Одна из самых важных стадий сео аудита, которая поможет не только сделать сайт более привлекательным для поисковых систем, но и даст более четкое видение того, какие подводные камни имеет сайт Вашей фирмы, это поиск дублей.
Скорее всего, Вы уже где-то слышали про дубли, про то, что из-за этих маленьких гадов сайт может терять позиции в поисковиках, Ваша фирма недополучает клиентов, а Вы теряете в зарплате. Сегодня я простым языком расскажу, что такое дубли, из-за чего они берутся, как их найти и как с ними бороться.
Дубли - это страницы с полным или частичным дублированием контента.
То, что дубликаты не приносят Вам ничего хорошего, понятно на интуитивном уровне. Чтобы не уходить далеко в терминологию и теорию, скажу лишь, что каждая страница любого сайта обладает неким весом. Если на том же самом хосте появляется ее дубликат, этот вес размывается. Если поисковая система (особенно Яндекс) не может сразу определить каноническую страницу (то есть ту, которая на самом деле является оригиналом), она может показывать неправильную страницу в поиске или просто пессимизировать (то есть занижать) ее позиции в выдаче из-за наличия неуникального контента. Поэтому нужно как можно раньше разобраться с проблемой наличия дубликатов на Вашем сайте.
Откуда берутся дубли страниц?
Итак, откуда они вообще берутся? В 95% случаяев дубли страниц генерируются CMS, на которой сделан Ваш сайт или вебсервером. Не то чтобы CMS была в этом виновата. Скорее тот, кто ее настраивал. Чем более сырой вариант системы Вы используете, тем, как правило, больше косяков в ней находится.
По факту, неудачно выбранная cms может плодить дубли хоть на пустом месте, и тут надо рассматривать каждый отдельный случай, ставить диагноз и назначать лечение. Ну, хватит воды, давайте поговорим о том, как на практике найти и убрать дубли страниц.
Первая причина дублей - это ненастроенные редиректы. Здесь необходимо проверить 4 вещи:
Редирект на главное зеркало: проверяем главную страницу с www и без. Наличие дублей главной страниц по адресами /index. php и /index. html. Неконечные страницы со слешем и без слеша на конце. Если страница существует в обоих вариантах, необходимо остановиться на одном. Конечные страница с окончанием . php и . html
Далее поговорим о такой распространенной штуке, как рубрикаторы, сложные каталоги, сервисы по подбору товаров, страницы сортировки и тому подобное. Для примера рассмотрим сайт интернет магазина детских товаров.
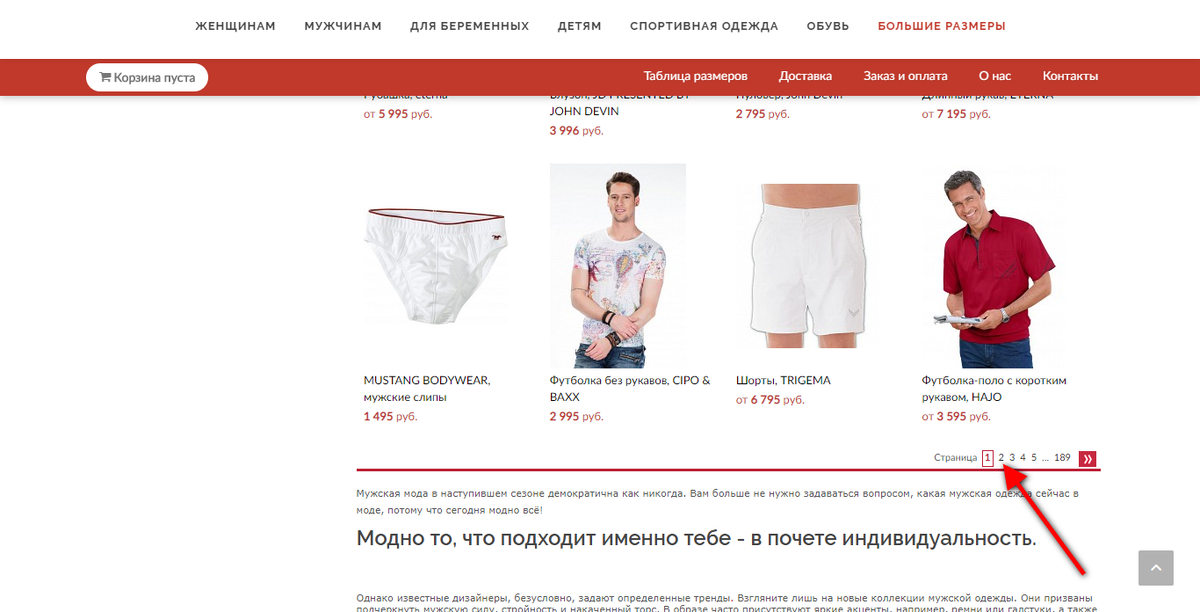
На абсолютном большинстве сайтов есть лазейка на страницах пагинации. Страницы пагинации - это страницы каталога, которые открываются по кнопкам с номерами 1, 2, 3, 4 и так далее. Как правило, если Вы открываете какой-нибудь каталог, например, "Деревянные игрушки", то эта страница является первой. Дальше переходим на следующую, нажав кнопку 2. Смотрим на url. В нем появляются дополнительные параметры. А теперь вернемся на первую страницу, нажав в меню кнопку 1. Сравним адреса. Видите разницу? Это дубли. Итак, фишка в том, что в каталогах с пагинацией главная страница и страница, которая открывается через кнопку, 1 являются дублями.
Как найти дубли страниц?
Сегодня я покажу 2 способа. Первый - трудный и долгий. Второй - быстрый и легкий.
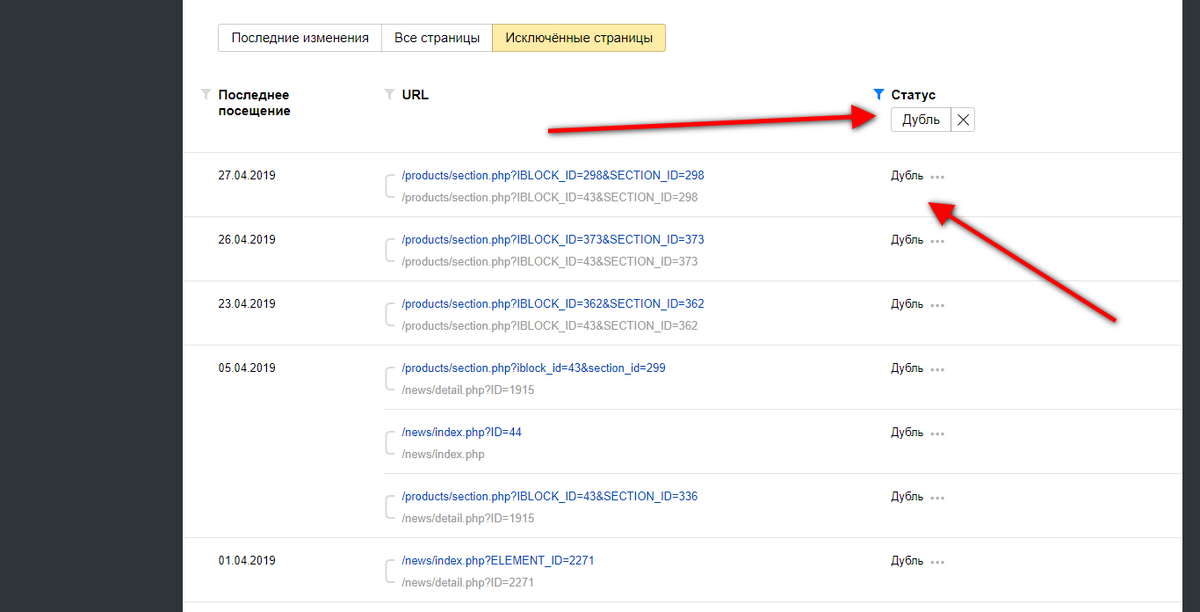
Способ первый - искать подозрительные страницы в выдаче. Открываем Яндекс, вводим туда Site:yoursite.ru , где yoursite.ru - адрес сайта Вашей компании. Не забудьте поставить www. , если оно присутствует в адресе главного зеркала. Что такое главное зеркало, смотрите в отдельном видео. Данный запрос показывается все страницы сайта, которые участвуют в индексе. Бегло просматриваем, ищем подозрительные урлы, подозрительные описания, страницы ошибок и прочее. Это трудоемкий способ, но помимо дублей он поможет выявить различные ошибки, о которых Вы возможно никогда бы и не узнали. Советую хотя бы раз провести подобную проверку.
Второй способ: софт и сервисы для парсинга мета информации. Подумайте сами, у страниц дубликатов не только одинаковое содержание, но и идентичные тэги title и description.
Соответственно, найдя одинаковые тайтлы, мы найдем одинаковые страницы. Сегодня есть довольно много способов это сделать. Самым простым и доступным я считаю google webmaster. Заходим и ищем вкладку "оптимизация html" или "html improvements" в английской версии. Здесь google выдает рекомендации по оптимизации мета информации. Смотрите в каком месте Вашего сайте закрались страницы с одинаковыми мета тегами, проверяйте вручную, действительно ли это дубли и уже тогда устраняйте. Кстати, даже если какие-то страницы не окажутся дублями, одинаковых мета тегов на сайте также быть не должно. Меняйте!
Как убрать дубли страниц
Здесь в общем-то достаточно всего одного способа, о котором я и расскажу. Закрывайте дубли в robots. txt. Этого должно хватить. Внимательно посмотрите видео о составлении robots. txt для того, чтобы закрыть страницы сортировок и группировок.
Для этого необходимо прописать в роботсе параметр, который генерирует страницы. Выглядеть команда будет примерно так:
Disallow: /*&go_search=
Если вам нужна помощь заходите сюда