Сегодня разбираем задачу по просьбе Читателя. Вот она:
вводится строка, состоящая только из латинских букв в любом регистре. Нужно получить другую строку, применив к исходной следующие правила:
1. Удалить все гласные буквы (гласными считать A E Y U I O как строчные, так и прописные.
2. Перед каждой согласной буквой поставить точку.
3. Все прописные буквы сделать строчными.
Давайте делать. Объявляем константы и переменные
const
glasn: set of char = ['A','a','O','o','U','u','E','e','I','i','Y','y'];
var
s1, s2: string;
i: integer;
Здесь glasn - множество гласных букв;
s1 - исходная строка;
s2 - преобразованная строка;
i - переменная для цикла;
Вводим исходную строку и "обнуляем" преобразованную
begin
readln(s1);
s2:=''; (напоминаю, что символ заключается в апострофы, поэтому здесь два апострофа, а не кавычки!)
Корректность введенных данных проверять не будем, желающие могут дополнить программу.
Далее начинаем посимвольно идти от начала к концу и проверять символы на принадлежность к согласным буквам (принадлежность к согласным определяется как НЕ принадлежность буквы к множеству гласных)
for i:=1 to length(s1) do
if not (s1[i] in glasn) then
begin
Добавляем точку к преобразованной строке (условие №2 задачи)
s2:=s2+'.';
Далее проверяем, является ли очередная буква прописной, и если да - меняем ее на строчную, а если нет - просто оставляем (условие №3). Вот тут начинается самое интересное. Да, существуют встроенные функции преобразования регистра UPCASE и LOWCASE, но последняя, которая нам как раз и нужна, реализована не во всех версиях Паскаля. Поэтому делаем смену регистра самостоятельно. Для этого надо вспомнить таблицу кодировки символов ASCII, а точнее - её часть с латинским алфавитом:
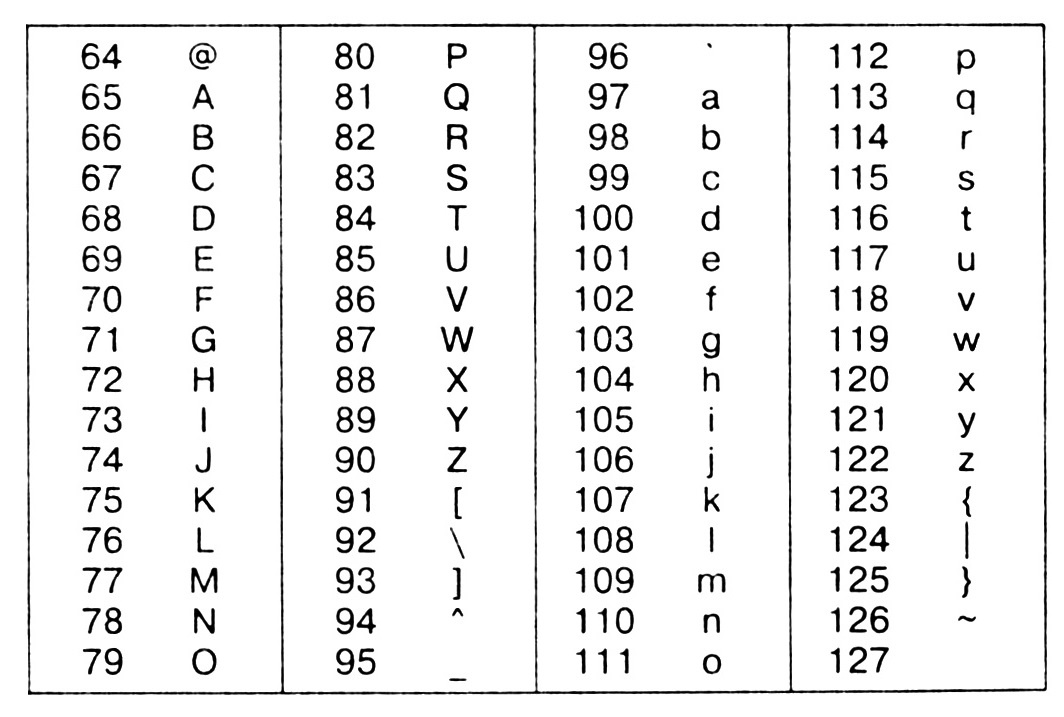
Видим, что прописные буквы имеют коды 90 и менее (начиная от Z и далее к началу алфавита). При этом коды строчных букв отличаются от соответствующих кодов прописных на 32. Вот этим и воспользуемся
if ord(s1[i])<=90 then s2:=s2+chr(ord(s1[i])+32) else s2:=s2+s1[i]
Завершаем цикл, выводим результат и завершаем программу. Условие №1 выполняется автоматически, поскольку, встретив гласную букву, мы ничего не делаем, а просто переходим к следующей букве, т. е. в результирующей строке s2 гласных букв не будет.
end;
writeln(s2)
end.
Проверяем?
Вводим
QWERTYUIOPasdfghjklZXCVBNMrTgHiOmRvWkOUURFGthnmkDSEWmnjbvIOPLDSrdfg
Результат
.q.w.r.t.p.s.d.f.g.h.j.k.l.z.x.c.v.b.n.m.r.t.g.h.m.r.v.w.k.r.f.g.t.h.n.m.k.d.s.w.m.n.j.b.v.p.l.d.s.r.d.f.g
Гласные исключены, точки добавлены, прописные стали строчными - что и требовалось.
Полностью программа без комментариев:
const
glasn: set of char = ['A','a','O','o','U','u','E','e','I','i','Y','y'];
var
s1, s2: string;
i: integer;
begin
readln(s1); s2:='';
for i:=1 to length(s1) do
if not (s1[i] in glasn) then
begin
s2:=s2+'.';
if ord(s1[i])<=90 then s2:=s2+chr(ord(s1[i])+32) else s2:=s2+s1[i]
end;
writeln(s2)
end.