Сегодня — немного общеизвестных сведений о параллельных вычислениях. О чем идет речь? Об использовании более, чем одного вычислительного устройства, для решения задачи. Ничего нового: еще во времена арифмометров расчеты вели параллельно несколько расчетчиков. Очень многое зависит от алгоритма, и тут могут возникнуть сюрпризы. Например, уравнение бегущей волны в виде "производная по времени равна производной по пространственной переменной" можно решить аналитически: это f(t+x), где f(x) — начальное распределение. Но допустим, мы этого не знаем, и хотим решать численно. Для этого введем сетку с шагами h и τ: это точки (ih,jτ). Производные можно приблизить отношением разностей, но можно использовать явную схему, а можно неявную. О чем идет речь? Производная по пространству пусть на слое j, а вот производную по времени можно приблизить как "этот слой j+1 минус слой j" — это явная схема, или как "слой j минус слой j-1" — это неявная схема. Могут быть схемы и более сложные. Явная схема называется так потому, что следующий слой выражается явно через предыдущий. В неявной надо решать систему уравнений, так как неизвестные значения на слое j перепутаны друг с другом.
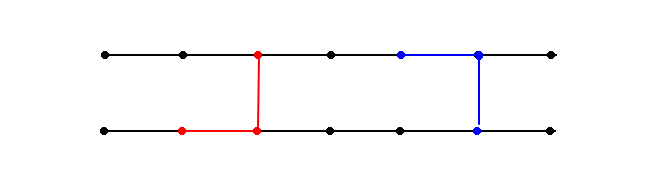
Понятно, что явная схема удобнее для параллельного расчета, но неявная устойчивее, так как неизбежные ошибки не накапливаются. Явная же схема может "развалиться" при слишком больших шагах по времени по сравнению с шагом по пространству. И порой выгоднее взять шаг поменьше, но считать явно на ста процессорах, а иногда лучше взять шаг побольше и схему понадежнее (неявную).
***
Как объяснить простыми словами, почему неявная схема надежнее? Производная по пространству, хоть и вычисляется приближенно, всё-таки производная. А она очень чувствительна к шумам. Это очень понятно, если трактовать производную как тангенс угла наклона касательной: функция может быть маленькой по величине, но иметь почти вертикальную касательную.
Возьмите Asin(Nx) при маленьком А и большом N: функция по величине не превосходит А, что совсем мало, а вот производная достигает значений NA, что может быть и очень много. Или просто возьмите ломаную из звеньев, идущих под большим углом к оси х. Вроде пилы. Зубцы будут малы, а наклон у них почти 90 градусов, то есть тангенс наклона сколь угодно большой.
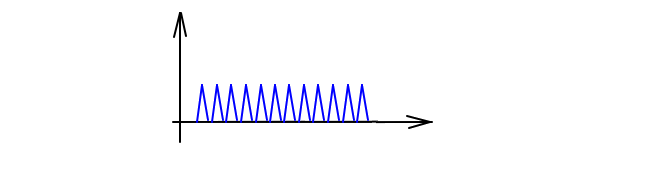
Прибавление такого маленького по величине шума к вашей функции мало меняет ее значения, но до неузнаваемости меняет ее производную. Механически тоже можно: при сильных вибрациях вибрирующее тело почти неподвижно, его положение меняется очень незначительно, а вот скорости и ускорения могут быть сколь угодно велики.
В явной схеме мы берем производную от функции на данном слое. Надо ее умножить на шаг по времени и прибавить к тому, что имеем. При наличии шумов, даже малых, в производной могут возникнуть ошибки уже побольше, и они перейдут на следующий слой. Единственная надежда — погасить их малым шагом по времени. Отсюда и жесткие требования к нему.
Неявная же схема выражает производную на следующем слое через значение на этом. Получается система уравнений, в правой части которой некоторый шум. Всяко может быть, но часто ошибка в решении имеет такой же порядок, как ошибка в правой части, то есть не усиливается. И поэтому неявная схема устойчивее: она не усиливает погрешности, которые всегда есть, а порой и подавляет их.
Подробнее в другой раз обсудим.
***
Какое ускорение можно получить, располагая неограниченными вычислительными ресурсами? Казалось бы, сколь угодно большое, но реальность намного унылее.
Всё зависит от того, насколько параллелится ваш алгоритм. Какую-то часть можно "раскидать" по процессорам, какую-то нельзя. Если можно всё, то тогда да: ускорение сколь угодно велико. Таков переборный поиск на большом множестве: ищи себе, вся сложность в том, чтобы раскидать различные задачи по различным процессорам.
Но как правило, в алгоритме есть какая-то часть, которую необходимо выполнять последовательно. Хотя бы раздавать задачи и собирать результаты. Но обычно кое-что ещё.
Например, можно ли распараллелить приготовление борща? Да, можно параллельно чистить и крошить овощи; может быть, можно даже исхитриться вдвоем одну свеклу чистить - но все равно, полсвеклы надо почистить, и это не параллелится.
Помню, знакомая из Казани рассказывала про красивую традицию, когда все соседи идут в горы, там готовят какой-то особый суп... "Суп готовят только мужчины. Женщины только помогают чистить овощи и разделывать курицу...". Это так мило звучало...
Давайте обозначим эту нераспараллеливаемую долю через S; тогда 1-S можно выполнить параллельно на n процессорах, ускорив в n раз. И время выполнения будет пропорционально S+(1-S)/n. Ускорение — это отношение этой величины для n=1 и для данного n; получается
При больших N это весьма близко к 1/S.
Таким образом, если у вас половина алгоритма не параллелится, то более, чем вдвое, вы не разгоните никак, хоть Ломоносов или Млечный Путь (или что там у нас в TOP-50 сегодня?) вам подавай. И это предел, а так даже меньше.
Если у вас 10% не параллелится, то ускорить можно в 10 раз. И так далее. Причем это предел, и чем меньше S, тем труднее приблизиться. Например, пусть S=1%. Тогда предельное ускорение — сто раз, но на ста процессорах вы получите лишь 1/(0.01+0.99/100)=100/(1+0.99)≈50.
Это мы еще не говорили о расходах на обмены. Если алгоритм хорошо распараллелен, процессы "бегут" параллельно, но время от времени обмениваются информацией. И эти обмены небесплатные. Хотя в суперкомпьютерах накладные расходы невелики, скоростные системы связи работают быстро. Тем не менее, за этим тоже надо следить.
Кстати. Скорость современного процессора порядка гигафлопсов, то есть в миллиардах операций (вроде умножения) в секунду. Если соседний процессор в трехстах метрах, то обмен с ним займет не менее одной миллионной секунды, что эквивалентно тысячам операций. А реально большие суперкомпьютеры могут занимать такое пространство, да и скорость сигнала в проводах поменьше, чем света в вакууме, да и отправка сигнала — дело долгое. Но даже если между процессорами три метра — это десятки операций.
Вернемся к вопросу устойчивости расчета, то есть выбору схем, не усиливающих ошибки. Есть такое общее условие Куранта: за шаг по времени возмущение не должно уйти дальше, чем на шаг по пространству. Это связывает шаги и максимальную скорость рассчитываемых процессов.
Например, скорости течения в океане — это десятки сантиметров в секунду, в крайнем случае метры. Больше бывает редко и, если, то это серьезная головная боль. Быстры течения в Мессинском проливе, между Италией и Сицилией, и этот пролив иногда "закапывают", чтобы эти течения не ломали расчет.
Это там мифические Сцилла и Харибда (см. Scilla в Италии), хотя пролив не так и опасен.
Если у нас шаг по пространству один километр, то время прохода ячейки составляет порядка тысячи секунд. И шаг по времени должен быть такой же величины, или меньше. Иначе численная ошибка, пусть и маленькая, проскочит в ячейку, которая с этой никак не связана, и начнет развиваться по своим законам; если она увеличится, то уже увеличенная вернется в эту ячейку, и это плохо кончится. И даже неявная схема не спасет.
Теперь представим себе, что у нас есть неограниченные ресурсы и сказочно быстрый интерконнект. Мы хотим посчитать весь мировой океан на тысячи лет с шагом в один метр! Можем?
Можем, если есть данные, подробная карта дна и многое другое. Но вот что плохо: какой шаг по времени? Если максимальная скорость даже метр в секунду, то шаг по времени нельзя брать более одной секунды. Процессоров у нас много, и мы можем посадить одну ячейку сетки на свой процессор. Интерконнект у нас быстрый, и затрат на коммуникацию нет.
Всё хорошо? Да, но мы вынуждены считать тысячу лет с шагом в одну секунду. Это 30 миллиардов шагов по времени. Процессов в океане много, то есть шаг по времени состоит из целого ряда расчетов. Если он займет миллисекунду, то считать вы будете целый год. Со всеми вашими неограниченными ресурсами и быстрой связью. Если за секунду ваш процессор сможет сделать миллион шагов (а это вряд ли, поверьте, даже тысяча в секунду — это достижение), то тысячу лет вы будете считать несколько часов. А в атмосфере, скажем, скорости в десятки метрв в секунду — норма...
И никуда, никуда нам не деться от этого: мы же сделали все предположения! И параллелится у нас всё-всё-всё, и процессоров сколько угодно, и накладных расходов никаких...