Подробный мануал от Sphinx IT о составлении файла robots.txt: как адаптировать под требования поисковых систем, найти на сайте и написать с нуля. Два способа поиска мусорных страниц для блокировки. Дефолтный шаблон. Управляйте индексацией своего ресурса грамотно.
Что и для чего
Robots.txt — документ в текстовом формате с инструкциями для поисковых роботов. Перед началом сканирования сайта, боты ищут файл роботс, чтобы понимать на что не стоит тратить время при обходе.
Необходим он для того, чтобы в индекс не попадали лишние страницы, которые не несут необходимой информации ни для поиска, ни для пользователя и нам не нужно их нахождение в выдаче.
Есть такое понятие как краулинговый бюджет — лимит url’ов, доступных для обхода роботом на один заход, который определяется для каждого ресурса по-разному. Проще говоря вместо того, чтобы сканировать страницу с восстановлением пароля, следует дать страницу новой статьи из блога.
Где найти
Где лежит robots.txt в WordPress? В самой админке его по умолчанию нет, док находится на ftp хостинга в корневой папке.
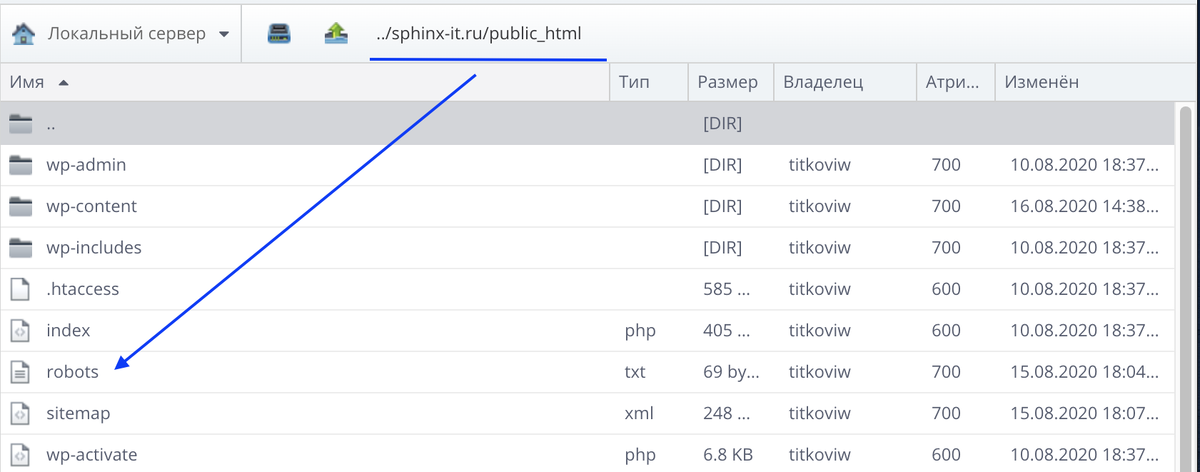
Что содержит
Примеры страниц для блокировки:
- поиск по сайту,
- страницы личного кабинета (логин, регистрация, восстановление пароля и проч.),
- корзина, оформление и благодарность за заказ,
- параметры сортировки, фильтрации, сравнения, wish листы,
- дубли,
- мусорные страницы,
- недостаточно качественные страницы,
- профили зарегистрированных,
- вход в админку,
- также мы всегда закрываем страницы с информацией о персональных данных.
Шаблон
Ниже мы составили пример базового файла robots.txt для цмс WordPress — здесь список команд, которые есть на любом сайте. На основе этого файла можно вносить индивидуальные директивы.
User-agent: *
Allow: *.js
Allow: /wp-content/*.js
Allow: /wp-includes/*.js
Allow: *.css
Allow: /wp-content/*.css
Allow: *.jpg
Allow: /wp-content/*.jpg
Allow: *.png
Allow: /wp-content/*.png
Disallow: /author/
Disallow: /*?
Disallow: /wp-admin/
Disallow: /wp-content/
Disallow: /wp-includes/
Sitemap:
После инструкции для всех роботов из примера выше идут персональные инструкции для поисковых систем Яндекс и Google с названием User-agent: Yandex и User-agent: Googlebot соответственно. Содержание инструкций друг от друга практически не отличается (если не предусмотрено стратегией продвижения).
В робот тхт иногда указывают ссылку на карты сайта, но это не обязательно — в каждом кабинете вебмастера его можно загрузить напрямую.
Как сделать
Правильный robots.txt для WordPress создаётся в программе Блокнот (а лучше в Notepad++). В него вносим все код-команды, сохраняем под именем robots, загружаем на фтп, удостоверившись, что он сохранился в формате txt в нижнем регистре. Вносить изменения можно в любое время и применяются они моментально. После загрузки он будет доступен по ссылке robots.txt после домена, например, http://sphinx-it.ru/robots.txt.
Со всеми командами для обхода можно ознакомиться в помощи от каждой поисковой системы.
Особенности некоторых директив
Директиву Crawl-delay (таймаут загрузки между страницами для роботов в секундах) использовать не рекомендуем, т.к. это почти всегда приводит к проблемам индексации. Если вы задумались, что такая директива нужна — меняйте хостинг.
Крайне важно следить за знаками пробелов и перевода строки. Пробелы ставим только между командами, например, Disallow: пробел инструкция. Ни в конце строки, ни в начале их быть не должно. Перевод строки используем только между блоками команд для робота: написали инструкцию, разделили, тем самым обозначили конец правил для поискового робота.
Каждая команда пишется на новой строке.
Знак звёздочки* в роботс.тхт — компонент регулярного выражения для последовательности любых символов в месте, где они обычно находятся. Например, в нашем robots.txt для Вордпресс инструкция *.jpg означает любые знаки файла jpg-формата, а /wp-includes/*.js символы, расположенные между https://sphinx-it.ru/wp-includes/ и js.
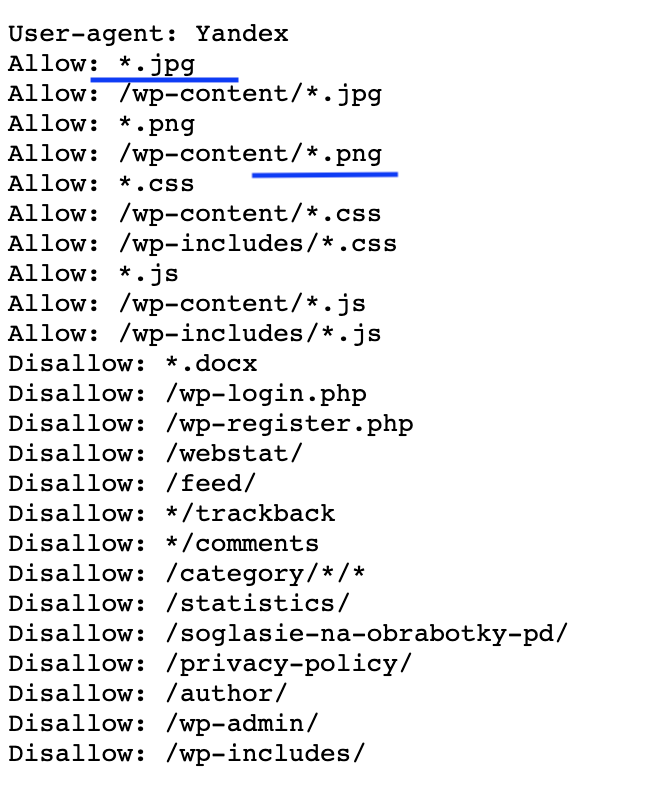
Бывает, что в инструкции допущены ошибки (видели и такое, что один неверный знак полностью закрыл сайт от индексации), поэтому проверить стоит напрямую у роботов в сервисе для вебмастеров.
Плагины
Существует множество плагинов для Вордпресс, которые в режиме реального времени обновляют ваш файл роботс, но использовать их мы крайне не рекомендуем. Проще всего потратить некоторое время на изучение этого инструмента и дополнять его по мере возможности (раз в два месяца, например), чем плодить их избыток, что создаёт повышенную нагрузку на хостинг и негативно сказывается на скорости работы сайта. Собственно, именно поэтому здесь мы их рассматривать не будем.
Что нужно закрыть
Если вы готовите роботс тхт в Вордпрессе впервые и не знаете что происходит внутри сайта, то рекомендуем два способа.
Способ раз
- парсинг всех страниц сайта (например, с помощью Screaming Frog Seo Spider);
- после остановки процесса сбора пробегаем глазами все урлы на предмет лишних или неестественных знаков и соотносим между собой со строками Content и Status code (если используете Лягушку);
- вносим изменения в robots.txt, прогоняем через вебмастера, перезапускаем парсер для проверки.
Способ два
Проверить качество индексации мы можем и в выдаче самой поисковой системы по домену. Ищем подозрительные страницы и закрываем их от индекса.
Авторский материал агентства Sphinx IT специально для Дзен.
И как обычно, ждём комментарии!