Другие статьи по теме:

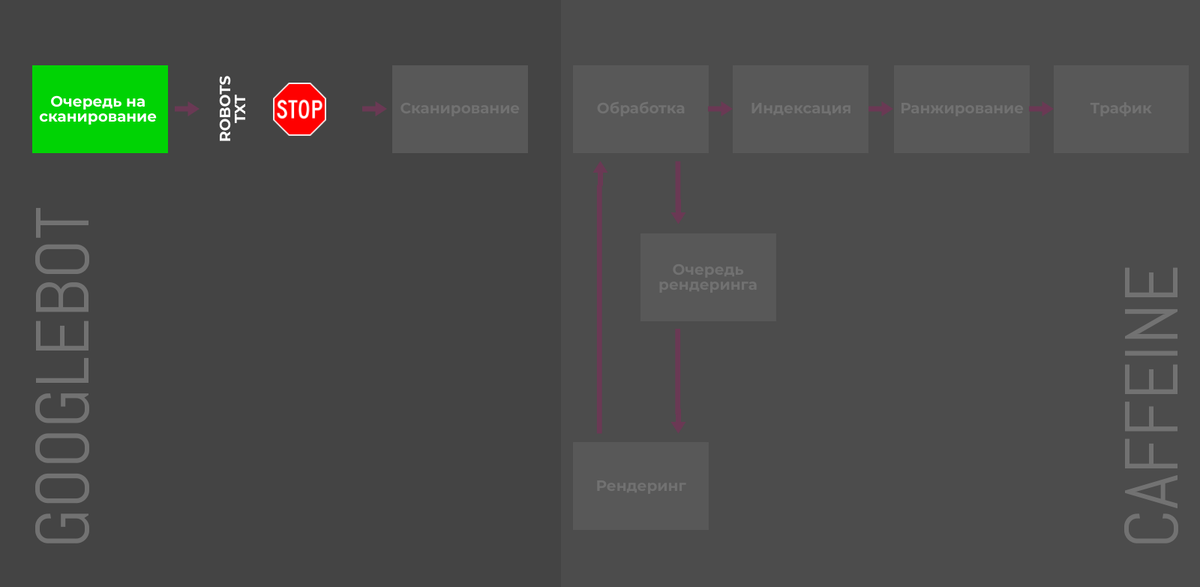
Директива Disallow в файле robots.txt позволяет блокировать отдельные страницы, разделы или полностью весь сайт. Пригодятся для закрытия служебных, временных или динамических страниц.
Тем не менее, директива не управляет индексацией напрямую, и некоторые адреса Google может отправить в индекс, если на них ссылаются сторонние ресурсы. Более того, правило не даёт четких инструкций краулерам, как поступать со страницами, которые уже попали в индексе, что замедляет процесс деиндексации.
Предотвращение «раздувания» индекса: 2/5
Борьба с последствиями «раздувания»: 1/5
Noindex в meta-теге robots
Для полной блокировки индексации отдельных страниц можно использовать мета-тег robots с атрибутом content="noindex" или HTTP-заголовок X-Robots-Tag с директивой noindex. Напомним, что noindex, прописанный в robots.txt, игнорируется поисковыми краулерами.
X-Robots-Tag и мета-тег robots на страницах имеют каскадный эффект и возможны следующие последствия:
- Предотвращают индексацию или исключают страницу из индекса в случае добавления постфактум.
- Сканирование таких URL будет происходить реже.
- Любые факторы ранжирования перестают учитываться для заблокированных страниц.
- Если параметры используются продолжительное время, ссылки на страницах обретают статус «nofollow».
Предотвращение «раздувания» индекса: 4/5
Борьба с последствиями «раздувания»: 4/5
Другие статьи по теме:



















