Механизм attention одна из самых мощных идей, продвинувших обработку естественного языка (и не только) в последние годы.
Что же в нем такого увлекательного?
Изначально он был предложен для сетей типа sequence-to-sequence, то есть на входе и на выходе последовательность. В оригинальной статье используется для машинного перевода с английского на французский.
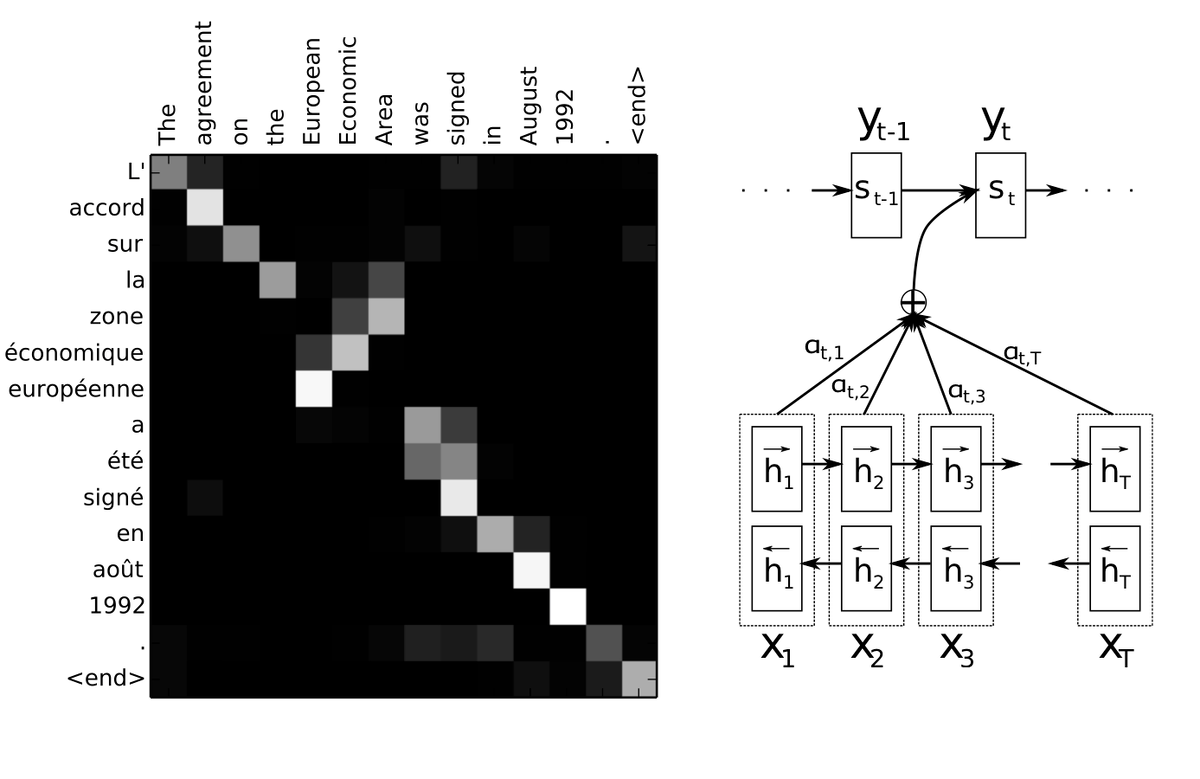
На картинке слева показаны веса α, которые и определяют механизм attention. Они задают то, сколько "внимания" (attention) нужно уделять каждому слову из входного предложения. Например, для перевода слова européenne использовалось только слово European из оригинала. А при переводе артикля la использовалось не только the, но еще и area, что выглядит логичным, ведь не зная рода существительного, определенный артикль на французский не перевести.
На картинке справа изображено, как примерно работают эти веса. Сеть, взятая за основу, состоит из 2х частей: энкодера и декодера. Обе части используют рекуррентные блоки, такие как GRU и LSTM. На картинке самих этих блоков нет, есть только их выходные значения h и s.
Веса α тренируются как часть общей архитектуры и получаются из подсети, на вход которой подается представление очередного входного слова и предыдущее состояние декодера. Авторы называют эту подсеть alignment model. То есть такие веса выполняют задачу выравнивания - сопоставления слова и его перевода.
Таким образом, с плеч реккурентных блоков снимается необходимость запоминать информацию, далекую от текущего входного значения. Эта информация и так будет использована напрямую с помощью attention.
На основе этого механизма и была построена сеть Transformer, которая обеспечила появление BERT и XLNet, о которых был пост раньше.
https://arxiv.org/pdf/1409.0473.pdf
https://t.me/machine_learning_explained