В предыдущей статье мы начали цикл статей про матричное программирование. Многие ответы вы сможете найти там. А сегодня решим задачу масштабирование набора данных.
Если вы не знаете, что такое масштабирование, для чего оно нужно, то вам сюда. Нам же надо знать, что на выходе мы должны получить такой же набор данных, только эти данные не должны превышать 1, и не быть меньше 0. Другими словами нам надо выполнить те же действия, что и функция MinMaxScaler библиотеки sklearn (раздел preprocessing). Вопрос изобретения велосипеда обсуждался в предыдущей статье, если вас это беспокоит, то вернитесь к ней.
Как мы будем масштабировать данные от 0 до 1? Для каждой колонки (параметра) получим максимальное и минимальное значение по этой колонке. Масштабированное значение будет равно разнице исходного значения и минимального по этому столбцу, поделенному на разницу между максимальным и минимальным значением этого столбца. Для наглядности давайте разберем на примере. Допустим у нас есть такой набор данных:
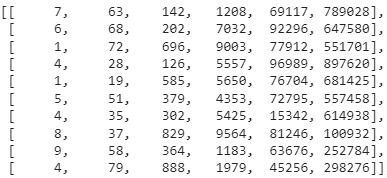
Напишем алгоритм масштабирования в классическом виде:
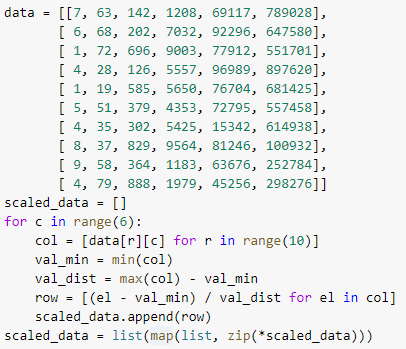
Мы проходим по всем колонкам (их количество 6). С помощью list comprehension формируем вектор значений текущего столбца. Этот вектор нужен для нахождения минимального и максимального значения, а потом для цикла вычисления масштабированного значения, которое заносится в массив масштабированных значений. Беда этого массива в том, что он повернут, то есть там, где должны быть столбцы, там строки и наоборот, поэтому в последней строке производится транспонирование матрицы.
Алгоритм плохой, хотя бы потому, что используется 3 цикла, причем 2 из них вложенные в первый цикл. Для большого набора данных его необходимо оптимизировать. Посмотрите теперь на функцию, использующую матричное программирование:
Нам нет необходимости проходить по всем колонкам, чтобы получить максимальное и минимальное значение в каждой, вместо этого мы получаем вектор максимальных значений с помощью функции max из библиотеки numpy. Особое внимание обратите на параметр axis=0, который не все правильно интерпретируют. По умолчанию этот параметр равен None, в этом случае функция возвращает максимальное значение по всем осям. В нашем же случае функция вернет вектор максимальных значений по нулевой оси (ось строк), то есть длина вектора будет соответствовать количеству столбцов. Вот тут и начинается путаница. От себя могу порекомендовать только одно: проверяйте свои предположения. То же самое относится к вектору минимальных значений. Обе эти функции наглядно демонстрируют удобство работы с матричными функциями.
Следующая демонстрация приемов матричного программирования относится к математическим операциям с матрицами. На примере возврата функции data_scale мы можем оценить наглядность арифметических операций с матрицей data и векторами vmin и vmax. Оба вектора имеют длину равную количеству колонок в матрице, что первоначально может ввести в ступор: вектора имеют только нулевую ось, которая равна первой оси матрицы. Не только векторы можно использовать в матричных вычислениях, это могут быть и значения и матрицы. Но сейчас мы рассматриваем только вычитание из матрицы вектора (data - vmin) и вычитание вектора из вектора (vmax - vmin).
Можете проверить - результат будет точно таким же в классическом алгоритме. Кроме наглядности, numpy-программирование выигрывает в скорости, но это становится заметным только на больших данных. Конкурентом по скорости является только библиотека tensorflow, и то только при работе на графическом процессоре. Эту библиотеку мы пока трогать не будем, потому как: нельзя объять необъятное, но это не значит, что не надо обниматься.