Если тебе понравится - подпишись на мой Telegram-канал, пожалуууйста!
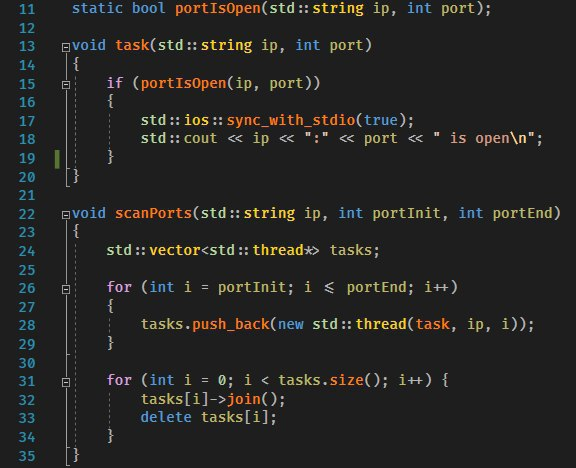
Скоро сессия, а значит пора сдавать задачи, ну в последний момент как всегда. Передо мной стояла задача написать сканер открытых TCP-портов, задача буквально на пару минут, алгоритм такого сканера примитивен: создай TCP-сокет и попробуй установить соединение с хостом по определенному порту, если соединение установлено - порт открыт, а если не установлено - закрыт.
Напоминаю, про свой Telegram-канал - там очень уютно!
Такое решение будет работать, но очень долго, на один порт уходит 1 секунда, а на проверку 60000 портов - 16.5 часов, не хило да? Понятно, что здесь подключается многопоточное программирование, где на плечи потока ложится проверка одного порта.
В общем я завел лист (std::vector<thread*>), в который складывал запущенные потоки (см. на скрине 28 строка). И теперь запустив сканирование с 1 по 10 000 порт, я узнал открытые порты менее чем за пол минуты (10 000 потоков все таки трудились). 10к потоков это уже на самом деле перебор, программа съела около 200МБ памяти и процессор был загружен на ~70%.
Окей, я решил добить систему и хотел посмотреть, как она справится с 60к потоками... Ставим сканер с 1 по 60 000 порт иии.... Получаем просто неизвестную ошибку, программа валится и закрывается на запуске 14 326 потока (всегда кстати именно на этом числе). На этот момент прога съела около 200МБ оперативы и загрузила процессор на 90 процентов. Немного почитав статьи - я понял, что не рекомендуются запускать потоков больше, чем ядер (вот вам пища для размышления, почему?).
Это была проблема моей программы, ведь она не могла сканировать более 14к портов (а в системе их 65536) - решение я нашел быстро, просто стал запускать по 1000 потоков. Тем самым на проверку 60к портов уходит ~3 минуты, что меньше 16.5 часов. Вот так вот многопоточность помогает ускорить некоторые процессы.
Больше экспериментов в Telegram-канале и на YouTube-канале



















