Сложность построения модели машинного обучения заключается не столько в выборе алгоритма, сколько в подборе правильных для него параметров. Целью этой статьи является знакомство с основным инструментом такого поиска.
Сеточный поиск
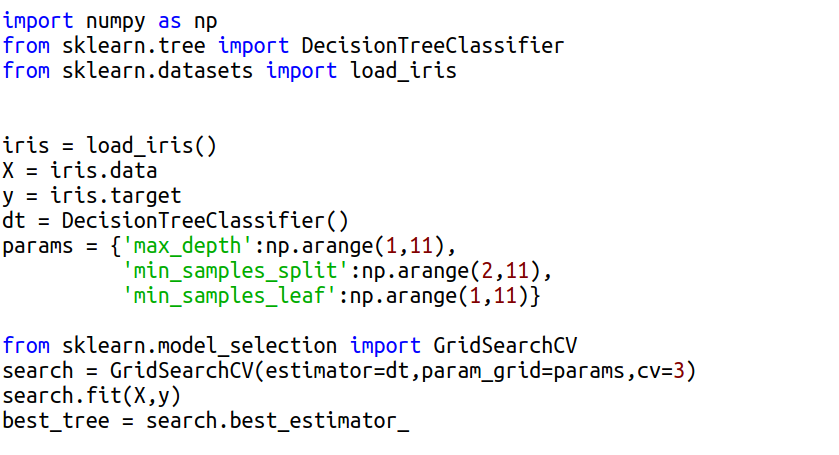
Для этой задачи в библиотеке scikit-learn Python имеется класс GridSearchCV, перебирающий каждое из сочетаний заданных параметров (param_grid), обучающий модель (estimator) и проводящих перекрестную проверку (cv - количество циклов) для выбора лучшей комбинации (подробнее о методах такой проверки писал ранее). После этого в атрибуте .best_estimator_ объекта сохраняется модель с наиболее эффективными настройками. Кроме того, параметр n_jobs GridSearchCV задает количество параллельных процессов, которые могут выполнять поиск, что позволяет оптимизировать распределение процессорных ресурсов.
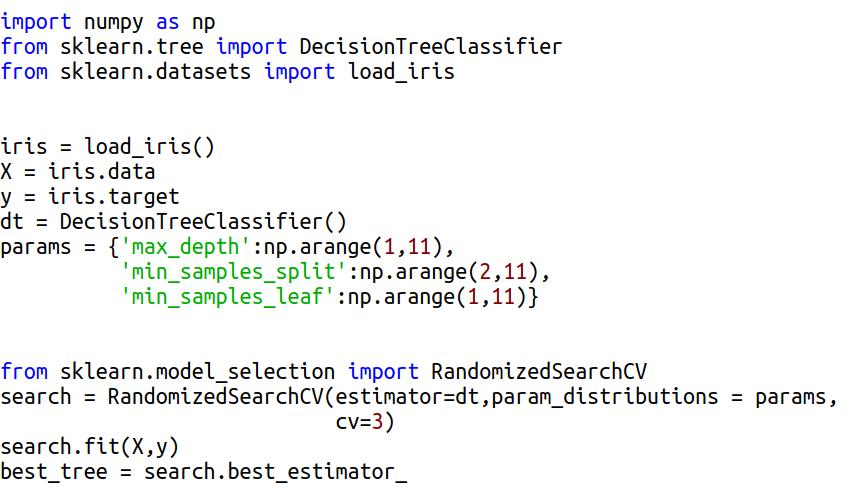
Рассмотрим сценарий выбора параметров дерева решений (подробнее о принципах работы здесь) для классификации цветов ириса по набору их признаков. При этом, такие параметры, как
- минимальное число членов для разделения (min_samples_split)
- максимальная глубина дерева (max_depth)
- минимальное число элементов в листе (min_samples_leaf)
будут подбираться с использованием класса GridSearchCV:
Как можно догадаться такой поиск является делом чрезвычайно затратным. Поэтому и придуман другой инструмент, для реализации схожей задачи.
Случайный сеточный поиск
Он реализован классом RandomizedSearchCV библиотеки scikit-learn. Его отличительной особенностью является перебор не всех комбинаций параметров, а только случайных наборов. Соответственно, и работает RandomizedSearchCV гораздо быстрее, но не исключает потерю оптимальных сочетаний.
Помимо аналогичных GridSearchCV параметров он принимает общее число проверяемых комбинаций (n_iter, по умолчанию - 10).
Для его испытания нужно импортировать класс и включить его при создании экземпляра сеточного поиска: