Отметить найденное слово с яркостью по уровню релевантности.
В предыдущей заметке мы рассмотрели, как с помощью Oracle осуществить нечеткий поиск слова в текстах, а с помощью Oracle APEX за 15 минут реализовать готовый для предъявления заказчику образец. Однако, возникла мысль отметить в тексте найденное слово желтым маркером, а яркость маркера сделать в соответствии с оценкой релевантности поиска: 100 %-ное совпадение - ярко, слабое совпадение - тускло. И чтоб пропорционально.
Сказано - сделано:
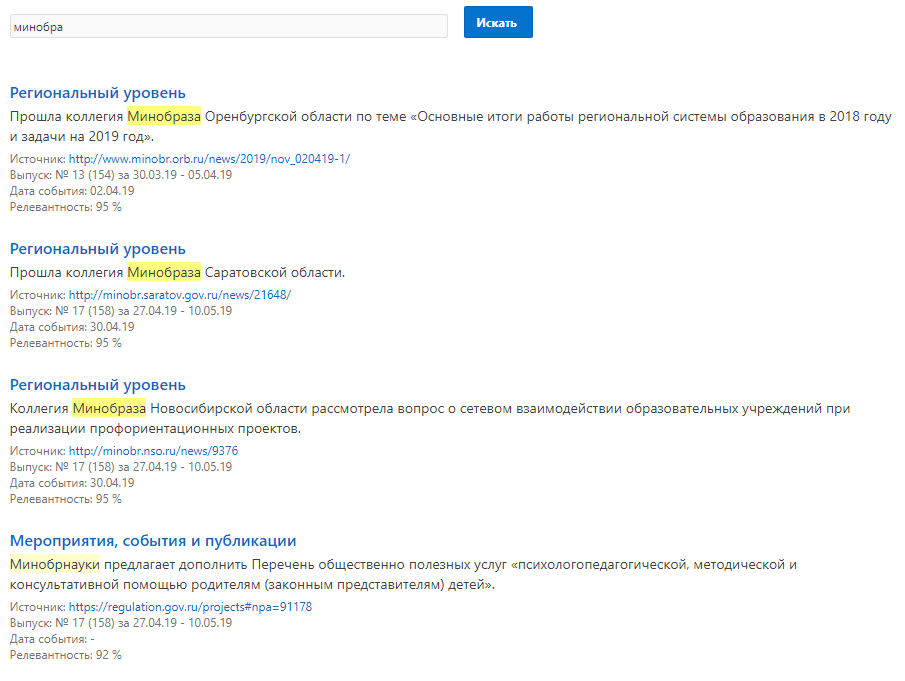
Для этого нам необходимо решить две задачи:
1. Определить (нечетко) найденное слово в списке, и
2. Вычислить значение RGB его окраски в соответствии с его релевантностью относительно ключа поиска.
Решим сначала задачу (2), поскольку ее результат нам будет необходимо непосредственно использовать при практическом решении задачи (1).
Как обсуждалось в предыдущей заметке, меру релевантности оцениваем одним из встроенных в Oracle методов, например, Джаро-Винклера:
select...
utl_match.jaro_winkler_similarity(lower(:P2_KEY), word) as jw_pct
from...
...
;
Определим где-нибудь во вложенном запросе или вообще внешней константой порог релевантности, ниже которого мы в отчет результаты пускать не будем. На практике это примерно 90%:
select...
, 90 as thre
from...
;
Тогда получается следующее. При 100%-ной релевантности нам следует красить слово конкретно-желтым маркером. Желтый - это (RGB 16-ричный) #FFFF00. А минимальный допущенный в отчет - это белый, т.е. #FFFFFF. Это значит, что цвет маркера нам следует конструировать следующим образом: желтый + довесок синего от 00 до FF пропорционально полученной релевантности, нормированной на диапазон [90%; 100%]. И не забыть обратную пропорциональность: релеванотнсть 100% - довесок 00, релеванотность 90% - довесок FF.
Запишем пропорцию:
select
...
255 - round((utl_match.jaro_winkler_similarity(lower(:P2_KEY), word) - thre) * 255 / (100 - thre)) as blue_color_code
...
;
А дальше - небольшая магия от Oracle: преобразование десятичной величины в 16-ричную выполняется преобразованием числа в строку по специальному формату с добавлением при необходимости нуля во второй разряд. Плюс сразу конкатенируем с "желтой" частью FFFF:
...
'#FFFF'||lpad(trim(to_char(s.blue_color_code, 'XX')), 2, '0')
...
Задача (2) решена.
Задачу (1) решим с помощью регулярных выражений, использовав только что полученный результат:
select --text
regexp_replace(text, '('||s.word||')', '<SPAN STYLE="background-color: '||'#FFFF'||lpad(trim(to_char(s.blue_color_code, 'XX')), 2, '0')||';">\1</SPAN>', 1, 0, 'i')
from...
;
Задача (1) решена. А вместе с ней и общая задача. Одним SQL. Минут за двадцать.



















