Как использовать мощные механизмы выборки данных средствами SQL, когда информация хранится во внешнем файле? Ответ - загрузить ее в базу данных. В этой статье рассмотрим способы проведения данной операции.

Работать будем с СУБД PostgreSQL. Поискав в интернете, вы найдете такой способ, как использование команды COPY:
COPY [Table Name](Optional Columns)
FROM '[Absolute Path to File]'
DELIMITER '[Delimiter Character]' CSV [HEADER];
Для ее применения следует от имени служебного пользователя postgres (создается во время инсталляции) зайти в командную оболочку psql:
- sudo su postgres;
- psql
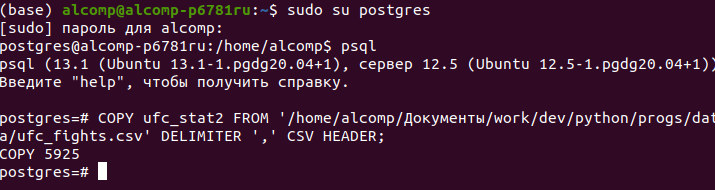
Итак, мы загрузили таблицу поединков с сайта ufcstats.com, которые были скачаны и загружены в файл на локальном диске (подробности об этом читай здесь). Однако для использования данного способа таблица уже должна присутствовать в базе данных, иначе мы получим ошибку:
С учетом этого представленный способ не очень подходит в ситуациях, когда таблица состоит из множества столбцов (в нашем случае как раз количество столбцов - 205) и, соответственно, команда ее создания стала бы достаточно громоздкой.
Поэтому в описанном случае целесообразно воспользоваться скриптом на Python (подробное описание вы найдете здесь). Его первая часть, касающаяся создания таблицы, имеет следующий вид:
а вторая часть направлена на загрузку данных:
Напомню, что практически весь основной функционал скрипта заключается в отображении типов из DataFrame Pandas в SQL, а также перечислении колонок и их значений в соответствии с синтаксисом SQL.
В отличие от предыдущей реализации и в первой, и во второй части скрипта названия колонок взяты в кавычки, так как в исходном файле столбцы содержат символы, вызывающие ошибки при интерпретации механизмом SQL (например, Method:).