Janine Bariuan, Kevin Chen, Bibartan Jha, Sudeep Narala, Rooshi Patidar и Diana Shao
Введение
Для этого проекта наша команда решила попробовать создать систему рекомендаций фильмов, которая использует несколько наборов данных для вывода списка фильмов, рекомендованных пользователю. Мы нашли несколько наборов данных в Интернете, включая набор данных MovieLens 100K и набор данных Movie Poster, которые мы в конечном итоге использовали для нашей окончательной модели. Используя эти наборы данных в сочетании с извлеченными данными и реализовав две разные модели, мы смогли создать полную систему рекомендаций фильмов. Следите за нашим репозиторием на Github .
Наборы данных
Мы использовали два существующих набора данных: набор данных MovieLens 100K и набор данных афиши фильма.
MovieLens 100K набор данных
Набор данных Movielens 100K включает 100 000 оценок для более 1600 фильмов, созданных более чем 900 пользователями. Официальный сайт можно найти здесь. Мы использовали элементы (фильмы), рейтинги и наборы данных пользователей.
Набор данных постеров фильма
Этот набор данных берет все фильмы из набора данных MovieLens 100K и предоставляет URL-адрес изображения плаката для этого фильма. Ссылку на официальный набор данных можно найти здесь. Мы использовали файл movie_poster.csv.
Предварительная обработка
MovieLens 100K набор данных
Поскольку набор данных MovieLens состоит из тысяч оценок и фильмов, мы хотели найти любые тенденции, которые произошли в данных. Следовательно, мы могли затем преобразовать набор данных в соответствии с этой информацией.
Первое, что мы хотели увидеть, - это частота рейтингов фильмов.
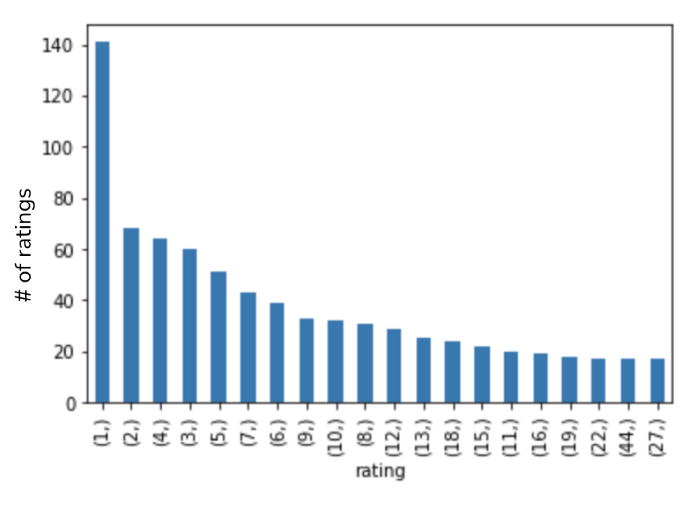
Мы обнаружили, что было много фильмов, которым была присвоена только одна оценка, что можно было рассматривать только как шум при попытке создать прогнозные рейтинги. Чтобы исправить это, мы удалили из данных рейтингов все фильмы, у которых было менее 15 общих оценок от пользователей.
Мы также предприняли следующие шаги:
- Удаление временной метки unix из фреймов данных, поскольку это не было фактором при составлении рекомендаций
- 0-индексация данных для большей согласованности
- И изменение столбцов user_id и movie_id на целочисленные типы, чтобы упростить работу с данными.
Набор данных постеров фильма
С помощью этого набора данных мы предварительно обработали обучающий набор X_train, кодируя изображения плакатов, полученные из набора данных плакатов фильмов. Для этой цели мы использовали функцию предварительной обработки в библиотеке Keras под названием «applications.vgg19.preprocess_input ()». Поскольку модель CNN VGG19 использует набор данных ImageNet в качестве весов, эта функция предварительной обработки выравнивает изображения, закодированные в X_train, для лучшего соответствия ImageNet путем преобразования изображений из RGB в BGR и центрирования по нулю цветовых каналов по отношению к ImageNet.
Этот метод предварительной обработки позволил нам лучше оптимизировать наши модели CNN и KNN. Основной оценочный показатель, который мы использовали для проверки точности наших моделей, - это среднее расстояние от всех соседей для каждого запроса. Чем меньше среднее расстояние, тем выше точность моделей.
Метрика оценки для моделей будет более подробно рассмотрена в разделе «Модель постеров с фильмами» ниже.
На двух графиках ниже показаны результаты «среднего расстояния от соседей» для первых 100 изображений. Эти результаты получены из той же модели VGG19 (с использованием тех же параметров). Верхний график получен из модели до применения предварительной обработки к данным X_train, а нижний график - после применения предварительной обработки.
Как видно из приведенных выше графиков, среднее расстояние от соседей для первых 100 плакатов до предварительной обработки намного выше, чем после предварительной обработки. Это подтверждает, что функция предварительной обработки оптимизировала модели CNN и KNN.
Соскабливание
Мы решили увеличить объем и объем наших данных, вычистив некоторые общие рейтинги фильмов на IMDB и Rotten Tomatoes и включив их в нашу модель. Мы удалили все доступные оценки для фильмов, перечисленных в наборе данных MovieLens 100K.
IMDB
Для парсинга IMDB мы использовали библиотеку запросов (простую библиотеку HTTP для Python) для доступа к странице поиска IMDB и запроса по названию фильма. Мы обнаружили, что формат заголовков в наборе данных MovieLens не подходит для поиска, поэтому мы убрали год в скобках, чтобы получить лучшие результаты.
Затем, когда у нас была страница ответа в формате HTML, мы использовали библиотеку BeautifulSoup, чтобы легко проанализировать страницу и найти результаты поиска. Затем мы перебирали результаты до тех пор, пока год результата не совпадал с годом запроса, и открыли соответствующий URL-адрес, используя метод urlopen из библиотеки urllib.
Наконец, нужно было снова использовать BeautifulSoup, чтобы найти конкретные рейтинги на странице фильмов IMDB. Поскольку IMDB имеет два типа оценок: рейтинг пользователей и мета-рейтинг (рейтинг критиков), мы попытались очистить оба типа, если они доступны. Некоторые фильмы не были достаточно популярными, чтобы получить мета-баллы, поэтому они были просто представлены как NaN. Кроме того, некоторые фильмы вообще невозможно было найти, что, как выяснилось, в основном связано с несовпадающими годами или фильмами с другими названиями. Они были добавлены в набор данных вручную путем поиска в IMDB или Google и ввода их вручную в файл .csv.
Вот визуальное изображение результирующих столбцов, созданных в результате очистки IMDB:
Rotten Tomatoes
Для очистки Rotten Tomatoes мы использовали тот же процесс, что и в случае с IMDB. Мы использовали библиотеку запросов и общедоступную конечную точку API Rotten Tomatoes, чтобы запросить результаты поиска в их базе данных и найти название фильма в конкретный год. Мы столкнулись с аналогичными проблемами с форматом MovieLens, но мы также удалили специальные символы и посторонние элементы из названий фильмов, как это было при работе с IMDB.
API Rotten Tomatoes позволил нам работать с форматом JSON результатов фильма, поэтому найти URL-адрес для конкретного фильма было так же просто, как перемещаться по JSON. Затем мы смогли использовать BeautifulSoup для этого URL-адреса, чтобы легко проанализировать критику Rotten Tomatoes и оценки аудитории.
Однако мы столкнулись с проблемой отправки слишком большого количества запросов к Rotten Tomatoes API, в результате чего некоторые из наших IP-адресов были занесены в черный список с их сервера, из-за чего мы не могли даже регулярно посещать их веб-страницу.
В итоге мы решили, что наличие еще двух оценок в дополнение к уже имеющимся у нас оценкам IMDB, и пользователи не дадут слишком большой разницы, которая заслуживает использования VPN для получения доступа и продолжения очистки. Вместо этого мы решили больше сосредоточиться на других частях нашей системы.
Системный Обзор
Выше представлен общий обзор нашей системы рекомендаций. Он начинается с ввода запроса, сделанного пользователем, который хочет получить рекомендации. Эти входные данные используются в нашей первой модели, которая делает прогнозируемые рейтинги и рекомендации, основанные на информации о плакатах фильмов. Эти выходные данные первой модели затем были отформатированы в новый фрейм данных, содержащий рекомендованные фильмы и их прогнозируемые рейтинги для этого нового пользователя. Эти данные, в дополнение к исходному вводу пользователя, используются в модели матричной факторизации для встраивания пользователей и фильмов. На основе этой модели сделан окончательный вывод из 5 лучших рекомендуемых фильмов. Каждая модель и входной запрос более подробно описаны в следующих разделах.
Входной запрос
Наша система рекомендаций работает для одного пользователя на основе оценок предыдущих фильмов, которые они смотрели. Этот ввод был получен с помощью этой формы Google, в которой перечислены 15 фильмов и пользователю предлагается оценить каждый из них от 1 до 5, 1 за ненависть к фильму и 5 за любовь к нему.
Фильмы, перечисленные в форме Google, были выбраны из 15 фильмов с наибольшим рейтингом в найденном нами наборе данных. Мы выбрали это так, чтобы было более точное предсказание, поскольку эти фильмы будут чаще появляться в пространстве встраивания (пользователь, фильм).
Это также позволило бы составить согласованный список, который будут оценивать пользователи, и не добавило бы шума, который мы удалили, если бы пользователь ввел свои собственные любимые фильмы, которые имеют небольшое количество оценок в существующем наборе данных.
Затем мы преобразовали входной запрос в словарь идентификаторов фильмов для этих 15 лучших фильмов с рейтингом пользователя.
Этот словарь используется в качестве входных данных для модели постера фильма.
Модель Постеров Фильмов
Цель модели постеров с фильмами - расширить словарь из входного запроса путем прогнозирования оценок, которые пользователи будут давать фильмам, аналогичным тем, которые уже находятся во входном запросе. Эта модель измеряет сходство между разными фильмами на основе сходства в афише фильма. Мы исходим из предположения, что если фильм A и фильм B имеют похожие плакаты, и пользователь уже оценил фильм A со значением 3,0, то у пользователя, скорее всего, будет аналогичный уровень возбуждения или интереса к фильму B (таким образом, в результате фильм B также получил оценку 3,0).
Модель
Первым шагом, который мы сделали для создания этой модели, является получение более 1600 изображений постеров из набора данных 100K. Таким образом, мы создали массивы на основе numpy, кодирующие каждое изображение. Одна из проблем, с которой мы сталкиваемся при выполнении этой конкретной задачи, заключается в том, что не все изображения можно было загрузить по ссылкам, указанным в наборе данных.
Чтобы обойти эту проблему, эта модель будет игнорировать любой фильм из пользовательского запроса, для которого не удалось загрузить плакат. В ходе дальнейшей работы над этим проектом мы можем добавить наши собственные изображения в набор данных для тех фильмов, плакаты которых не были загружены.
Чтобы найти сходство между афишами фильмов, мы использовали метод обучения без учителя.
Нашим первым шагом было обучение CNN VGG19. VGG19 - это CNN с 19 сверточными слоями 3x3, что позволяет использовать веса из набора данных ImageNet для классификации входных изображений по различным категориям. Причина, по которой мы решили использовать VGG19 CNN, заключается в том, что она предварительно обучена из набора данных ImageNet; в результате нам не нужно будет проводить какое-либо дополнительное обучение, чтобы найти веса, необходимые для сети.
Перед загрузкой наших изображений в модель VGG19 мы предварительно обработали массивы numpy для каждой кодировки плаката с помощью функции «applications.vgg19.preprocess_input ()». Цель этой предварительной обработки была объяснена в разделе «Предварительная обработка: набор данных для плакатов фильмов» выше.
Чтобы лучше адаптировать модель VGG19 для классификации наших изображений, было важно удалить несколько последних слоев свертки. Это гарантирует, что модель не станет слишком конкретной при классификации изображений - в противном случае модель попытается предсказать фактические объекты в изображениях плакатов. Удаляем последний слой, установив гиперпараметр index_true = false.
Вывод прогнозов рейтингов и подобных плакатов
После создания списка функций с использованием предварительно обученной модели VGG19 для прогнозирования кодировок изображений будет использоваться модель KNN для создания 6 ближайших соседей к определенному плакату фильма. Другими словами, для определенного плаката A модель KNN будет использовать классификации из CNN, чтобы найти 6 плакатов, наиболее похожих на плакат A.
Для нашей модели KNN мы использовали неконтролируемого ученика NearestNeighbors для sklearn. Функция NearestNeighbors была особенно полезной, потому что она не только предоставляла данные о ближайших соседях для каждого запроса, но также и расстояния между запросом и каждым из этих чисел.
Например, одна из наших моделей создала 6 соседей для плаката «История игрушек». Плакаты, которые модель считает наиболее близкими к плакату Истории игрушек, следующие:
Кроме того, есть идентификаторы фильмов для соседних плакатов:
Наконец, вот рассчитанные KNN расстояния между плакатом Истории игрушек и плакатами соседей, а также среднее значение всех расстояний:
Если бы фильм «История игрушек» находился в кадре данных пользовательского запроса, соседние фильмы, показанные на изображении выше, также были бы добавлены в этот фрейм данных (и каждому из них был бы присвоен такой же рейтинг, что и «История игрушек»).
Оптимизация модели и показателей
Однако нам необходимо оптимизировать модель VGG19, чтобы KNN генерировал ближайших возможных соседей для всех плакатов. Метрика, которую мы будем использовать для оптимизации, - это среднее расстояние между заданным постером и всеми его соседями (т.е. среднее расстояние для приведенного выше примера Истории игрушек составляет 2,8401613235473633e-05). Найдя модель, которая дает самые низкие средние расстояния для всех плакатов, мы сможем сгенерировать ближайших возможных соседей для каждого плаката.
Одним из параметров, которые мы настроили для модели VGG19, был параметр «объединения». Параметры объединения принимают такие входные данные, как «max», «avg» и «none» для определения поведения во время уровней maxpool в CNN.
Когда для объединения было установлено значение «Нет», средние расстояния от соседей для первых 100 плакатов были следующими:
Когда объединение было установлено на среднее значение, среднее расстояние от соседей для первых 100 плакатов было следующим:
Когда объединение было установлено на максимальное, среднее расстояние от соседей для первых 100 плакатов было следующим:
Как видно из приведенных выше 3 моделей, VGG19 обычно дает наименьшее расстояние между плакатом и его соседями, когда для объединения установлено значение avg.
В конечном итоге модель VGG19, а также модель KNN были закодированы следующим образом:
После вычисления соседей для каждого из фильмов в пользовательском запросе мы добавляем эти фильмы в фрейм данных оценок, который будет использоваться на следующем шаге, в модели матричной факторизации.Более подробную информацию о том, что именно добавлено, можно найти в примере, который мы рассмотрим позже в статье.
Матричная модель факторизации
Теперь мы используем модель матричной факторизации для вывода окончательных рекомендаций по фильму для нашего пользователя. Для этого мы добавляем нашего тестового пользователя (с дополнительными данными из модели постеров к фильмам) в рейтинги, полученные от MovieLens.
Модель
Давайте посмотрим на реальную модель. Во-первых, мы должны сформулировать проблему так, чтобы ее понимал алгоритм матричной факторизации.
Мы строим матрицу рейтингов R так, что Rij - это рейтинг, который пользователь i оценил фильму j. У нас будет много нулей в матрице, поскольку многие пары (пользователь, фильм) не имеют оценок.
Затем нам нужно будет построить матрицы, в которые будет факторизован R. Одна из матриц будет матрицей вложения пользователя U, а другая - матрицей вложения фильма M.
Строка i матрицы внедрения пользователя представляет наше представление пользователя i в виде 50-мерного вектора (поскольку мы выбрали размер внедрения 50). Мы хотим построить матрицы встраивания пользователя и фильма, которые делают U * Mᵀ приближенным к R во всех местах, где R имеет ненулевое значение. Причина, по которой такая разбивка проблемы жизненно важна для построения нашей системы рекомендаций, заключается в том, что если 2 пользователя очень одинаково оценивают фильмы, их векторы внедрения пользователей обучаются быть очень похожими друг на друга. Модель поощряется к этому (и, конечно, точно фиксирует значения рейтинга), чтобы уменьшить ошибку. Это также причина, по которой мы попросили пользователей оценить 15 самых популярных фильмов из набора данных Movielens. Это позволяет нашему тестирующему пользователю взаимодействовать с максимально возможным количеством других пользователей и, таким образом, позволяет тестирующему пользователю эффективно «контролировать» пользовательские встраивания.
Ниже приведен фрагмент кода для обучения модели матричной факторизации:
Метрики
Мы использовали среднеквадратичную ошибку, агрегированную по всем ненулевым значениям матрицы рейтингов (R-U * Mᵀ). Вот упрощенная формула MSE, используемая в качестве потерь для нашего обучения:
Ниже приведен график ошибок обучения в зависимости от номера итерации:
На этом этапе мы используем метрику, известную как косинусное расстояние, чтобы отсортировать пользователей по тому, насколько они похожи на нашего тестового пользователя. Мы могли бы давать рекомендации пользователю на основе фильмов, которые понравились похожим пользователям.
Включение извлеченных данных
Однако мы также хотели включить информацию о жанрах. Это побудило нас использовать рейтинги IMDB, которые мы собрали ранее. Мы решили использовать оценку аудитории IMDB, потому что она отражает то, насколько среднестатистическому человеку понравился конкретный фильм, в большей степени, чем усреднение данных MovieLens, потому что IMDB основан на более проверенных рейтингах.
Во-первых, нам нужно убедиться, что рейтинги IMDB могут относительно хорошо разделять наши рейтинги пользователей. Ниже приводится график процентной доли случаев, когда пользователь оценивает фильм выше, чем рейтинг IMDB для этого фильма по жанрам:
Это показывает, что большинство жанров очень близко к 50%, поэтому, если пользователь постоянно оценивает фильмы определенного жанра ниже рейтинга аудитории IMDB, это статистически значимо (т. Е. Рейтинги IMDB не просто завышены или занижены при сравнении их с рейтингом аудитории IMDB. набор данных MovieLens).
Рекомендации
Наконец, пора дать рекомендации! Чтобы делать хорошие прогнозы, мы используем двоякий подход, который использует все, что мы описали ранее:
- Сортировать пользователей по сходству с тестовым пользователем и
- Выберите фильмы в жанре, которые понравились нашему пользователю, а другому не нравится, но фильм в нем все равно нравится.
Во-первых, мы сортируем всех пользователей в порядке убывания в соответствии с косинусным «расстоянием» (то есть в порядке сходства с нашим тестовым пользователем).
Затем, по порядку, мы проверяем, кому из этих пользователей не нравится один из 3 жанров, которые нравятся нашему пользователю. Мы делаем это, проверяя, оценивают ли они фильмы определенного жанра ниже рейтинга IMDB в 70% случаев. Мы рассматриваем пользователя этого жанра только в том случае, если он оценил более 25 фильмов в нем, чтобы исключить шум.
Наконец, мы произвольно выбираем из всех фильмов этого жанра, которым этот пользователь присвоил рейтинг 5.0, и добавляем фильм в наш рекомендуемый список. Мы повторяем это, пока у нас не будет 10 новых фильмов, которые мы можем порекомендовать нашему пользователю.
Вуаля! Теперь пользователь может наслаждаться фильмами по своему вкусу. Заполнить форму Google, чтобы получить эти рекомендации, намного быстрее, чем попробовать все 1682 фильма самостоятельно!
Рассмотрение примера
Теперь мы продемонстрируем конкретный пример всей нашей системы рекомендаций.
Входной запрос
Мы собираем оценки пользователей по 15 лучшим фильмам из набора данных и экспортируем результаты в файл .csv:
Преобразуя эту информацию в фрейм данных, мы получаем:
Как видите, этот пользователь ввода предпочитает фильмы для младшего поколения, что отражено в трех его самых любимых жанрах: анимация, детская и мюзиклы. Отсюда мы обрабатываем информацию и отправляем ее макету постеров фильмов.
Модель Постеров Фильмов
Вот как выглядит фреймворк рейтингов при вводе в модель:
Затем модель находит ближайших соседей для каждого из этих 14 фильмов и добавляет эти фильмы в фрейм данных рейтинга.
Вот ближайшие соседи, найденные для некоторых из фильмов выше:
Крестный отец не был включен, потому что его плакат не удалось получить из базы данных плакатов.
Соседи для всех плакатов будут добавлены во фрейм данных с одинаковыми рейтингами. Таким образом, все соседи для «Истории игрушек» будут добавлены с рейтингом «5», все соседи для «Двенадцати обезьян» будут добавлены с рейтингом «2» и т. Д.
Вот как выглядела часть фрейма рейтингов после запуска этой модели:
Как мы видим, постеры фильмов значительно увеличивают объем информации, которая вводится в модель матричной факторизации, позволяя конечному результату быть более точным для пользователя. Этот новый фрейм данных рейтингов теперь будет отправлен в качестве входных данных в матричную модель факторизации.
Матричная модель факторизации
Теперь мы готовы взглянуть на окончательные результаты рекомендаций.
Ранее мы обсуждали, что один из способов - просто отсортировать пользователей по сходству с нашим тестовым пользователем и выбрать их любимые фильмы в жанре, в котором они представлены. Использование этой техники дает следующие рекомендации для нашего тестового пользователя:
Другой метод, описанный ранее, заключается в сортировке пользователей по сходству с нашим тестовым пользователем, НО также выбирайте фильм только от одного из похожих пользователей, только если им не нравится один из жанров, который нравится нашему пользователю. Это то, что мы использовали в качестве нашей окончательной модели. Использование этой техники дало следующие альтернативные рекомендации:
Мы думаем, что последний метод - лучший и более надежный способ делать прогнозы. Однако мы не можем точно знать, соответствует ли этот метод предпочтениям пользователей, к сожалению, потому что у нас нет доступа к пользовательским оценкам фильмов, которые мы им рекомендуем.
В конце концов, комбинация двух наших моделей дала удовлетворительные рекомендации, поскольку они совпадали с исходным вводом тестового пользователя в пользу детских, анимационных и музыкальных фильмов.
Идеи, которые не сработали
Вначале мы опробовали несколько идей, но, к сожалению, не дали удовлетворительных результатов.
Классификатор XGBoost
Поскольку модель матричной факторизации игнорирует демографическую информацию, связанную с пользователем, мы попытались создать классификатор XGBoost, чтобы использовать эти данные после того, как данные стали категориальными. Мы попытались включить данные, создав динамическую модель XGBoost на основе рекомендаций, сделанных моделью матричной факторизации.
Для каждого фильма из нашего окончательного результата была реализована модель XGBoost путем создания обучающих данных от всех пользователей, оценивавших этот фильм. Целевая переменная была 0, если пользователю не понравился фильм, и 1, если он им понравился. Мы выбрали рейтинг от 4 и выше, чтобы показать, что им нравится.
Идея заключалась в том, что если мы получим 5 фильмов, рекомендуемых в соответствии с моделью матричной факторизации, мы создадим и обучим классификатор XGBoost для каждого из фильмов. Затем мы проверим мягкую вероятность выхода каждой из 5 моделей при вводе демографической информации нашего тестового пользователя, представляющей вероятность того, что кому-то с демографическим прошлым тестового пользователя понравится этот фильм.
Эта идея не оправдалась с тех пор:
- Либо в нашем наборе данных не было достаточно данных для каждого отдельного фильма, чтобы создать хорошую модель, либо
- Демографические данные не могут точно предсказать вкус пользователя к фильмам. Это привело к тому, что мы получили результаты модели, которые были не намного лучше, чем случайное предположение (в некоторых случаях это было хуже, с тестовыми данными AUC ниже 0,5).
Ниже приведен сюжет попытки запустить классификатор XGBoost для самого популярного фильма в наборе данных MovieLens (История игрушек). Он показывает, что AUC представляет модель, очень близкую к случайному угадыванию, поэтому ее использование не имеет особого смысла:
Softmax нейронная сеть
Для второй модели, которая теперь достигается с помощью матричной факторизации, мы изначально пытались реализовать нейронную сеть с softmax в качестве финального уровня активации, на что мы потратили большую часть нашего времени в начале. Это было связано с тем, что это позволило нам выработать рекомендации по более личным факторам, таким как род занятий, возраст и другая возможная информация, которую мы хотели изучить.
Эта модель попыталась предсказать рейтинги фильмов для входящего пользователя для фильмов, которые он еще не оценил. Следовательно, входными данными для модели являются пользователь и фильм, и она будет пытаться предсказать оценку, которую пользователь поставит этому фильму. Чтобы использовать softmax, мы преобразовали модель в мультиклассовую классификацию путем быстрого кодирования рейтингов в пять классов, каждый из которых представляет свой рейтинг: 1, 2, 3, 4, 5.
Затем модель выведет вектор из 5 чисел, каждый элемент которого соответствует классам рейтингов по порядку.Ниже приведен пример прогнозируемого рейтинга для пользователя 942 для случайного ввода фильма. Здесь модель предсказала, что пользователь 942, скорее всего, оценил бы этот фильм на 5.
Чтобы представить каждого пользователя и фильм во встраиваемых слоях, мы установили количество факторов равным 50. Мы использовали Keras для построения нашей нейронной сети, используя следующие слои:
- Input (shape = 1) с учетом количества пользовательских входов, равного 1
- Input (shape = 1) с учетом количества входов фильма, равного 1
- Встраивание (input_dim = number_of_users), создание слоя внедрения для всех пользователей, найденных в наборе данных MovieLens, и входящего пользователя
- Встраивание (input_dim = number_of_movies), создание слоя внедрения для всех фильмов, найденных в наборе данных MovieLens.
- Два слоя Reshape () для преобразования в векторы из 50 произвольных чисел
- Два слоя Dropout (0,5) для каждого слоя встраивания для предотвращения переобучения
- Concatenate (user_embedding, movie_embedding) для объединения двух слоев внедрения
- Снова выпадение (0,5) во избежание переобучения
- Плотный (активация = relu)
- Снова выпадение (0,5) во избежание переобучения
- Плотный (активация = softmax), чтобы сделать окончательный выходной слой
В этой модели использовалась категориальная перекрестная энтропия в качестве потерь при обучении и проверке, а в качестве метрики - точность. После подгонки мы получили следующие результаты:
Эта модель дала несколько многообещающих результатов. Как видите, потери на обучение и проверку имели тенденцию к снижению:
И точность улучшалась с каждой эпохой:
Однако потери были очень высокими, и нам не удалось повысить точность выше 0,45. Фактические прогнозы, сделанные с использованием модели, были значительно далеки, поскольку мы создавали пользовательский запрос, который отдавал предпочтение детским фильмам, но он выводил бы драмы как фильмы с самым высоким рейтингом. Мы пробовали и другие уровни, такие как слой Dot () вместо Concatenation () и сигмоид в качестве последнего слоя активации вместо softmax, но эти попытки, опробованные с настройкой гиперпараметров, оказались безрезультатными. Поэтому мы решили сосредоточиться на факторизации матрицы.
Слои модели VGG19 (постеры с фильмами)
Для модели VGG19 мы попытались удалить из сети определенные слои. Для этого мы реализовали модель Sequential () и после обучения модели VGG19 со всеми 19 слоями добавили определенные выбранные слои в модель Sequential (). Это было частью попытки увидеть, может ли удаление слоев сделать модель более точной для поиска ближайших соседей. К сожалению, однако, это не показало последовательного улучшения расстояния между запросами и соседями, поэтому идея удаления слоев из CNN была отброшена.
Вывод
В целом окончательная модель, сочетающая VGG19 и матричную факторизацию, оказалась успешной. Мы смогли взять совершенно другую информацию из фильмов, такую как плакат и жанр, и использовать рейтинги из ранее просмотренных фильмов и других пользователей, чтобы создать правильную систему рекомендаций. Надеемся, вам понравилось читать о нашем проекте!
Этот проект был выполнен в рамках заключительного проекта нашего класса по науке о данных в Техасском университете в Остине.