Иногда в своей работе я осуществляю веб-скрейпинг с помощью selenium, но этот инструмент работает слишком медленно.
Решение, казалось бы, лежит на поверхности, но в течение последних двух лет я не видел что его кто то использует.
Как вы, возможно, знаете, основная причина, по которой selenium работает медленно, – это парсер. Поэтому первое, что приходит на ум – это изменить парсер в selenium.
Чтобы показать вам, как это работает, я буду использовать selenium с chromedriver, beautifulsoup4 и эту страницу в Википедии, которая содержит таблицу с некоторой информацией о штатах США.
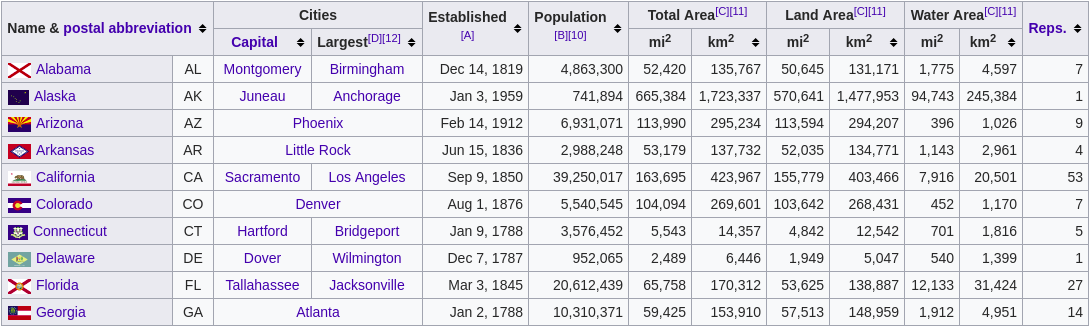
Итак, для начала я сделал Python скрипт, который использует только selenium для извлечения данных из таблицы:
from datetime import datetime
from selenium import webdriver
def get_states():
url = 'https://en.wikipedia.org/wiki/List_of_states_and_territories_of_the_United_States'
driver = webdriver.Chrome()
driver.get(url)
rows = driver.find_element_by_xpath('//*[@id="mw-content-text"]/div/table[1]/tbody')\
.find_elements_by_tag_name('tr')
states = []
for row in rows:
cells = row.find_elements_by_tag_name('td')
name = row.find_element_by_tag_name('th').text
abbr = cells[0].text
established = cells[-9].text
population = cells[-8].text
total_area_km = cells[-6].text
land_area_km = cells[-4].text
water_area_km = cells[-2].text
states.append([
name, abbr, established, population, total_area_km, land_area_km,
water_area_km
])
driver.quit()
return states
if __name__ == '__main__':
start = datetime.now()
states = get_states()
finish = datetime.now() - start
print(finish)
Если вы запустите этот скрипт, вы увидите, что реализация заняла 27,177188 секунд.
Теперь давайте попробуем изменить стандартный парсер Selenium на BeautifulSoup. Просто получаем исходный код страницы и отправляем его в парсер BeautifulSoup:
bs_obj = BeautifulSoup(driver.page_source, 'html.parser')
В результате код веб-скрейпинга будет выглядеть следующим образом:
from datetime import datetime
from selenium import webdriver
from bs4 import BeautifulSoup as BSoup
def get_states():
url = 'https://en.wikipedia.org/wiki/List_of_states_and_territories_of_the_United_States'
driver = webdriver.Chrome()
driver.get(url)
bs_obj = BSoup(driver.page_source, 'html.parser')
rows = bs_obj.find_all('table')[0].find('tbody').find_all('tr')
states = []
for row in rows:
cells = row.find_all('td')
name = row.find('th').get_text()
abbr = cells[0].get_text()
established = cells[-9].get_text()
population = cells[-8].get_text()
total_area_km = cells[-6].get_text()
land_area_km = cells[-4].get_text()
water_area_km = cells[-2].get_text()
states.append([
name, abbr, established, population, total_area_km, land_area_km,
water_area_km
])
driver.quit()
return states
if __name__ == '__main__':
start = datetime.now()
states = get_states()
finish = datetime.now() - start
print(finish)
И после запуска мы видим… 07.664240 секунд! Результат в 3 раза быстрее!
Таким образом, Selenium является отличным инструментом, если вам нужно имитировать действия пользователя, но если вы работаете с большими или огромными массивами данных с веб-страниц, то лучший способ – делегировать эту задачу более быстрым анализаторам.