В четверг IBM представила новый набор инструментов с открытым исходным кодом на Гитхабе, предназначенный для разработчиков и специалистов по обработке данных, которые хотят помочь выявить тенденции в продолжающейся пандемии COVID-19 . Используя удобные для разработчиков ноутбуки Jupyter, эти наборы инструментов призваны дать толчок к углубленному анализу. Например, пользователь может проанализировать данные на уровне округа, чтобы найти корреляции между уровнями бедности и уровнями инфицирования.
«IBM и наша команда верят в важность демократизации технологий, стимулируя разработчиков самыми современными наборами данных и инструментами, которые могут помочь политикам принимать наиболее обоснованные решения для благосостояния граждан», - говорит Фредерик Рейсс, главный архитектор Центр открытых данных и технологий искусственного интеллекта IBM, пишет в блоге.
Набор инструментов собирает и очищает данные COVID-19 из авторитетных источников, форматируя их для анализа с помощью таких инструментов, как Pandas и Scikit-Learn. В COVID ноутбуки основаны на данных из некоторого ключа, авторитетные источники: Для данных уездных из США, IBM опирается на данные из COVID-19 хранилище данных , в ведении Центра систем науки и техники (КОТБ) в университете Джона Хопкинса.
В дополнении к этой информации, инструментарий опирается на данные из The New York Times коронавирус (Covid-19) Данных в США хранилища и газете New York города дайджест из ежедневных отчетов из Департамента здравоохранения и психической гигиены города Нью-Йорка. Для других стран ноутбуки используют данные Европейского центра по профилактике и контролю заболеваний о географическом распределении случаев COVID-19 по всему миру .
Ноутбуки загружают наборы данных по мере их запуска, поскольку они меняются ежедневно. Более того, условия лицензии для наборов данных запрещают коммерческим организациям распространять эти данные.
Чтобы помочь пользователям своевременно обновлять свои записные книжки, IBM также создала конвейеры обработки данных. Например, как показано на рисунке ниже, пользователь может построить конвейер для данных временных рядов на уровне округа для Соединенных Штатов. Каждая коробка представляет собой блокнот Jupyter. Пользователь может щелкнуть стрелку на панели инструментов над рабочим процессом, чтобы отправить весь набор записных книжек в облако. Оттуда все записные книжки работают на конвейерах Kubeflow, и результаты сохраняются в хранилище объектов облачного провайдера.
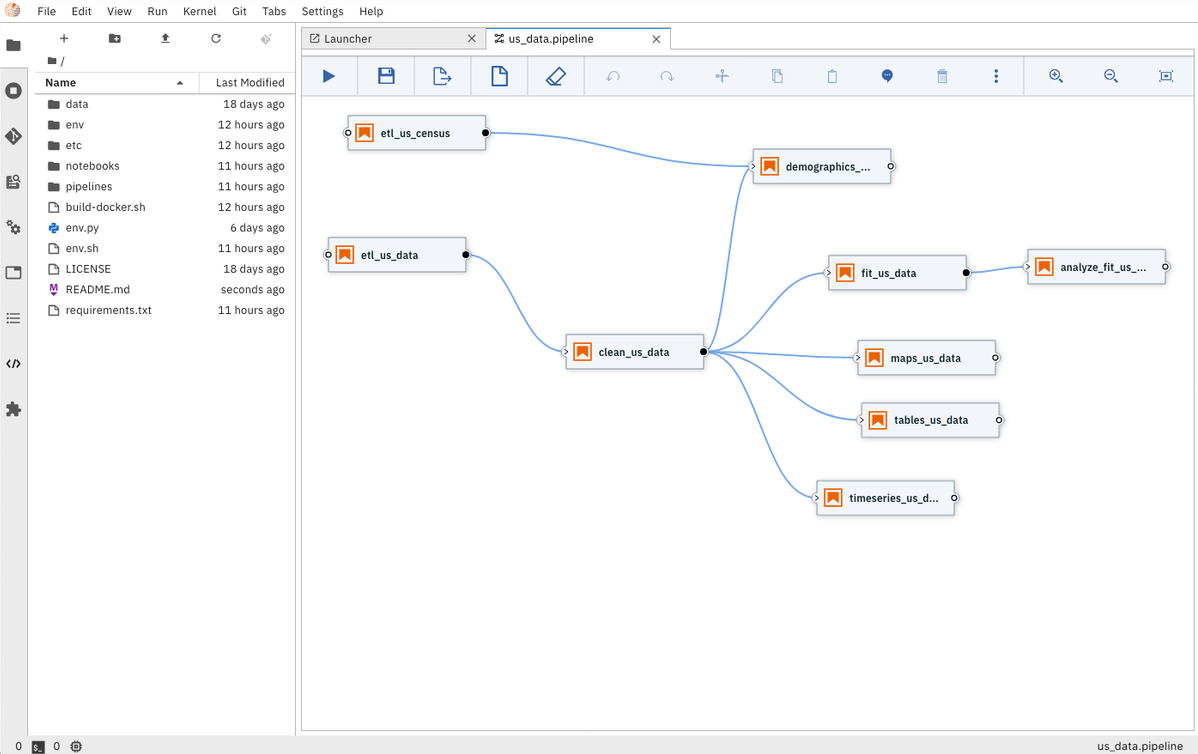
«Важно отметить, что базовые данные для COVID-19 меняются ежедневно», - пишет Рейсс. «Создавая собственный анализ, вы захотите часто обновлять результаты своих собственных записных книжек».