В этой статье я расскажу о том, как разбивать данные по пакетам. Приводимые в качестве примеров методы работают с типом данных tf.data.Dataset (tf - псевдоним TensorFlow), о котором я рассказывал ранее.
На первом этапе нужно определиться с размерностью данных в пакетах. Если они имеют фиксированную форму, то разумно использовать метод batch, если требуется выравнивание - padded_batch.
Batch
Метод batch позволяет сформировать из Dataset пакеты заданной длины. При этом его параметр drop_remainder определяет, будет ли неполный пакет (если количество элементов нацело не делится на размер пакета) в составе итогового набора или нет. Зададим Dataset из последовательности целых чисел и разобьем на пакеты:
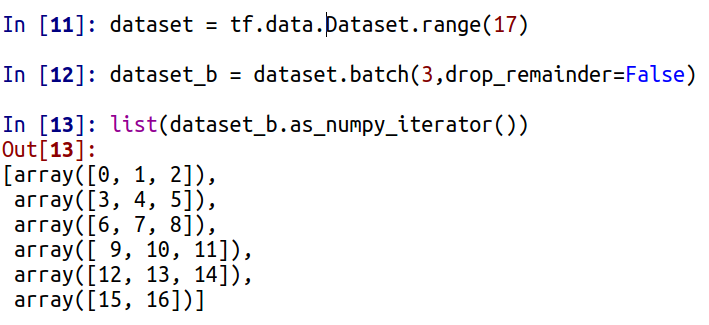
Обратите внимание, что во втором случае отсутствует последний неполный пакет.
С помощью метода Dataset zip можно организовать формирование пакетов заданной длины одновременно из нескольких наборов данных:
Padded_batch
В отличие от метода batch в padded_batch элементы не обязательно должны иметь одинаковую форму. Padded_batch позволяет устанавливать разные отступы для каждого измерения каждого компонента, и они могут быть переменной (обозначается None) или постоянной длины. Также существует возможность изменения значения заполнителя, которое по умолчанию равно 0.
Создадим Dataset из элементов разной формы:
В примере функция tf.fill создает тензор заданной размерности и заполняет его заданным значением. А метод map применяет анонимную функцию к каждому элементу Dataset.
Теперь разделим набор на пакеты:
По умолчанию форма элементов в пакете дополняется до максимального размера входящих элементов. Но можно ее и зафиксировать (однако каждое измерение не должно быть меньше, чем такое же измерение какого-либо из элементов, в нашем случае - длина не менее 4):
И если задаем длину меньше 4:
.....
Если хотим дополнять не символом "0", а каким-то определенным значением, то его можно задать в аргументе padding_values:



















