Созданная Google библиотека машинного обучения TensorFlow в настоящее время занимает доминирующее положение на рынке. Однако в ее основе лежат специфические особенности, о которых следует знать, чтобы облегчить процесс ознакомления с этим инструментом и избавить себя от проблем в будущем.

Так, можно выделить два режима работы с библиотекой: декларативный и императивный, которые отличаются отложенным или немедленным проведением вычислений. До последнего времени в TensorFlow использовался декларативный режим. Его особенностью является сначала описание структур и всех действий с ними (под капотом создается граф вычислений), а затем проведение операций в рамках инициализируемых для этого сессий. Это позволяет TensorFlow масштабировать вычисления, в частности, гибко определять устройства для их осуществления (компьютеры, CPU, GPU).
Соответственно, из-за этой особенности отладка программ, например, определение результатов операций, содержимого переменных затруднялась, что в целом создавало большие сложности разработчикам при работе с инструментом.
В этих условиях создатели TensorFlow со второй версии библиотеки существенно поменяли концепцию работы с ней и решили отойти от декларативного к императивному стилю. Поэтому по умолчанию для работы включен режим eager execution, который позволяет выполнять операции немедленно, без построения графа. Вместе с тем, учитывая преимущества декларативного стиля работы в плане масштабирования, он также используется, однако с рядом нововведений. В целом рекомендуется смешанное программирование - императивное с декларативными вставками в местах с большим количеством операций.
Рассмотрим примеры. Выведем для TensorFlow старой версии содержание матрицы (2,2) нормально распределенных случайных значений со средним 1 и стандартным отклонением 0.5, а также матрицы, полученной добавлением к каждому элементу значения 5. Для этого напишем следующий скрипт:
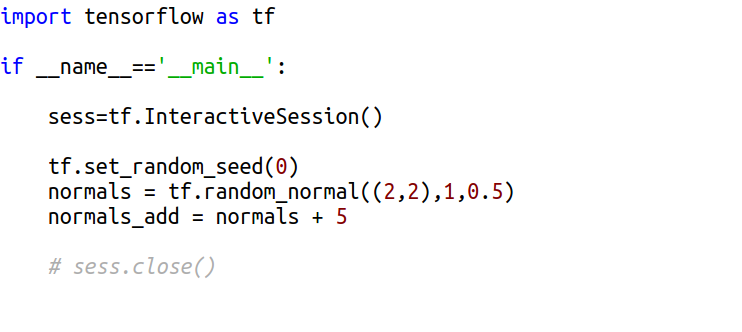
Обратите внимание на вывод:
При выводе значений normals и normals_add по отдельности, одно из другого операцией прибавления 5 к каждому элементу не получается, чего не скажешь о последнем вызове. Это обусловлено как раз природой декларативных вычислений. На первом этапе сформировался граф с узлами, включающими normals и normals_add. Каждый раз при принудительном выполнении операции sess.run подсчитывается значение только заданного в аргументе узла/узлов. Однако наряду с этим вычисляются значения узлов, от которых зависит значение искомого. Соответственно, при вызове sess.run(normals_add) вновь подсчитывает значение normals (уже другое, нежели в строке 46). Зависимость между значениями прослеживается только при одновременном вычислении в графе (последний случай).
А теперь рассмотрим проведение тех же манипуляций в новой версии TensorFlow:
Для вывода значений сессию создавать не понадобится (в первом случае это бы вызвало ошибку). Кроме того, также не создается граф вычислений, что заметно по корреляции независимого вывода содержания двух матриц.
Обратите также внимание на миграцию функции нормального распределения в новый модуль. В целом вторая версия TensorFlow имеет и другие принципиальные различия.
А с какими неожиданностями при переходе от одной версии TensorFlow к другой столкнулись вы?