Многие из вас знают, что такое itertools: библиотека для тех или иных преобразований с итераторами. Лично для меня её роль кажется довольно сакральной: она вся такая подходит для функционального или даже реактивного программирования, супер оптимизированная и вот это всё. А на деле все вышло не совсем так.
Итак, задачей было написать chunker, то есть имея скажем, довольно большой массив элементов (десятки тысяч), отправить его по сети кусками по тысяче элементов. И, конечно, хотелось побравировать перед коллегами своими навыками функционального программирования. Без этого ведь скучно работать, не так ли?
Итак, для начала самое тривиальное решение:
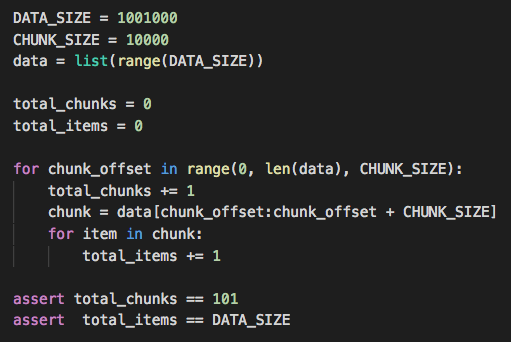
Ах да, и, конечно, мы будем говорить про производительность. То есть про то, о чем вообще лучше не говорить в контексте Python.
Оно работает за 0,89 секунд на моем ноутбуке, и из минусов теоретики программирования отметят создание лишних списков, неэстетичность кода и конечно возможность все сделать неправильно.
Но что же нам делать? Стандартная библиотека предлагает такое решение:
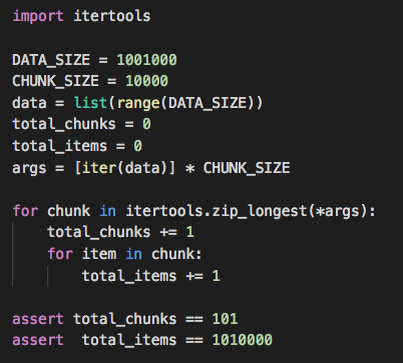
Тут следует отметить два момента: во-первых, для последнего интервала наш chunk будет заполнен до полной длины CHUNK_SIZE элементами None. Во-вторых, такой синтаксис не всем по душе. Скорость? 0,87 секунд. В пределах погрешности от первого топорного решения.
Собственно, дальше я решил бороться с тем, что последний кусочек все равно забит по-полной ненужными None элементами. Пока я рассуждал, как это можно реализовать, я осознал, что нам всегда нужно иметь в запасе одну лишнюю переменную с семантикой "а есть ли у нас во входной последовательности еще одна переменная". Это необходимо для того, чтобы не получилось, что мы "пообещали" пользователю что будет еще один кусочек, а его не оказалось. Поясню: пусть у нас в последовательности 10 элементов и размер кусочка тоже 10. Тогда мы во выполним внешний цикл один раз, передав chunk в тело цикла. В chunk как и обещано, 10 элементов. Затем мы начнем новый chunk, но когда начнем извлекать из него элементы, окажется, что во входящей последовательности элементов нет. Эту задачу я решил следующим образом:
Это код внешнего итератора. По сути, он проверяет, остался ли какой-то остаток во входной последовательности, и если да, то передает этот остаток внутреннему итератору, а затем возвращает внутренний итератор. Вот собственно код внутреннего итератора:
Довольно замысловато, но свое дело делает. За 7 секунд. 7! Писать свои итераторы в Python на уровне Python, а не C, дело неблагородное.
Следующим подходом я сделал вот так:
Выглядит чуть диковато, но смысл такой: генерируем бесконечную последовательность вида True, True, ... True (CHUNK_SIZE раз), затем False, False, False (CHUNK_SIZE раз), и так до бесконечности. groupby возвращает новый итератор для каждого значения ключа, таким образом благодаря groupby у нас получается сначала последовательность из CHUNK_SIZE элементов (потому что у них у всех ключ был True), потом еще одна (потому что ключ сменился на False), потом еще и так далее. Итог: 3,5 секунды.
Все-таки весь этот код оптимизирован чуть сильнее. Но мы пойдем дальше. Есть такая библиотека, more-itertools. Они утверждают, что проблему разбиения последовательности на части они решают. Давайте проверим!
Просто, красиво, приятно, быстро: 0,9 секунды. С одной лишь проблемой: chunk, возвращаемый методом chunked, имеет тип list. Что опять противоречит курсу на красивые узоры итераторных полотен, которые мы так хотели. Но для эстетов библиотека предлагает метод ichunked! Поехали:
23 секунды! Это успех! Зима близко, надо прогревать квартиру, согласен. Особенно хороши для этого быстрые и легкие итераторы.
Вывод: Python как будто бы очень хорошо оптимизирован делать быстро то, что хотят с ним делать простые обычные работящие разработчики. А вот эстетов типа меня он заставляет страдать и греть Вселенную.



















