Исследователи из OpenAI показали алгоритм GPT-3, предназначенный для написания текстов на основе всего нескольких примеров. Его архитектура Transformer аналогична GPT-2, но модель обучали на 175 миллиардов параметрах или 570 гигабайтах текста.
Теперь GPT-3 может отвечать на вопросы по прочитанному тексту, а также писать стихи, разгадывать анаграммы и осуществлять перевод. Алгоритму достаточно от 10 до 100 примеров того, как выполнить действие.
Основная задача, которую удалось решить авторам — сделать предобученный NLP-алгоритм универсальным. То есть, GPT-3 для каждой новой задачи требуется минимум обучающих данных. Предшествующий алгоритм GPT-2 обучали на 40 гигабайтах текста.
В новый датасет для обучения GPT-3 вошли данные проекта Common Crawl, а также Википедия, два датасета с книгами и вторая версия датасета WebText, с текстами веб-страниц. Первый WebText использовали для обучения GPT-2.
Всего было обучено восемь разных моделей GPT-3. Все они отличались количеством параметров для обучения. Самую простую модель обучали на 125 миллионах параметров.
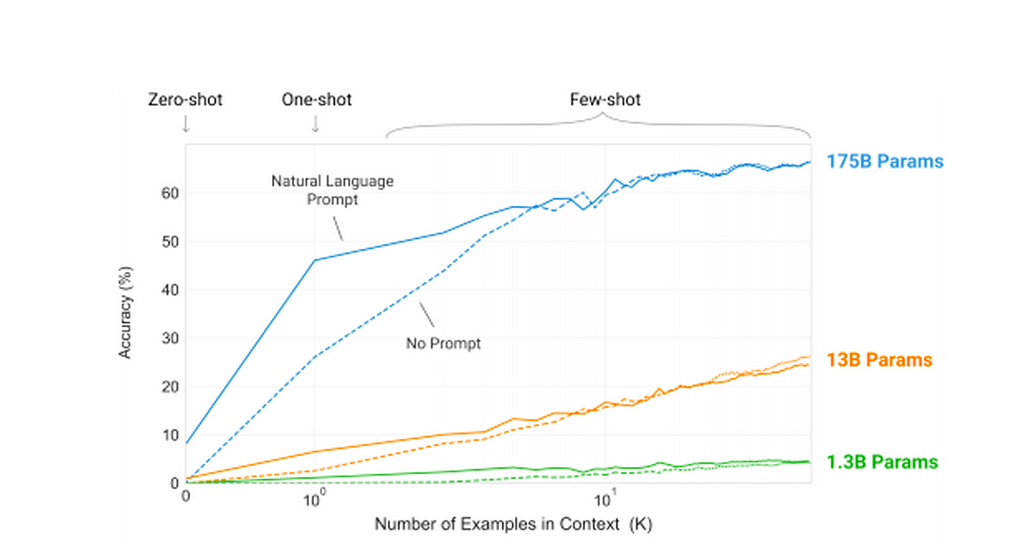
GPT-3 нужно было выполнять 42 разных задания. Это мог быть и простой ответ на вопрос, и написание стихотворения, и разбор анаграммы. Помимо самого задания, алгоритм получал один или несколько примеров его выполнения. В итоге средняя точность самой продвинутой модели, которую обучали на 175 млрд параметров, составила по всем заданиям 60%.
К примеру, при обучении на 64 примерах из датасета TriviaQA (учит понимать текст и отвечать на вопросы по прочитанному), GPT-3 продемонстрировала точность в 71,2% случаев. Этот результат лучше, чем у модели SOTA, которую учили отвечать только на вопросы по TriviaQA.
Поскольку около 7% всего датасета представлено на иностранных языках, GPT-3 может переводить на несколько языков.
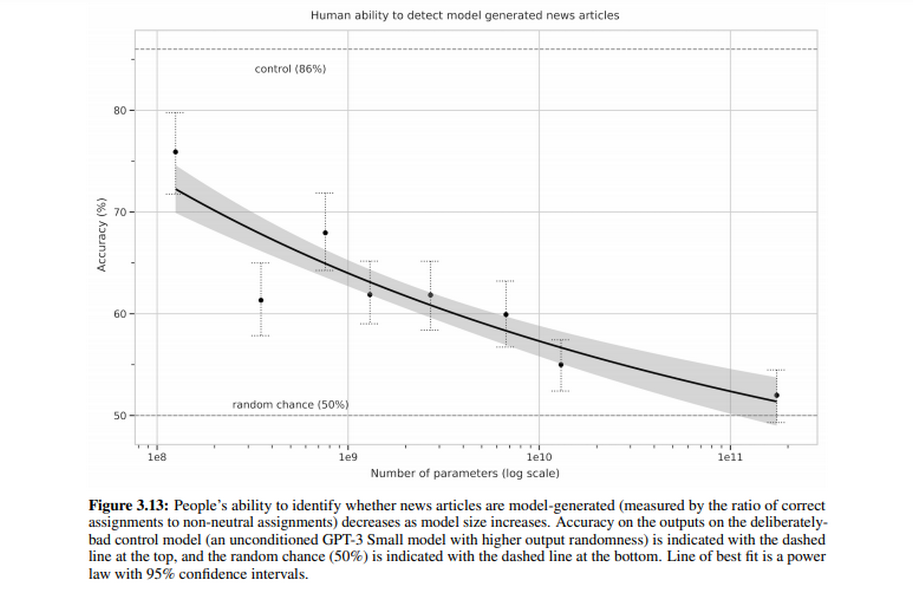
Авторы разработки провели эксперимент с людьми, которым предложили определить, были тексты и заголовки сгенерированы системой или написаны человеком. Выяснилось, что уровень доверия к текстам GPT-3 выше, чем к продукту предыдущих моделей. То есть, пользователям становится все сложнее отличать такие тексты.
Исследователи пока не представили саму модель, так как опасаются, что ее навыки могут быть использованы во вред. На Git Hub есть пока только часть датасета и примеры использованных заданий.
На Reddit подсчитали, что для обучения модели могла потребоваться работа 1536 GPU в течение 60 дней.
В ноябре OpenAI показала GPT-2. Модель выпускали также частями. Самую продвинутую обучали на 1,5 млрд параметров. По результатам опроса сотрудников Корнеллского университета генератору дали «оценку достоверности 6,91 из 10».
В феврале OpenAI объявила, что при реализации будущих проектов перейдет на платформу машинного обучения PyTorch от Facebook и откажется от гугловской TensorFlow. В качестве причины компания сослалась на эффективность, масштабы и адаптивность PyTorch.



















