О новых процессорах VIA долгое время ничего не было слышно; лишь в конце ноября стало известно, что компания разрабатывает новый серверный ЦП с интегрированными средствами ускорения задач ИИ. Сегодня стали доступны интересные подробности об архитектуре грядущих процессоров, которые пока известны под кодовым названием CHA.
Финального имени новые CPU CenTaur пока не имеют, оно будет оглашено в момент официального анонса. Эти чипы нацелены на рынок ЦОД и «пограничных» (edge) серверов. Они действительно имеют 8 ядер с архитектурой x86, их дизайн носит название CNS, но в составе кристалла имеется ещё и 16 ядер NCORE, предназначенных для ускорения задач ИИ и машинного обучения. Каждое такое ядро располагает собственной небольшой памятью объёмом 1 Мбайт, а общий объём составляет 16 Мбайт. Он делится на два блока ‒ D-RAM и W-RAM, каждый объёмом 8 Мбайт.
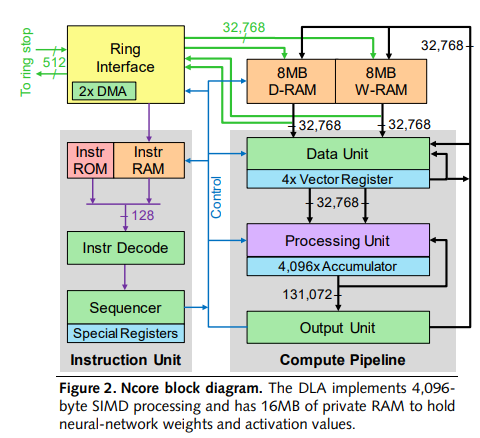
Фактически ИИ-комплекс являет собой отдельный 16-ядерный процессор с архитектурой VLIW и двумя независимыми DMA-каналами доступа к памяти. Он способен выполнять до трёх комплексных операций за такт и поддерживает работу с векторами длиной до 4096 байт. Блок NCORE оптимизирован для работы с данными в формате INT8, но поддерживает и режимы INT16 или bFloat16, пусть и ценой дополнительных тактов.
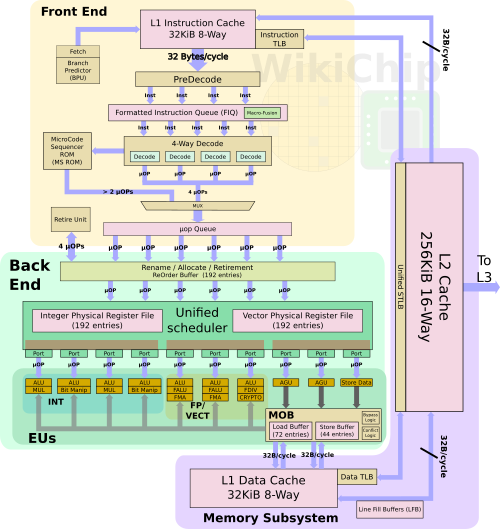
Ядра x86 под кодовым названием CNS были существенно модернизированы в сравнении со старыми дизайнами процессорных ядер VIA/CenTaur. Они получили более эффективный блок предсказания ветвлений и улучшенные блоки предвыборки кода (prefetchers). За такт новое ядро может выбирать из кеша L1 объёмом 32 Кбайт до 32 байт и декодировать до 4 инструкций. Эти показатели сравнимы с аналогичными показателями современных решений Intel и AMD. Объём кеша L2 невелик, всего 256 Кбайт, но поддерживаются кеши и более высоких уровней ‒ прототипы, в частности, располагают 16 Мбайт кеша L3.
Поддерживается слияние макроопераций (MOP Fusion), что в некоторых случаях позволяет увеличивать количество выполняемых за такт операций до пяти. Однако в дизайне CNS не предусмотрено наличие кешей микро- и макроопераций ‒ их планируется ввести лишь в следующем поколении ядер CenTaur. Компания считает, что запланированный уровень производительности будет достигнут и без таких кешей.
Как и все современные процессоры с архитектурой x86, CNS пользуется внеочередным исполнением инструкций. Длина очереди составляет 192 инструкции, то есть столько же, сколько у первого поколения AMD Zen и процессоров Intel Haswell. Техпроцесс, с использованием которого будут производиться новые процессоры, нельзя назвать самым прогрессивным — это 16-нм FinFET TSMC. Но в сравнении с предыдущими решениями, использовавшими 45-нм технологические нормы, это огромный шаг вперёд.
Архитектура планировщика заданий в CNS напоминает подход AMD. Он унифицирован и имеет 10 портов исполнения, разбитых на три группы ‒ для целочисленных операций, для вычислений с плавающей запятой и для операций с памятью. Каждое ядро имеет три порта для FP-вычислений и векторных операций, два из них поддерживают FMA, третий же содержит модули деления и криптографических операций. Все три порта имеют ширину 256 бит, что также напоминает AMD Zen 2.
Разработчики наделили своё детище весьма развитой поддержкой расширений AVX и AVX-512. В последнем случае набор расширений, как минимум, совпадает с возможностями Xeon Scalable первого поколения (Skylake-SP), а также содержит и функции, реализованные лишь в ядре Intel Palm Cove (Cannon Lake).
Пока неясно, будет ли совместимость с Intel на этом уровне стопроцентной. В следующем поколении процессоров VIA/CenTaur планируется дальнейшее расширение поддержки AVX-512. Вероятно, будет добавлена поддержка AVX-512 VNNI, которая на сегодняшний день имеется только у Xeon Scalable второго поколения и десктопных процессоров Intel десятого поколения ‒ Cascade Lake и Ice Lake.
Отметим, что конкурировать в этом плане новому процессору предстоит не только с Intel, но и с разработками Fujitsu, в частности, с ARM-процессорами A64FX. В них реализована поддержка 512-битных векторных инструкций SVE. Кроме того, SVE появится и в CPU Marvell ThuderX3 и X4. Чьё решение окажется наиболее производительным, покажут результаты тестов.
Теоретически, скорость в режиме AVX-512 должна быть боле низкой, чем у Intel — хотя бы за счёт необходимости объединения двух 256-битных операций, однако будущий процессор CenTaur может похвастаться тем, что не будет снижать частоту в этом режиме, тогда как у Xeon Scalable такое снижение порой весьма существенно.
В текущей реализации все ядра CHA, включая и ИИ-сопроцессор, способны поддерживать частоту 2,5 ГГц при различных сценариях нагрузки. Механизмы ограничения теплопакета имеются, но их работа будет зависеть от модели процессора. Старшие версии, возможно, смогут не снижать частоты вовсе.
Подсистема ввода-вывода у процессоров CenTaur CHA ничем особенным не выделяется. Предусмотрено наличие 44 линий PCI Express 3.0. Для сравнения, у Xeon Scalable второго поколения их 48, а у AMD EPYC 7002 ‒ целых 128, причём версии 4.0. На опубликованных слайдах можно видеть наличие четырёхканального контроллера памяти (DDR4-3200), а также некоего интерфейса, используемого в мультипроцессорных системах; его характеристики пока неизвестны.
Возможности контроллера памяти идентичны тем, что реализованы в AMD Zen, но наличие всего четырёх каналов против восьми у AMD и шести у Intel Xeon Scalable гарантирует менее высокую производительность в случаях, когда ПСП является критичным параметром.
В ближайшее время следует ожидать подробностей об архитектуре ИИ-сопроцессоров, входящих в состав CHA. Компания-разработчик уже опубликовала достаточно детальную документацию. Об уровне производительности новых ЦП говорить пока рано. Насколько разработки VIA/CenTaur окажутся успешными, покажет время. Что касается сроков начала массовых поставок, то точных дат пока нет, но ориентироваться стоит на 2 половину 2020 года.