В конце 2016 года Gartner предсказал, что к 2020 году 30 процентов сеансов просмотра веб-страниц будут проводиться без экрана. Ранее в том же году Comscore предсказал,что половина всех поисковых запросов будет голосовым поиском к 2020 году. Хотя есть недавние свидетельства того, что картина к 2020 году может быть более сложной, чем предполагают эти широкие прогнозы. Мы уже видим влияние, которое голосовой поиск, искусственный интеллект и интеллектуальные программные агенты, такие как Алиса и Google Assistant, оказывают на способ поиска и использования информации в Интернете.
В дополнение к функции индексации, которую выполняют традиционные поисковые системы, интеллектуальные агенты и алгоритмы поиска на основе AI теперь вводят в основной поток два дополнительных режима доступа к информации: агрегирование и вывод. В результате, дизайнерских усилий, направленных на создание визуально эффективных страниц, уже недостаточно для обеспечения целостности или точности контента, публикуемого в Интернете. Скорее, сосредоточившись на предоставлении доступа к информации в структурированном, систематическом виде, понятном как людям, так и машинам, издатели контента могут обеспечить доступность и точность своего контента в этих новых контекстах, независимо от того, создают ли они чат-ботов или используя AI напрямую. В этой статье мы рассмотрим формы и влияние структурированного контента,
Роль структурированного контента
В своей недавней книге « Проектирование подключенного контента» Кэрри Хэйн и Майк Атертон определяют структурированный контент как контент, который «спланирован, разработан и подключен вне интерфейса, так что он готов для любого интерфейса». Подход к структурированному дизайну контента формирует ресурсы контента – например, статьи, рецепты, описания продуктов, инструкции, профили и т. д. – не в виде страниц, которые можно найти и прочитать, а в виде пакетов, состоящих из небольших порций данных контента, которые все значимо связаны друг с другом.
В структурированном процессе разработки контента отношения между фрагментами контента явно определены и описаны. Это делает как куски контента, так и отношения между ними разборчивыми для алгоритмов. Затем алгоритмы могут интерпретировать пакет контента как «страницу», которую я ищу, или ремикшировать и адаптировать тот же контент, чтобы дать мне список инструкций, количество звездочек в обзоре, количество времени, оставшегося до закрытия офиса и любое количество других кратких ответов на конкретные вопросы.
Структурированный контент уже является основой многих видов информации в Интернете. Например, списки рецептов годами основывались на структурированном контенте. Когда я ищу, например, «рецепт плова» в Google, мне предоставляют стандартный список ссылок на рецепты, а также обзор шагов рецепта, изображение и набор тегов, описывающих один пример рецепта:
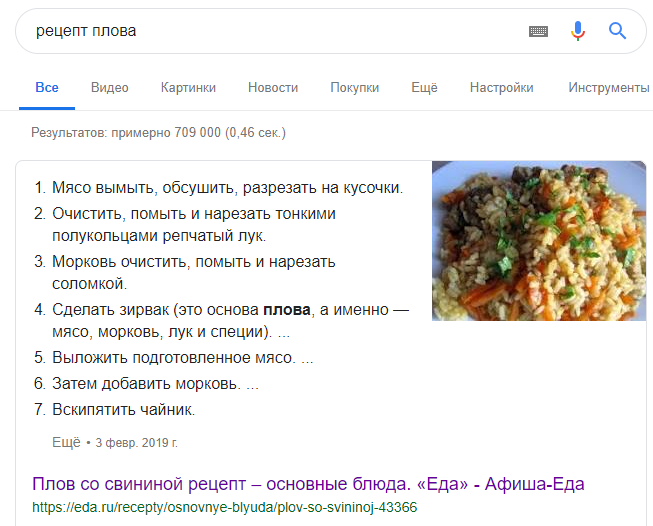
«Избранный фрагмент» рецепта плова на странице результатов Google.
Поиск программного агента и семантического HTML
Семантический HTML – это разметка, которая передает информацию о значимых отношениях между элементами документа, а не просто описывает, как они должны выглядеть на экране. Семантические элементы, такие как теги заголовков и теги списка, например, указывают, что заключаемый ими текст является заголовком ( <h1>) для набора элементов списка ( <li>) в следующем упорядоченном списке ( <ol>).
HTML, структурированный таким образом, является и презентационным, и семантическим, потому что люди знают, как выглядят и что означают заголовки и списки, и алгоритмы могут распознавать их как элементы с определенными, интерпретируемыми отношениями.
Голосовые запросы и вывод контента
Растущая распространенность голоса как способа доступа к информации делает обеспечение структурированного, машинно-понятного контента еще более важным. Голосовые и интеллектуальные программные агенты не просто освобождают пользователей от их клавиатур, они меняют поведение пользователей. Согласно LSA Insider , есть несколько важных различий между голосовыми запросами и типизированными запросами. Голосовые запросы имеют тенденцию быть:
- больше;
- более вероятно спросить, кто, что и где;
- более разговорный;
- и более конкретно.
Чтобы адаптировать результаты к этим более конкретно сформулированным запросам, программные агенты начали выводить намерение и затем использовать связанные данные, имеющиеся в их распоряжении, для составления целенаправленного, краткого ответа. Если я спрашиваю Google Assistant, в какое время, например, “Центр доктора Бубновского” закрывается, он отвечает: “Центр доктора Бубновского” закрыт и откроется в 8 утра. », и отображает этот результат:
Эти результаты не только обобщаются из разрозненных источников, но и интерпретируются и смешиваются, чтобы дать индивидуальный ответ на мой конкретный вопрос.