Какая основная сложность при анализе результатов сканирования? Ложные срабатывания! Серьезным недостатком статического анализа кода всегда была необходимость проверки его результатов силами квалифицированных специалистов. Нельзя просто так взять и вывалить результаты сканирования на разработчиков. Это является одной из главных причин неудач при внедрении процесса AppSec. ИБ не может провалидировать все уязвимости, а разработчики не хотят тратить на это много времени. С другой стороны, алгоритмически определить какая из потенциальных уязвимостей является ложной, а какая нет - практически невозможно из за большого числа неизвестных: контекст выполнения приложения, инфраструктура, имеющиеся средства защиты итд...
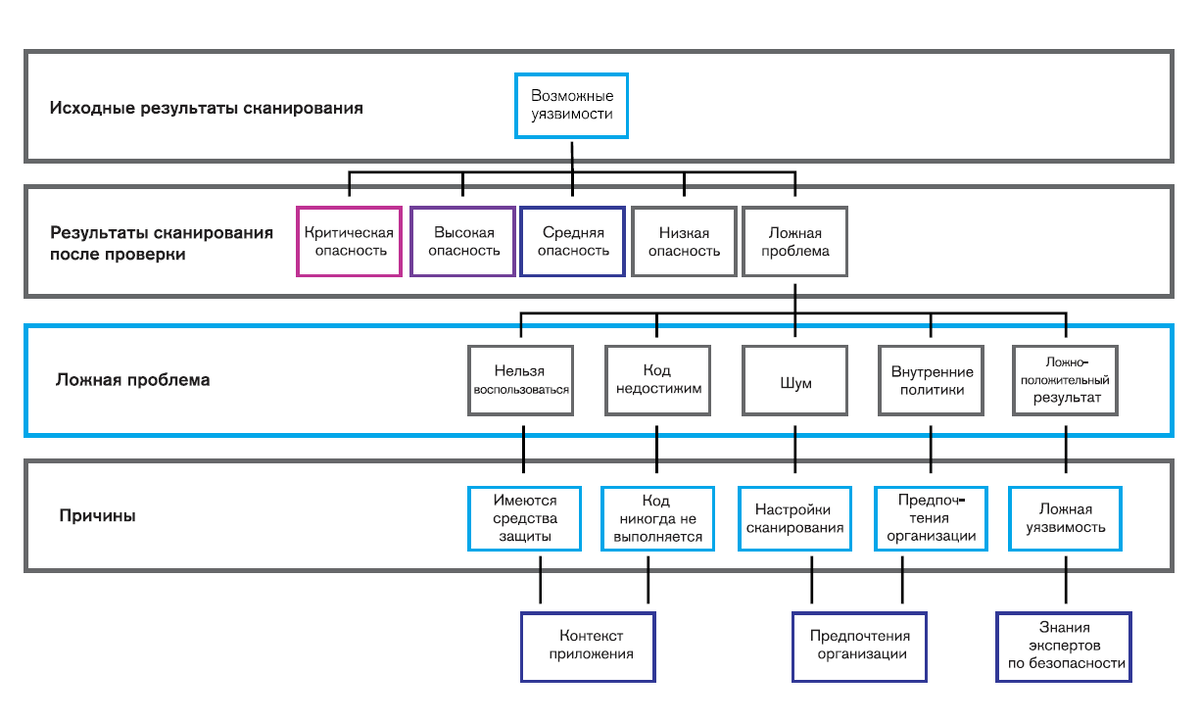
С другой стороны, эта проблема хорошо решается методами машинного обучения, поскольку, наверняка, в массе уже проверенных данных была похожая ситуация, главное найти нужный объем корректно проверенных отчетов. В Micro Focus в рамках сервиса по сканированию исходного кода анализируют проверку результатов, проведенных нашими экспертами и партнерами, если они дают на это разрешение, и на основании этого анализа обучают нейронную сеть, которая доступна пользователям Fortify и в локальной версии в виде инструмента Audit Assistance.
После обработки результатов статического сканирования Audit Assistant дополняет их своим прогнозом и показателем степени уверенности в нем. Основываясь на заранее настроенных порогах толерантности организации к риску, проблема относится к одной из категорий: «вероятно использование», «имеется неопределенность» (если уверенность в прогнозе оказывается ниже заданного порога), «ложная проблема».
Генерируя рекомендации на основе результатов сканирования, выполненного клиентом, Audit Assistant предоставляет возможность использовать знания тысяч специалистов в области безопасности и значительно сокращает время необходимое вам для анализа.
Вот как это работает, смотреть можно минуты с 5ой
Классификаторы Audit Assistant, анализирующие результаты работы Fortify SCA, обнаруживают ложные проблемы с точностью до 98%. Достоверность повышается с помощью учебных данных, которые поступают из перечисленных ниже источников.
■ Fortify Community Intelligence — сообщество экспертов, сотрудничающих с Fortify, которое суммирует знания аудиторов Micro Focus Fortify on Demand, специалистов по исследованиям в области безопасности ПО и клиентов Fortify, сотрудничающих с компанией. В частности, ряд клиентов соглашаются на включение получаемых ими анонимных метрик проблем в набор данных Fortify Community Intelligence, чтобы повысить качество прогнозов для всех клиентов.
■ Собственные данные клиентов. В случае выбора этого варианта классификаторы обучаются только на анонимных метриках проблем, полученных на основе результатов сканирования и их последующей проверки самим клиентом. Сначала выполняется анализ результатов сканирования за предыдущие периоды, затем принятые решения передаются в Audit Assistant для его обучения. и применяются к будущим сканам.