Тестируя веб-приложения при помощи метода BlackBox, вы, скорее всего, не сможете посмотреть его исходные коды. Чего не скажешь о веб-страницах. Их-то код мы и будем проверять на предмет информационных утечек.
При разработке приложений программисты-девелоперы комментируют код. Это сильно облегчает работу и экономит время, особенно если над проектом работает большая команда. Да и после разработки комментарии оказываются очень полезными при редактировании приложения.
Но при этом, если в комментариях заключена конфиденциальная информация, они могут пригодиться злоумышленникам.
Начало комментария в HTML-коде обозначается символом <!-- , а конец -- >
Пример:
<!-- текст комментария -- >
В javascript комментарии бывают однострочными и открываются знаком //
Пример:
// текст комментария javascript
Также бывают многострочные комментарии. Они открываются знаком /*, а закрываются */
Пример:
/* текст многострочного
Комментария */
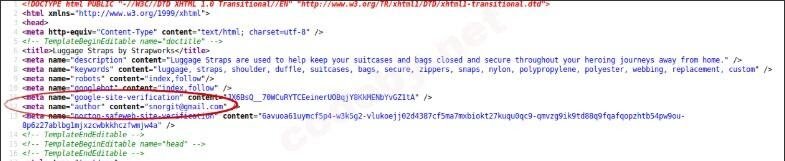
Также для обеспечения безопасности нужно обратить внимание на теги <meta> в коде страницы, скрипты и пути к ресурсам приложения. Разберем каждую ситуацию на примерах:
Теги <meta>, имеющие атрибуты name= "author", содержат имя автора документа и адрес его почты. Используя эту информацию, можно подобрать пароли к административным интерфейсам и настроить направления будущей атаки.

Из-за атрибута http-aquiv тега <meta> изменяются некоторые заголовки в ответах сервера. Значение атрибута обрабатывается браузером как значение, присланное с сервера:
В указанной ситуации заголовки ответа в коде страницы будут следующими:
Refresh. Это время задержки, после которого произойдет автоматическая перезагрузка страницы. Также в теге указывается, какой документ нужно загрузить. На скрине будет загружаться документ / Server Manager без задержки.
Expires. Дата, когда документ устаревает. При этом браузер не загружает его из кэша, а направляет запрос на сервер для получения новой версии. Ноль в данном случае означает «сейчас».
Cash-control. Помогает определить, нужно ли браузеру отправлять страницу в кэш.
В отдельных случаях информация раскрывается в скриптах:
В скрипте на скрине прописан адрес, по которому скорее всего можно найти тестовую версию приложения. Если попытаться открыть ее, система запросит логин и пароль:
По указанному адресу можно определить CMS. Предположительно, это «1С-Битрикс».
А в этой ситуации раскрывается путь до корня сервера и один IP-адрес:
В комментариях к HTML-коду и JS-скриптам могут быть также учетные данные, как на скриншоте ниже:
Сначала остается непонятным, что за кодировка у логина и пароля. Но если обратить внимание на их длину, то оказывается, что это просто admin и pass.
На данном этапе нужно проверить коды всех страниц. Старые исходники нужно обязательно посмотреть в кэше.
Как определить точки входа приложения
При проверке приложения пентестером нужно учитывать каждый HTTP-запрос, обращать внимание, где применяются POST- и GET-запросы, тестировать все поля ввода в формах и параметры в запросах. Перед проверкой очень важно определить точки входа. Ведь это самые уязвимые места. На этой стадии нужно понять, как приложение формирует запросы, а сервер – ответы.
Смотреть параметры отправляемых POST-запросов можно через встроенные функции браузера или перехватывающий прокси-сервер. Подойдут Burp или OWASP ZAP. POST-запросы проверьте на наличие скрытых полей. Там может быть информация, которая по задумке не должна была попасть к вам в руки, или другие секретные данные.
Прежде чем приступить к определению точек входа, составьте таблицу. Будет достаточно двух колонок. В одной можно записывать запросы, во второй – ответы. Это может показаться довольно утомительным. Но при помощи такого подхода можно четко распланировать дальнейший ход тестирования. В таблице нужно указать все нюансы, которые покажутся важными. Например, являются ли запросы POST или GET, применяется ли SSL, аутентифицирован ли доступ, относится ли запрос к многоступенчатому процессу. Также стоит прописать все заголовки запросов и ответов. Не забудьте, что в приложении могут применяться DELETE и PUT, которые могут быть опасными для него.
Чек-лист определения точек входа:
Запросы:
- Выявите параметры, которые используются во всех GET-запросах. Это, помимо прочего, строка запроса (то, что находится в URL после вопросительного знака), host и cookie.
- Определите места применения POST- и GET-запросов. Используются ли другие HTTP-методы? И если да, то где.
- Выявите скрытые характеристики POST-запроса. В браузере они не видны. Но для их выявления подключите перехватывающий прокси и обратите внимание на тело запроса. Скрытые параметры могут влиять на следующую страницу при условии выполнения запроса, на ее данные и уровень доступа.
- Выявите параметры, применяемые во всех POST-запросах.
- Найдите все параметры строки запроса. Обычно они выглядят как параметр=значение. Например, id=012, page=7 и так далее. Параметров может быть множество. Они разделяются специальными символами, в частности &.
Любой из параметров может оказаться слабым звеном. Нужно также проверить нестандартные параметры в скрытых полях POST-запросов. Например, debug=false.
Ответы:
- Выясните, где инсталлируются, добавляются и изменяются куки.
- Не пропускайте заголовки. Например, заголовок Server: BIG-IP свидетельствует о том, что в приложении применяется балансировщик нагрузки.
- Выясните, где ответы сервера ограничиваются кодами состояния (300, 400, 500) при том, что запросы не изменены.
Примеры:
POST-запрос, рассматриваемый через встроенные функции браузера. Видны заголовки запроса и ответа, а также параметры запроса.
Заголовки ответа:
Заголовки запроса:
Параметры запроса:
В запросе есть скрытые параметры (hidden), которые не меняются через обычную форму ввода:
GET-запрос. Здесь есть два параметра: id (значение 69545) и veaction (значение edit).
ЧПУ – человеко-понятный (или семантический) УРЛ.
Это УРЛ, который состоит из слов и отражает тематику страницы. Например аналогом /index.php?cat=10&subcat=2&id=41 будет человеко-понятный /product/phone/Samsung/
Семантические УРЛы становятся все более популярными. Но с ними сложнее определять параметры GET-запросов. Частично эта задача решается здесь.
Бывают примеры, когда параметры строки запроса определить несложно. Ниже человеко-понятный УРЛ:
А здесь этот же запрос уже со значением id=5:
Чтобы лучше понять, как в приложении формируются запросы, можно обратиться в Google и посмотреть УРЛ, прошедший индексацию:
Карта приложения
После определения точек входа приложения нужно составить его карту. Это поможет яснее понять его рабочие процессы и структуру. При дальнейшем тестировании карта пригодится нам еще не раз. Она позволяет быстро определить, где обнаружены ошибки и слабые места, а где еще предстоит провести проверку.
Для разработки карты нужно собрать информацию. Удобнее всего это делать при помощи OWASP ZAP:
Когда программа отсканирует сайт, полученные УРЛы выгружаем в текстовом файле. Точки входа и структура сайта отобразятся в ZAP слева. Выполненные запросы и ответы будут в правой части экрана. Теперь, используя полученные данные, составляем карту. Это удобно делать при помощи Libre Office Draw. В результате у вас должно получиться что-то наподобие:
Чем более подробна карта, тем удобнее вам будет с ней работать. Также для ее составления можно использовать обыкновенный excel-файл, тот самый, в котором вы ранее фиксировали точки входа, запросы и ответы.
В excel-карте можно делать пометки и оперативно вносить в нее изменения. Она выглядит примерно так:
По большому счету, не важно, как выглядит карта. Главное – чтобы она была и вам удобно было с ней работать. Другие вопросы защиты информации подробно рассматриваются в курсах Paranoid и Paranoid II и на форуме codeby.net.



















