Расширьте встроенную функциональность с помощью собственных инструментов предварительной обработки, совместимых с конвейером
Все мы знаем, как важна предварительная обработка в проекте машинного обучения. Обычно имеет смысл обрабатывать некоторые недостающие значения, масштабировать различные функции, быстро кодировать другие и т. Д., А в scikit-learn есть готовые инструменты, которые отлично справляются со всеми этими шагами прямо из коробки. Но как насчет добавления новых функций или применения пользовательского преобразования? Знаете ли вы, что scikit-learn также позволяет легко встроить эти шаги в стандартный рабочий процесс ? Вот как!
Функция Трансформатор
Давайте начнем с простого с отличного инструмента для преобразования на лету: FunctionTransformer.FunctionTransformer может использоваться для всего, от применения предопределенной функции к функции до выбора определенных столбцов в наборе функций. Основная идея состоит в том, что FunctionTransformer принимает функцию (вы также можете передать обратную функцию) и применяет функцию к данным с помощью метода fit_transform. Это делает его отличным инструментом для несложных преобразований, которые можно заключить в простую функцию; вы можете почти думать об этом как о «лямбда-функции» предварительной обработки scikit-learn. Ниже мы демонстрируем несколько вариантов использования.
Выбор функций:
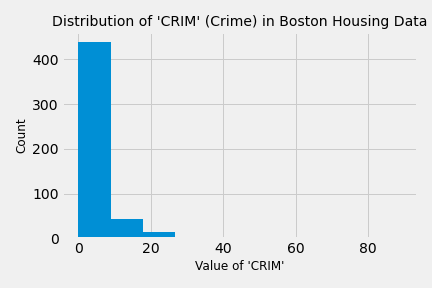
Здесь мы используем FunctionTransformer, чтобы выбрать две из тринадцати функций в полном наборе данных Boston Housing.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import FunctionTransformer
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_boston
def select_crime_and_taxes(X):
""" Custom selector for the Boston Housing dataset
Accepts X, array of 13 features described in sklearn.datasets.load_boston
Returns only the columns of X corresponding to the features 'CRIM':
per capita crime rate, and 'TAX': full-value property-tax rate per $10,000"""
# select columns in positions 0 and 9, drop remaining columns
return X[:, [0,9]]
crime_and_taxes_pipe = Pipeline(
[('feature_selector', FunctionTransformer(select_crime_and_taxes))]
)
if __name__ == "__main__":
X, y = load_boston(return_X_y=True)
feature_names = load_boston()['feature_names']
crime_and_tax_features = crime_and_taxes_pipe.fit_transform(X)
# Raise an assertion error if our feature selector didn't work
assert np.all(load_boston()['feature_names'][[0,9]] == [
'CRIM', 'TAX']), 'Feature selection failed'
plt.style.use('fivethirtyeight')
plt.hist(crime_and_taxes_pipe.fit_transform(X)[:,0])
plt.title("Distribution of 'CRIM' (Crime) in Boston Housing Data",fontsize=14)
plt.xlabel("Value of 'CRIM'", fontsize=12)
plt.ylabel('Count', fontsize=12)
plt.tight_layout()
plt.savefig('./crime_distribution.png');
Простые преобразования:
Мы смогли выбрать нужные функции, но, возможно, мы хотели бы масштабировать значения функции CRIM (уровень преступности). Мы могли бы использовать StandardScaler, но вместо этого мы применим другую фичу , чтобы продемонстрировать, как использовать FunctionTransformer для применения простых функций на лету.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import FunctionTransformer
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_boston
def select_crime_and_taxes(X):
""" Custom selector for the Boston Housing dataset
Accepts X, array of 13 features described in sklearn.datasets.load_boston
Returns only the columns of X corresponding to the features 'CRIM': per capita crime rate, and 'TAX': full-value property-tax rate per $10,000"""
# select columns in positions 0 and 9, drop remaining columns
return X[:, [0, 9]]
# we add a simple log scaling transformation
crime_and_taxes_pipe = Pipeline(
[('feature_selector', FunctionTransformer(select_crime_and_taxes)),
('log_scaler', FunctionTransformer(np.log))]
)
if __name__ == "__main__":
X, y = load_boston(return_X_y=True)
feature_names = load_boston()['feature_names']
crime_and_tax_features = crime_and_taxes_pipe.fit_transform(X)
assert np.all(load_boston()['feature_names'][[0, 9]] == [
'CRIM', 'TAX']), 'Feature selection failed'
plt.style.use('fivethirtyeight')
plt.hist(crime_and_tax_features[:, 0])
plt.title("Distribution of Crime Rate after Log Scaling",
fontsize=14)
plt.xlabel("Value of 'CRIM'", fontsize=12)
plt.ylabel('Count', fontsize=12)
plt.tight_layout()
plt.show()
Полностью настраиваемые оценки
Что, если вы хотите расширить эту базовую функциональность за счет более сложных преобразований? Разработать новые функции? Добавить несколько гиперпараметров, чтобы упростить поиск по данным? Scikit-learn поможет вам здесь, и у нас есть для вас пример ниже.
Прежде чем мы начнем, мы должны отметить, что хотя документация в целом является хорошей отправной точкой для любого пакета, scikit-learn особенно известен тем, что имеет исключительно хорошую документацию. Объекты Scikit-learn («оценщики», на языке sklearn) имеют некоторые общие структуры, и рекомендуется следовать им, чтобы они хорошо взаимодействовали с другими концепциями стиля конвейера. С этой целью scikit-learn предоставляет несколько инструментов для простой реализации этих функций совместимым способом, и вы можете узнать больше о том, почему мы их используем, в приведенном ниже коде. Этот набор данных представляет собой набор данных King County Housing,
И без лишних слов, вот код:
import pandas as pd
import numpy as np
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils.validation import check_X_y, check_is_fitted
kc_data = pd.read_csv('./data/kc_house_data.csv')
X, y = kc_data.drop(['price', 'date'], axis=1).values, kc_data['price'].values
# specifying the indices for the columns we'll use below
sqft_living_ind, sqft_living15_ind, bedrooms_ind = 3, 17, 1
# add attributes, a custom sklearn transformer needs init, fit, and transform methods
# fit_transform is created by adding TransformerMixin and BaseEstimator gives get/
# set_params(), passing each new feature as a hyperparameter allows to gridsearch which ones
# are effective
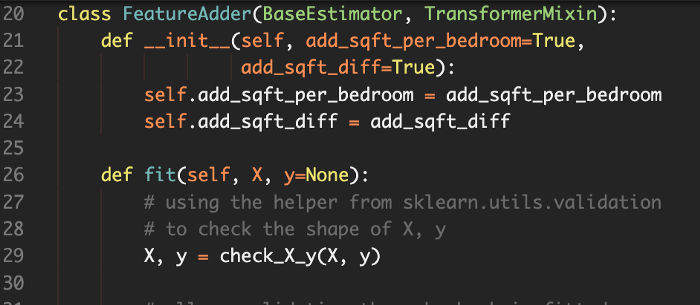
class FeatureAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_sqft_per_bedroom=True,
add_sqft_diff=True):
self.add_sqft_per_bedroom = add_sqft_per_bedroom
self.add_sqft_diff = add_sqft_diff
def fit(self, X, y=None):
# using the helper from sklearn.utils.validation
# to check the shape of X, y
X, y = check_X_y(X, y)
# allows validation through check_is_fitted
# from sklearn project template example
self.n_features_ = X.shape[1]
return self
def transform(self, X, y=None):
check_is_fitted(self, 'n_features_')
# Check input shape, also from sklearn project template
if X.shape[1] != self.n_features_:
raise ValueError('Shape of input is different from what was seen'
'in `fit`')
if self.add_sqft_per_bedroom:
# avoid divide by zero error:
with np.errstate(divide='ignore', invalid='ignore'):
sqft_per_bedroom = np.true_divide(
X[:, sqft_living_ind], X[:, bedrooms_ind])
sqft_per_bedroom[~np.isfinite(
sqft_per_bedroom)] = 0
if self.add_sqft_diff:
sqft_diff = X[:, sqft_living_ind] - X[:, sqft_living15_ind]
if self.add_sqft_per_bedroom and self.add_sqft_diff:
X = np.c_[X, sqft_per_bedroom, sqft_diff]
elif self.add_sqft_per_bedroom:
X = np.c_[X, sqft_per_bedroom]
elif self.add_sqft_diff:
X = np.c_[X, sqft_diff]
return X
Градиентный спуск для линейной регрессии с нуля
Numpy реализация градиентного спуска
Наша функция стоимости - это остаточная сумма квадратов (RSS). Ее можно немного изменить на среднеквадратичные ошибки (MSE), путем деления на количество экземпляров в наборе (поскольку это константа, это не изменит вычисления ниже). Напоминаем, что с помощью матрицы признаков X и целевого вектора y это уравнение можно записать следующим образом:
Сначала мы выбираем случайный вектор коэффициентов тета и берём частную производную нашей функции затрат (часто обозначаемой буквой «J», мы сохраняем здесь RSS для ясности) по каждому значению тета.Результирующий вектор называется «вектором градиента», поскольку он содержит значение уклонов или «градиентов», измеренных в каждом измерении. …
Как кодировать линейную регрессию с нуля
Простая реализация, основанная на нормальном уравнении
В наши дни легко совместить практически любую модель, которую вы только можете придумать, с той или иной библиотекой, но сколько вы действительно узнаете, вызывая .fit () и .predict ()? Хотя, безусловно, гораздо практичнее использовать фреймворк, такой как statsmodels python или scikit-learn, для нормального сценария использования, в равной степени логично, что при изучении науки о данных имеет смысл понять, как эти модели на самом деле работают. Ниже мы покажем, как использовать numpy для реализации базовой модели линейной регрессии с нуля. Давайте начнем!
Все дело в коэффициентах
Вспомните свой первый урок алгебры: вы помните уравнение для прямой? Если вы сказали «y = mx + b», вы абсолютно правы. Я думаю, что также полезно начать с двух измерений, потому что без использования каких-либо матриц или векторов мы уже можем видеть, что при заданных входах x и выходах y мы на самом деле ищем не один, а два коэффициента: m и b. …
Решение проблем проекта Эйлера в Python - Введение и задачи 1–3
Если вы только начинаете программировать, возможно, вы не слышали о Project Euler. Если нет, сначала проверьте это! Вы обнаружите, что это классная серия задач, сочетающих математику и информатику. На веб-сайте предполагаемая аудитория указана как:
«Учащиеся, для которых базовая учебная программа не утоляет их жажду учиться, взрослые, чье образование не связано в первую очередь с математикой, но интересовалось математикой, и профессионалы, которые хотят, чтобы их решение задач и математика оставались на переднем крае».
Я также добавлю два условия, чтобы сформировать целевую аудиторию для этого ...
Поиск дзен со сводными таблицами в pandas
Сводные таблицы немного похожи на Vim. (Нет, подождите, не уходите! Они намного проще!) Сводные таблицы похожи на Vim в том смысле, что вы, вероятно, знаете, что они являются довольно мощным инструментом, но синтаксис сначала немного сбивает с толку, и если вы вечно использовал groupby, тогда знаешь, в чем смысл? Опытные пользователи Vim скажут вам с не столь пограничным евангельским рвением, что преимущество Vim в том, что вы можете редактировать с той скоростью, с которой вы думаете, действительно становясь единым целым с вашим кодом. Что ж, сводные таблицы очень похожи на данные. Сам по себе глагол groupby удобен, потому что его очень легко понять, он очень похож на использование клавиш со стрелками для навигации по клавиатуре (стрелка вверх идет, ммм…). Если вы группируете только по одному признаку, сгруппировать проще, но если вы хотите знать свои данные как себя, пора научиться поворачивать. …