих схемах не использовались. Если проблему перевода информации из двоичного кода в четверичный в контексте ДНК вскоре изучили довольно подробно, то вопрос о том, как из четверичных элементов строить логические вентили, оставался совсем мало проработанным. Молекулы были способом представления битов. Много молекул с нужной структурой — единица, мало — ноль.

Разочарование
Скептические комментарии по поводу будущего ДНК-платформ зазвучали еще в 1994 году, сразу после выхода статьи Адлемана. И во многом были справедливы. К 2000 году проблем с ДНК-процессорами накопилось достаточно много, чтобы перспективы нуклеотидных вычислителей перестали казаться радужными. Их можно разделить на четыре группы.
Физические ограничения. Адлеман решил задачу поиска гамильтонова цикла на семи узлах за неделю в нескольких пробирках. Чтобы решить такую же задачу хотя бы на двух десятках узлов, по расчетам, нужны уже килограммы ДНК. А универсальному вычислителю для решения комбинаторных задач, по некоторым оценкам, нужно еще почти на 50 порядков больше олигонуклеотидов — примерно 1070 молекул.
Область применения. Физические ограничения сужают и горизонт возможностей молекулярных машин: задачи, которыми изначально планировали их загружать, вероятнее всего, для них неподъемны. Так, дешифрование данных, закодированных по классическим протоколам, — задача, которую сейчас хотят решать на квантовых вычислителях, — для ДНК не под силу. На взлом 256-байтного ключа будет нужно 101233 цепочек ДНК — и компьютер объемом примерно 101216 литров. Это примерно 101208 Каспийских морей. Стало понятно, что вместо прямого переноса известных задач для нуклеиновых кислот надо искать другие.
Накопление ошибок. О том, что ошибки могут заглушить всю процедуру вычислений, беспокоился еще Липтон — в своей пионерской статье он назвал их основной проблемой на пути к созданию полноценного ДНК-компьютера. Годы спустя эти вычислители так и остались очень плохо масштабируемыми. 99-процентная точность, которая для одной операции кажется более чем приемлемой, для сотни последовательных действий становится уже меньше 40 процентов.
Неуниверсальность. Каждая из предложенных схем ДНК-процессора в лучшем случае была машиной Тьюринга, собранной под одну конкретную логическую задачу. В каждой есть определенный набор элементов, определенный протокол действий, они не ограничены во входной информации — и способны уверенно решать конкретную логическую задачу. Но только ее.
В то же самое время забуксовали и квантовые соперники ДНК-вычислителей. В конце 90-х лидерами квантовой гонки были компьютеры, которые производили вычисления с опорой на ядерно-магнитный резонанс. А в итоге столкнулись примерно с теми же проблемами. В 2001 году на ядерных спинах собрали схемы для выполнения алгоритма Шора сразу из семи кубитов — значительно больше, чем у всех альтернативных квантовых платформ. Но дальнейшее масштабирование оказалось невозможным из-за слишком высокого уровня шума. Сейчас о квантовых вычислителях на ядерно-магнитном резонансе вспоминают лишь как об историческом казусе — весь дальнейший прогресс связан с системами, которые в начале века сильно отставали.
В итоге об универсальных ДНК-компьютерах в начале 2000-х говорить перестали, а теоретики компьютерных наук постепенно переключились на другие задачи. Адлеман выпустил в XXI веке всего несколько статей про ДНК-вычисления и самосборку биомолекул в компьютерном контексте, Ричард Липтон сфокусировался на чисто математических и компьютерных исследованиях, а Эхуд Шапиро, хотя и продолжил выпускать статьи по «живой» логике, со временем переключился с ДНК на другие био-логические элементы — клетки.
Параллельные ошибки
Область, несмотря на общий пессимизм, не зачахла. Но фокус исследований сместился. В вычислениях на молекулах оставалось слишком много ошибок, и все еще оставалось непонятно, как их масштабировать и универсализировать. Поэтому на место математиков пришли биохимики, молекулярные биологи и биоинформатики, которые вместо того, чтобы работать над базовыми принципами логических схем ДНК-вычислителя, занялись усовершенствованием молекулярного инструментария.
В частности, для решения некоторых комбинаторных задач стали активнее использовать прикрепление олигонуклеотидов к подложке. Это позволило упростить масштабирование логических схем: после логической операции нужные олигонуклеотиды остаются пришитыми к твердой поверхности и их можно использовать дальше, а лишнее просто вылить вместе с раствором. А негибридизованные одноцепочечные молекулы (то есть тоже лишние) отдать на съедение экзонуклеазам кишечной палочки.
Впрочем, полностью избавиться от ошибок таким образом не удалось. Больше пяти процентов лишних цепочек оставались на поверхности после нескольких циклов очистки. Поэтому главная проблема, присущая ДНК-вычислителям, оставалась нерешенной.
Другие ошибки, мутационные, также продолжали накапливаться в ходе многостадийных вычислений. Бороться с ними ученые предлагали двумя способами: либо всеми возможными способами предотвращать их, либо брать работающие с ошибками схемы и устранять в них последствия этих ошибок.
Для сокращения их числа пытались подбирать оптимальную скорость реакций, управляя температурой и концентрацией реагентов, или, например, отсеивать олигонуклеотиды с ошибками. Эти варианты, впрочем, также не были универсальными, а придумывались под конкретные задачи и сильно зависели от процедуры и от платформы, на которой работает вычислитель (а к тому времени типов ДНК-процессоров было уже не меньше пяти).
Исправлять мутационные ошибки предлагали либо на этапе работы с ДНК, либо при секвенировании, либо во время обработки информации уже в цифровом виде. В отдельных случаях справляться с последствиями естественных мутаций и паразитного сигнала удавалось довольно успешно, но и придумать универсальные методы так и не удалось: для каждой конкретной задачи приходилось разрабатывать свой способ устранения проблемы.
В поисках более универсального и точного способа считать на ДНК биохимики стали перебирать альтернативы гибридизации, которой пользовались Адлеман и Липтон.
Некоторые ученые отказались от ферментативных реакций. Сначала Милан Стоянович и Дарко Стефанович стали вместо ферментов использовать дезоксирибозимы — олигонуклетиды с функциями ферментов. Например, с помощью дезоксирибозима с функцией рибонуклеазы, способного разрезать молекулы РНК, они сделали вычислитель с 23 последовательными логическими вентилями и научили его играть в крестики-нолики на поле три на три.
Замещая замещением
А затем биохимики придумали логику на каскадах замещения цепи (strand displacement cascades). Эта схема основана на самосборке молекул ДНК и обратимом комплементарном связывании одноцепочечных олигонуклеотидов, и если все пройдет как надо, то пробирка с ДНК начнет светиться. Медиаторы в этой схеме — не ферменты, а другие нуклеотидные последовательности. Рабочий олигонуклеотид, который несет нужную информацию, присоединяется к вспомогательным олигонуклеотидам, которые работают вентилями.
Олигонуклеотид, который попадает в систему в форме ввода, запускает каскад реакций замещения цепи между теми реагентами, которые уже находятся в системе, и передает таким образом сигнал. Конечным шагом этой цепочки реакций становится связывание одной из нуклеиновых кислот с красителем, в результате которого устройство начинает светиться. Ничего резать или копировать в такой схеме не нужно, а значит не нужны и ферменты. Оттого и дополнительные ошибки от работы ферментов в процессе вычислений не возникают.
Такая платформа удовлетворяет базовым критериям архитектуры логической цепи: здесь реализованы логические функции И, ИЛИ и НЕ, они могут выполнять разветвленные и каскадные алгоритмы, имеют блочную структуру и могут восстанавливать сигнал. Это уже не однозадачная машина Тьюринга. А в 2011 году ученые еще и показали, как эту схему можно масштабировать, добавив в нее «качельные» (toehold) вентили, которые за счет обратимой реакции замещения цепи в нужный момент переносят статус «активного» с одного олигонуклеотида на другой. И если до этого начальное состояние вычислителя включало не больше 12 разных молекул ДНК, то за счет модификации это число увеличилось до 74. Таким образом удалось значительно увеличить производительность вычислителя: схема, в которой суммарно на разных стадиях было 130 разных олигонуклетодов, могла уже считать квадратные корни четырехзначных двоичных чисел.
Нейросети из ДНК ↓
Нейросеть из ДНК сделали в том же 2011 году на базе уже существующих логических вентилей в каскаде замещения. Она извлекала нули и единицы из концентрации олигонуклеотидов с определенной последовательностью: выше порога 1, ниже — 0. По мнению авторов, эта нейросеть должна была в результате производить реагенты для последующих биохимических реакций. Но конструкция оказалась слишком громоздкой и сложной, поэтому серьезного развития эта идея не получила. По данным Google Scholar, у этой работы почти тысяча цитирований, но в большинстве из них она упоминается как красивая работа с необычным подходом. Вернулись к идее нейросетей из ДНК только на фоне ажиотажа уже в конце 2010-х, но не для логических задач: использовать нуклеиновые нейросети сейчас предлагают для распознавания молекул или диагностики болезней.
Но на фоне этих успехов число энтузиастов ДНК-вычислений продолжало неумолимо сокращаться. Никаких значительных прорывов ни в бесферментных, ни в гибридизационных вычислениях не произошло. После 2010 года цитировать классические статьи Адлемана и Липтона в научной периодике стали все меньше и меньше.
Сейчас одни ученые продолжают совершенствовать качельную логику и каскадные схемы, другие вернулись к идее использования ферментов, третьи объединяют эти подходы. Например в 2019 году биохимики собрали из полимеразы и нескольких ДНК-вентилей единый арифметический элемент и частично решили проблему сборки интегральных схем. А другие научили свой процессор считать квадратные корни из 900.
Но судя по количеству публикаций, от прежнего воодушевления уже ничего не осталось. Несмотря на отдельные успехи, вычислительные возможности логических элементов из ДНК так и остаются крайне ограниченными, и никаких чудес от технологии никто не ждет. Она просто продолжает тихо развиваться как независимая логическая платформа.
Подходящие информационные задачи для ДНК все же нашлись ↓
Нуклеиновые кислоты остаются очень эффективным способом кодирования информации — на элементах сразу с четырьмя возможными значениями: А, Т, Г и Ц. Поэтому вместо того, чтобы строить на ДНК компьютеры, молекулярный биолог Джордж Черч предложил использовать их в качестве носителя информации. В простейшей схеме каждой паре двоичных чисел — 00, 01, 10, 11 — сопоставляется один нуклеотид. Одно только это дает возможность сократить запись в два раза, а если перейти к кодированию информации в четверичной системе счисления — по числу различных нуклеотидов — то паковать данные можно будет еще плотнее. Пока что чаще используется промежуточный вариант: двоичный код переводят в ДНК с помощью системы кодирования, используя троичную систему счисления.
Молекулы нуклеиновых кислот, если их не перегревать, очень устойчивы. Поэтому если не давать им участвовать ни в каких реакциях, случайных ошибок в них не возникнет. Переносить данные с полупроводниковых носителей на нуклеотидные и обратно можно практически со стопроцентной точностью — в 2016 году на ДНК записали 200 мегабайт данных, а в 2018-м Massive Attack переиздала свой альбом Mezzanine в виде пробирки с ДНК.

Биологика
Все вычислительные задачи для ДНК за тридцатилетнюю историю так и не вышли толком за пределы бинарификации последовательности биохимических реакций. Несмотря на обилие технических ухищрений, широкий арсенал операций и внушительную информационную емкость носителя, логика задач, предлагаемых нуклеиновым кислотам, сводилась к двоичной, а сигнал — к бинарному выводу, много ли в итоговой смеси нужных молекул (1) или мало (0).
Квантовые компьютеры благодаря суперпозиции не только расширили возможности двоичной логики просто за счет того, что не нужно перебирать огромное число вариантов, а еще и предложили принципиально новые алгоритмы. С ДНК ученые фактически просто ускорили этот перебор за счет параллельных вычислений.
Помимо этого, квантовые процессоры используют не только для того, чтобы сконструировать универсальный вычислитель. Сегодня они в первую очередь занимаются тем, что транзисторам дается с трудом: например моделированием квантовых систем и решением оптимизационных задач. Аналогичную нишу искали и для ДНК-процессоров.
Логика ДНК строится на химических реакциях, поэтому и применять ее логично не где-то для алгебраических вычислений, а где-то в области химии. А с учетом того, что базовая вычислительная логика молекулам ДНК тоже уже доступна, можно использовать их как промежуточное звено между цифровым интерфейсом и молекулами-участниками химической реакции и управлять таким образом молекулярными машинами и нанороботам.
Например, с помощью той же самой схемы каскадного замещения биохимики научились управлять белковыми нанороботами. На выходе в ДНК-логической цепи получаются аптамеры, небольшие олигонуклеотидные молекулы, которые связываются с целевыми белками и управляют ими. Из небольших олигонуклеотидных молекул делают программируемые химические контроллеры, «ДНК-роботов» используют для сортировки молекул, для управления роем микротрубочек или биороботами.
А еще — ДНК-оригами ↓
Еще одна ветвь ДНК-IT начала активно развиваться уже после разочарования в нуклеиновой логике — это ДНК-оригами, создание сложных трехмерных молекулярных структур заданной формы с фиксированным расположением нуклеотидов и пришитых к ним частиц и биомолекул.
В 2003 году казалось , что если с двумерными структурами из ДНК еще можно работать, то с трехмерными — практически невозможно. Изгибы и петли нуклеотидных спиралей очень тяжело контролировать, поэтому устойчивых трехмерных структур из них не получить. За 15 лет с помощью ДНК-оригами уже научились получать объемные фигуры строгой формы размером до 50 мегадальтон. Изначально на эти технологии не ставили, но сейчас по проработанности инструментария они опережают и ДНК-запись, и тем более — ДНК-компьютеры.
Сейчас роботов из ДНК-оригами используют в качестве элементов универсальных компьютеров, для управления физическими системами и в медицинских целях. Под каждую такую задачу сейчас отдельно придумывают нужную последовательность, набор соединительных элементов. Но потенциально программируемые ДНК-оригами можно интегрировать в какие-то логические цепочки — молекулярные или классические.
Управление с помощью ДНК биохимическими процессами с участием других нуклеиновых кислот, белков и неорганических частиц, впрочем, уже относится не столько к вычислительным системам, сколько к синтетической биологии. С помощью управляемых элементов из ДНК компьютер можно научить управлять синтетическими клетками. В том числе встраивая в них какие-то компоненты, нехарактерные для живой клетки, но с которыми умеет управляться человек: упорядоченные системы диполей, спинов, оптические или даже сверхпроводящие элементы.
Когда в 90-е годы «информатики-теоретики» в предвкушении кризиса полупроводниковых компьютеров стали искать новые платформы для вычислений, они решали свои, вполне конкретные, проблемы, а не придумывали задачу для нового инструмента. Реальность же оказалась немного иной. Современные квантовые компьютеры, которые удается интегрировать с классическими, конечно, помогают и в вычислениях. С задачами оптимизации квантовые компьютеры справляются увереннее классических (подробнее об этом читайте в тексте «Разминка для кубита»). И пользу от квантовых компьютеров извлекают физики, а не информатики, — моделируя на них квантовые системы.
Решение вычислительных задач на биомолекулярных компьютерах выглядит еще более неуклюжим, чем на квантовых. И их будущее — скорее за молекулярными роботами и системами биохимического контроля. За биомолекулярным превосходством тоже охотятся, но уже на более высоком уровне. Например, в синтетической биологии в качестве вычислительных элементов биомолекулярных компьютеров предлагают использовать искусственные клетки, а возможность на них решать более сложные задачи называют «клеточным превосходством». Это значительно более сложные системы: на молекулы ДНК здесь ложится информационная нагрузка, а за логику отвечают клетки. Но и они нужны далеко не за тем, чтобы что-то считать.
Собрать из нуклеиновых кислот суперкомпьютер мы не смогли. Зато научились использовать то, что они совершенно точно делают очень хорошо. Возможно и впредь, вместо того, чтобы переучивать кого-то, стоит внимательнее изучить их возможности — и потребности.