Оказывается, можно значительно ускорить парсинг дат в Python! Давайте разбираться.
Итак, пусть для начала у нас имеется ~10 Мб файл где записаны даты в формате ГГГГММДД, каждая с новой строки. Нужно считать их все и перевести в тип datetime.datetime.
Давайте начнем с самого простого и изящного способа:
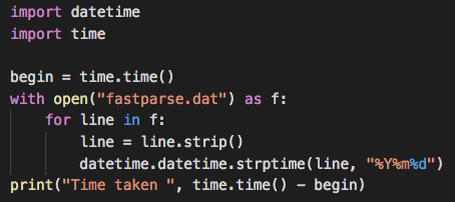
И этот код работает за 22,5 секунды на моей машине.
Его проблема в том, что strptime слишком "умный". Он каждый раз готовиться к тому, что дата будет в новом формате, каждый раз думает как проинтерпретировать цифры. У нас же формат одинаков во всем файле. Попробуем немного иначе:
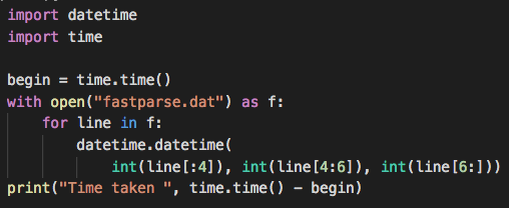
Итог: 2,3 секунды! Почти в 10 раз! Можем ли еще лучше? Да, вполне. В python действует концепция slice by copy, что означает, что при выполнении line[:4] мы создадим новую строку, и скопируем туда символы. Как избавиться от этих копирований? Есть два способа: memoryview либо, в нашем случае, преобразовать строку сразу в число.
Идея такова, что раз данные у нас в формате ГГГГММДД, то их можно положить в целое число, а затем извлечь год, месяц и день не строковыми, а арифметическими операциями. Время: 1,6 секунды!
Кстати, по какой-то причине подход с divmod работает медленнее.
Так же я пробовал проводить оптимизацию извлечения line, но там улучшений не вышло:
Итак, код-победитель: 1,52 секунды!
Так, путем совсем простых преобразований, мы ускорили парсинг почти в 15 раз.