В конце этой части, мы загрузим данные о погоде в Канаде за весь 2012 год, и сохраним в CSV файл. Мы сделаем это, загрузив каждый месяц в отдельности, а затем сгруппировав все месяцы вместе.
Здесь температура за каждый час в 2012 году!
In [1]:
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
pd.options.display.max_rows = 7
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (15, 3)
plt.rcParams['font.family'] = 'sans-serif'
In [2]:
weather_2012_final = pd.read_csv('data/weather_2012.csv', index_col='Date/Time')
weather_2012_final['Temp (C)'].plot(figsize=(18, 6))
Out[2]:
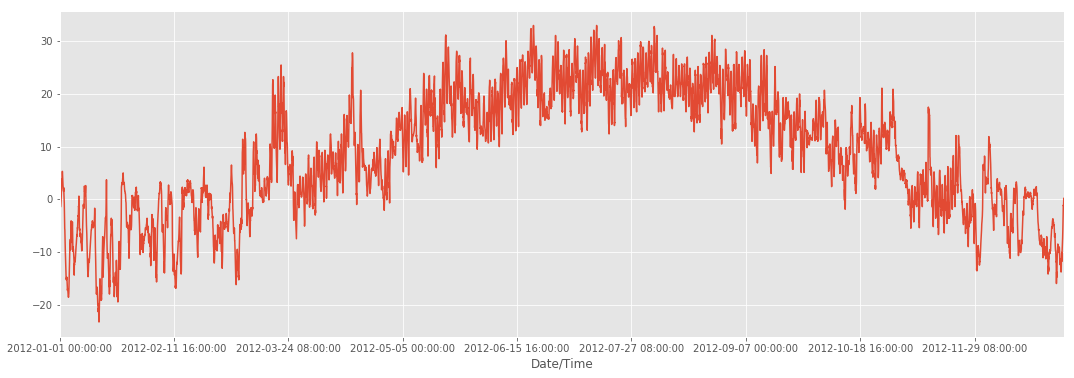
Загрузка данных за 1 месяц
При работе с данными о велосипедистах, мы хотим только данные о температуре и осадках, чтобы понять, много ли людей любит кататься на велосипеде в дождь. Для этого зайдем на сайт исторических данных о погоде в Канаде, и посмотрим, можно ли это сделать автоматически.
Сейчас мы возьмём данные за 2012 год, и уберем их них все ненужное нам.
Это адрес с данными для Монреаля:
In [3]:
url_template = "http://climate.weather.gc.ca/climate_data/bulk_data_e.html?format=csv&stationID=5415&Year={year}&Month={month}&timeframe=1&submit=Download+Data"
Чтобы получить данные за март 2012, мы должны форматировать строку с month=3, year=2012.
In [4]:
url = url_template.format(month=3, year=2012)
weather_mar2012 = pd.read_csv(url, skiprows=15, index_col='Date/Time', parse_dates=True, encoding='latin1')
Это здорово! Мы можем использовать read_csv, как и раньше, и просто использовать URL как имя файла.
В начале файла 16 строк метаданных, но pandas знает, что CSV могут быть странными, поэтому у read_csv есть опция skiprows. Мы снова обрабатываем даты, и устанавливаем 'Date/Time' в качестве индекса. Это получившийся dataframe.
In [5]:
weather_mar2012
Построим график температуры!
In [6]:
weather_mar2012["Temp (°C)"].plot(figsize=(15, 5))
Out[6]:
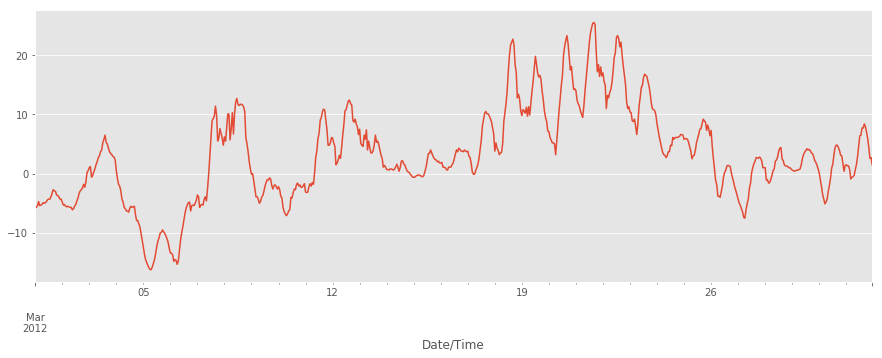
Давайте исправим названия некоторых столбцов (согласитесь, не очень удобен столбец "Temp (°C)").
In [7]:
weather_mar2012.columns = [
u'Year', u'Month', u'Day', u'Time', u'Data Quality', u'Temp (C)',
u'Temp Flag', u'Dew Point Temp (C)', u'Dew Point Temp Flag',
u'Rel Hum (%)', u'Rel Hum Flag', u'Wind Dir (10s deg)', u'Wind Dir Flag',
u'Wind Spd (km/h)', u'Wind Spd Flag', u'Visibility (km)', u'Visibility Flag',
u'Stn Press (kPa)', u'Stn Press Flag', u'Hmdx', u'Hmdx Flag', u'Wind Chill',
u'Wind Chill Flag', u'Weather']
Есть много столбцов, которые почти полностью пусты. Давайте удалим их с помощью функции dropna.
Аргумент axis=1 у dropna означает "удалить столбцы, а не строки", и how='any' означает "удалить столбец, если хотя бы одно значение пусто".
Сейчас гораздо лучше - у нас только столбцы с реальными данными.
In [8]:
weather_mar2012 = weather_mar2012.dropna(axis=1, how='any')
weather_mar2012[:5]
Out[8]:
Столбцы Year/Month/Day/Time лишние, кроме того, столбец "Data Quality" тоже не слишком полезен. Удалим их.
axis=1 означает "удалить столбцы", как и раньше. По умолчанию dropna и drop всегда удаляют строки (axis=0).
In [9]:
weather_mar2012 = weather_mar2012.drop(['Year', 'Month', 'Day', 'Time', 'Data Quality'], axis=1)
weather_mar2012[:5]
Out[9]:
Здорово! Теперь проще работать с этими данными.
Дневной график температуры
Просто так - мы этим уже занимались в предыдущей части. Но давайте сделаем это. Графики красивы.
In [10]:
temperatures = weather_mar2012[[u'Temp (C)']].copy()
temperatures.loc[:,'Hour'] = weather_mar2012.index.hour
temperatures.groupby('Hour').aggregate(np.median).plot()
Out[10]:
Наибольшая температура (по медиане) приходится на 2 часа дня. Неплохо.
Получаем данные за год
Как теперь получить данные за весь год? В идеале, сайт должен предоставлять такую возможность, но на практике такой возможности нет.
Во-первых, у нас есть функция, получающая данные за месяц:
In [11]:
def download_weather_month(year, month):
url = url_template.format(year=year, month=month)
weather_data = pd.read_csv(url, skiprows=15, index_col='Date/Time', parse_dates=True)
weather_data = weather_data.dropna(axis=1)
weather_data.columns = [col.replace('\xb0', '') for col in weather_data.columns]
weather_data = weather_data.drop(['Year', 'Day', 'Month', 'Time', 'Data Quality'], axis=1)
return weather_data
Проверим, что функция работает верно:
In [12]:
download_weather_month(2012, 1)[:5]
Out[12]:
Теперь объединим все месяцы. Получим их:
In [13]:
data_by_month = [download_weather_month(2012, i) for i in range(1, 13)]
Объединим dataframe с помощью pd.concat. Теперь у нас данные за весь год!
In [14]:
weather_2012 = pd.concat(data_by_month)
weather_2012
Out[14]:
Сохранить dataframe в CSV файл
Вы заметили, что функция download_weather_month выполняется медленно? Не стоит каждый раз загружать эти данные, поэтому сохраним результат в CSV файл.
In [15]:
weather_2012.to_csv('data/weather_2012.csv')