Видео: YouTube
Продолжаем разговор об основах построения вычислительной техники. На этот раз рассмотрим массивы. Это структура в памяти компьютера в виде элементов, расположенных друг за другом. В классическом понимании эти элементы однотипные. В отдельных технологиях элементы могут быть разных типов, но это уже совсем другая история. Массивы это чрезвычайно часто используемая абстракция. С помощью них организуются вычисления при обработке практически любых данных. Это голос, изображения, видео и разные поля величин в многомерных координатных пространствах.
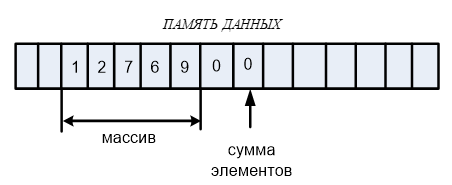
На сегодня у нас задача сложения всех элементов массива. Какие частные вопросы мы рассмотрим:
- технические подробности доступа к элементам массива в памяти компьютера,
- вызов функций.
Процессор с регистровым файлом.
Схема простейшего процессора из прошлых статей слишком примитивна для освещения поставленных вопросов. Немного доработаем ее до представленной схемы.
В основном, нам тут покажется знакомыми многие детали.
Никуда не исчез регистр счетчика инструкций, он же регистр указателя инструкции PC.
Как и раньше он занимается изъятием из памяти очередной инструкции из памяти.
Помогает ему в этом сумматор текущего адреса инструкции с единицей.
Выбранная инструкция поступает в регистр команды на временное хранение.
Как можно заметить, теперь нет отдельной памяти для программ и для данных. Есть одна общая память. Поэтому доступ за инструкцией и за данными осуществляется по очереди. Пока происходит выборка данных инструкция хранится в своем регистре и через дешифратор команд управляет всеми потоками данных в процессоре. Теперь рассмотрим одну важную конструкцию. Это пара регистров R1 и R2. Их выходы подключаются к арифметико-логическому устройству, служащему не просто для арифметических операций, а для вычисления адреса, где хранятся данные.
Рассмотрим расположение массива в памяти. Самый первый элемент массива программисты называют нулевым элементом и на это есть причины технического характера. Для доступа к элементам массива в один из регистров, называемый базой, заносится адрес нулевого элемента. Тогда второй регистр будет хранить индекс элемента и в совокупности это будет весьма удобной схемой. На рисунке регистр R1 указывает на ячейку 2. Регистр R2 хранит число 3, которое является индексом элемента 6. Мы получили к нему доступ, хотя полный адрес числа 6 нам совершенно не интересен. Если в R2 поместить ноль, то получим доступ к нулевому элементу массива. Хоть абстракции и позволяют программистам не заботиться о таких технических вопросах, но по видимому понятие нулевого элемента прижилось надежно.Итак, база и индекс позволяют организовать удобный доступ к элементам массива. В языках Си и С++ синтаксически определено, что имя массива является указателем на нулевой элемент. Также индекс массива, указывающийся в квадратных скобках может быть вычисляемой величиной в процессе работы программы.
Базовый и индексный регистры.
При помощи простого набора элементов возможно выполнить несколько полезных операций. Инструкция с мнемоникой mov заносит в регистр содержимое ячейки памяти, на которую указывает пара регистров база плюс индекс (R1 и R2).
Коды регистров указываются в операндах команды. Инструкция sto сохраняет содержимое регистра в ячейку памяти, на которую указывает пара регистров базы и индекса. Коды регистров задаются в операндах. На этой схеме показана загрузка регистра из памяти.
Тут сохранение регистра в память.
Сохранение регистра в память
Регистровый файл.
Теперь рассмотрим внутреннее устройство регистрового файла.
Это несколько параллельно соединенных регистров с возможностью выбора какие именно регистры подключены на выходы. Этим выбором занимаются мультиплексоры. Также схематически представлен выбор регистра, в который будет произведена запись. При выполнении инструкции сложения содержимого регистров можно выбирать какой из них в данный момент будет аккумулятором. На рисунке это регистр R1. Мнемоника инструкции adc говорит о том, что в сложении еще будет участвовать флаг переноса. Это сильно упростит программу если есть необходимость складывать числа большой разрядности. На схеме операция сложения будет выглядеть следующим образом.
Две шины от двух выбранных регистров проходят к арифметико-логическому устройству и результат операции заносится в выбранный регистр.
Выполнение инструкции непосредственной записи в регистр числа на схеме выглядит так:
Число, а также код регистра содержится в операнде, дешифратор команды отправляет число в нужный регистр.
Стек.
Теперь рассмотрим загадочное устройство, называемое стеком. В некоторых моделях процессоров под временное хранение адреса инструкции выделяется место в сдвиговом регистре.
Почему именно сдвиговый регистр и как он работает сейчас разберемся. Рассмотрим участок памяти, ячейки которой хранят инструкции. Представим, что красным цветом выделяется некоторый участок, который программист выделил как подпрограмму, она вызывается неоднократно. Начало подпрограммы расположено в ячейке 20. После окончания работы процессор должен продолжить работу с того места, откуда была вызвана подпрограмма. Одна тонкость. Подпрограмма вызывается несколько раз. Вызовы происходят из зеленой области и обозначены красными ячейками. После каждого вызова и выполнения подпрограммы управление должно быть передано в разные места. Вот тут в работу и вступает стек.
При вызове подпрограммы в него сохраняется адрес инструкции на которую нужно вернуться. Рассмотрим по шагам всю эту работу. Подпрограмму еще называют функцией. Произошел ее первый вызов, адрес возврата 3 помещен в стек. В PC адрес 20. После выполнения функции происходит возврат на следующую инструкцию после вызова.
Адрес 3 восстановился из стека в регистр PC. Зеленая область инструкций продолжает выполняться пока не встречается еще один вызов функции.
На этот раз после выполнения функции вернуться нужно будет в другое место, адрес возврата заносится в стек. После отработки красной функции происходит возврат на адрес после второго вызова функции. Это адрес 7.
Пример немного посложнее. теперь у нас две функции, красная это функция один и зеленая внизу это функция два.
Из верхнего зеленого участка вызывается function1() , из нее уже вызывается function2() .
После отработки второй функции возврат должен быть в первую, а после отработки первой возврат должен быть в зеленую верхнюю область сразу за первым вызовом. Как это происходит? Да все просто. В стек помещается адрес возврата 3, происходит переход на функцию один. Перед вызовом функции два, сохраняется другой адрес возврата 16, который проталкивает в стеке первый адрес возврата.
Переход на function2(). После отработки функции два сначала происходит возврат на адрес 16.
А после отработки функции один восстановится адрес возврата 3.
На схеме показаны потоки данных при выполнении команды сохранения адреса возврата. Плюс два к текущей инструкции потому что, следующей командой должен быть переход на новую инструкцию.
Вызов функции осуществляется путем загрузки нового адреса в PC.
В конце каждой функции должна быть команда восстановления адреса возврата в регистре PC.
Отладка программы.
Теперь займемся отладкой программы, написанной на языке Cи. Точкой входа в программу называется первая инструкция функции main().
В этой точке глобальной переменной result для хранения результата устанавливается нулевое значение. Это делается потому, что ячейка будет использована как аккумулятор, с ней будут складываться все элементы массива. На модели памяти внизу под результат выделена красная ячейка 9. Элементы размещены один за одним с ячейки 3 по 7 и они выделены зеленым цветом. Под переменную индекса элементов массива выделена желтая ячейка. Следующим шагом происходит вызов функции, при этом адрес возврата, как мы знаем, сохранится в стеке. На него будет произведен выход из функции.
Итак, мы в функции sum() . Циклическая конструкция for объясняет компилятору, что содержимое фигурных скобок выполнится столько раз, сколько шагов уйдет на изменение переменной цикла index с начального значения 0 до ситуации, когда логическое выражение index < 5 станет ложным. Каждый шаг значение переменной index увеличивается на единицу. Это задается выражением index++ . Иначе это называется инкрементом индекса после выполнения тела цикла. Он же постинкремент. Цикл выполнится ровно 5 раз, при этом содержимое переменной индекс будет равно 0, 1, 2, 3, 4. На значении 5 логическое выражение в описании цикла станет ложным и произойдет выход из него. В ячейку результата добавлен первый элемент, к индексу добавлена единица.
Где то там в процессоре к содержимому индексного регистра добавилась единица. Проверка на истину логического выражения index < 5 сработала, а значит еще выполняется тело цикла. К содержимому результата добавился следующий элемент. Так происходит пока index < 5.
Наконец, работа цикла окончена и вместе с нем окончена работа функции sum() .
Где-то там в процессоре сработала инструкция восстановления адреса возврата из стека ret и управление перешло к инструкциям сразу за вызовом функции.
Там в нашем случае выход из программы. В будущем мы рассмотрим как написать этот код более правильно и почему нежелательно использовать глобальные переменные, видные для всех функций. Они описаны в самом верху исходного кода. Это переменная index и сам результат result.