
Немного истории
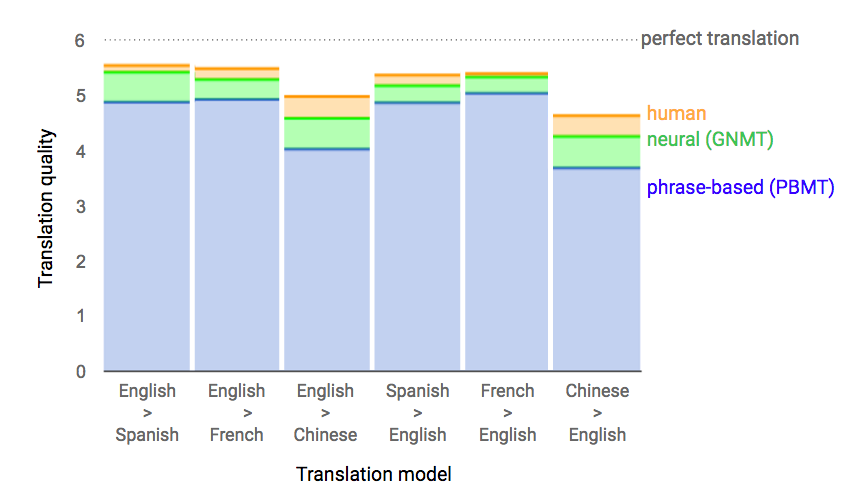
В процессе собственной эволюции системы автоматического машинного перевода прошли несколько этапов. Первые полноценные системы, способные осуществлять перевод, работали на основе морфологии и синтаксиса (а также некоторой семантики) естественных языков. Подобны системы осуществляли полный разбор предложения на исходном языке, а затем из полученной информации выстраивали предложение на результирующем языке в соответствии с его морфологией и синтаксисом. Ресурсозатратность подобных систем затрудняло их массовое использование. Точность перевода также была не высока. Обучение системы каждому новому языку могло занимать годы и не давать результата. С развитием вычислительной техники и последующим появлением огромных объемов текстовых данных в электронном виде стало возможным создавать системы автоматического машинного перевода, работающие на языковых парах слов и словосочетаний. Пример англо-русской пары: <”on the floor” - “на полу”>. Такой подход позволял ставить в соответствие каждому слову или словосочетанию на исходном языке слово или словосочетание на результирующем языке, а затем из полученных элементов «склеивать» предложение. Сегодня такие системы известны под общим названием Phrase-Based Machine Translation (PBMT). Подобный подход преобладал в мире до тех пор, пока в компании Google не решили попробовать использовать нейросеть типа Seq2Seq для улучшения качества перевода. Так началась эпоха (с 2016-го г.) систем с общим наименованием Neural Machine Translation (NMT), о которых и пойдет речь.
Одним из наиболее существенных результатов технологий искусственного интеллекта являются системы автоматического перевода. Современные технологии машинного перевода функционируют на базе нейронных сетей типа Seq2Seq (от англ. Sequence-to-Sequence), обучаясь на огромных массивах данных с использованием мощных графических вычислителях.
Как выглядят обучающие данные
Как же выглядят данные для обучения нейросети? В качестве источника данных для обучения нейронных сетей типа Seq2Seq для машинного перевода используются двуязычные параллельные корпуса текстов. Данные корпуса представляют собой огромные массивы пар предложений, по одному на каждый язык. Примером является пара: ”Меня зовут Алекс” - ”My name is Alex”.
Откуда берутся данные
Двуязычные параллельные корпуса текстов должны содержать миллионы таких пар. Откуда же берутся данные? Обычно параллельные корпуса текстов формируются вручную или автоматически благодаря статьям, книгам и их переводам. Однако, существует достаточно большое количество готовых параллельных корпусов текстов, в том числе и англо-русских.
В каком виде подаются данные на вход
Как же подать слово на вход нейронной сети? Отличительной особенностью современных технологий ИИ в задачах обработки текста является представление слова не в качестве набора знаков, а в виде векторного представления (от англ. Word Embedding). Обычно векторное представление слова является моделью его дистрибутивной семантики, формируемой на основе Skip-gram или CBOW нейросетей.
Архитектура нейросети Seq2Seq
Что собой представляет Seq2Seq нейросеть? Допустим, мы хотим научить нашу сеть переводить предложения с английского на русский язык. Тогда на вход нейронной сети поступают предложения на английском языке, а на выход — на русском. Поскольку каждое из предложений представляет собой последовательность (в нашем случае, последовательность слов), нейросеть Seq2Seq и получила свое название (дословно, «Последовательность в последовательность»). При обучении весовые коэффициенты связей сети корректируются таким образом, чтобы входная последовательность соответствовала выходной.
Поскольку количество слов в каждом предложении различно, нейросеть Seq2Seq относится к классу рекуррентных сетей. Рекуррентными называют нейросети, данные на вход которой подаются последовательно, а выход предыдущей итерации используется при вычислении текущего выхода. Рекуррентные сети бывают статические и динамические. В статических максимальная размерность входной последовательности фиксирована и определяется наперед. В динамических она произвольна. Поскольку длина предложения может составлять от одного до нескольких десятков слов, удобно использовать динамические рекуррентные сети.
Рекуррентные нейросети позволяют отображать зависимость текущего элемента последовательности от предыдущих, однако, в большинстве естественных языков, текущий элемент зависит также и от последующих элементов. Разрешить данную проблему позволяют двунаправленные рекуррентные нейросети. Двунаправленная сеть представляет собой две рекуррентных подсети, первая из которых проходит входную последовательность слева-направо, а вторая — справа-налево. Выходные значения подсетей объединяются.
Перспективные технологии
Несмотря на значительные успехи, задача автоматического машинного перевода не считается полностью решенной, ведь точность перевода лучших систем существенно уступает качеству перевода человеком, особенно для языковых пар типа «английский-китайский», не говоря о языковых парах, для которых нет достаточного объема обучающих данных. Перспективы видятся в моделировании антропоморфных процессов осуществления переводов, иными словами, как перевод осуществляет сам человек, ведь он не обучается переводу на миллионах языковых пар. Таким образом, проблема автоматического машинного перевода с любого языка на любой кроется в проблема создание систем общего искусственного интеллекта, способной, в отличии от Seq2Seq, оперировать знаниями о реальном мире.



















